虚拟机设置静态ip
https://wangyi.one/vmware%E4%B8%AD%E9%85%8D%E7%BD%AEubuntu%E9%9D%99%E6%80%81ip/Emacs后续学习
常用键位
替换 : %s/原/修改之后的/g g代表修改整个文件
查找 : 使用 n 查找下一个, N 下一个
: 首行,尾行 s/原/新/g
: .,+ns/旧/新/g 当前行和接下来的n行
. 重复之前的操作 ###
快捷键之类的,大部分都是可以组合使用的
键位练习:命令行输入 vimtutor #####
COMMAND模式
:set ic / noic 查找时不/区分大小写
使用v选中之后使用:
会看见'<'>之后可以通过 w + filename 将选中的字保存为新的文件
:! + shell 命令,在不退出vim的情况下使用shell指令 ######
:! + sh 再开一终端,暂时退出当前文件的页面,使用ctrl- d返回文件 #########
:r + filename 将filename文件中的文字写入当前光标所在位置
:set number 显示行号
:s/old/new/g 替换一行中的old为new,加上g会对整行都起作用,不加g只会修改第一个old
:sp 打开当前文件打开多个窗口
:qa 关闭所有窗口
normal模式
A append 移动到末尾进行insert ###
I 移动到这一行的开头进行insert ###
J 将下一行和这一行连接在一起
a 光标之后插入内容
ctrl + r redo
u 撤销
hjkl 左下上右
v 进入选中块模式
V 选中模式,每次选中一行
ctrl + w 切换window
ctrl + v 选中一个矩形
~ 选中之后,使得大小写互换 ###
f + 要查找的字符 find 这一行中光标之后第一个关键字
F + xxx find 反向查找
t + xxx 移动到这个字符的前面一个字符
T + xxx 反向查找,移动到字符之后一个字符
d + 移动的键位 删除 d + $ 删除到(一行)结尾, d + 0 删除到(一行)开头
c + 移动的键位 change 删除并进入insert进行修改
dd 删除一行
cc 删除一行并进入insert
x 删除当前字符
r + 字符 替换当前一个字符
R 连续替换 ###
w word 向后移动一个单词
b 向前移动一个单词
e end 移动到下一个单词的最后一个字母
o 下方开一个新行
O 上方开一个新行
0 移动到行首
% 从{/[/( 移动到)/]/}
$ 移动到行末
数字 + G 跳转到指定行
ctrl + g 显示当前的行数
G 最后一行
gg 第一行
y + 移动的键位 复制
yy 复制一行
p 粘贴
L/M/H 当前页面的lowest/middle/highest
ctrl + u / d 向上滚动/向下滚动
数字 + 键位 执行几次这个键位操作
例如:
7dw 删除七个单词
修饰词
a 删除所在的整体
例如:
{djsafljaflsjlf}123
使用di{
只剩下了
123F
i 内部,例如
{skdajsldjas}想要删除{}内的东西只需要
ci{
/ + 内容 全文查找
- 好用的操作
- 一键取消注释,ctrl + v进入块选择模式,然后使用方向键选择所有的注释,按d删除即可
Git
切换分支和版本号实际上就是指针的切换
工作区:磁盘目录
使用git add把工作区代码加入暂存区 临时储存
git commit
将暂存区代码提交到本地库,得到历史版本(代码删除不了了)
push
推送到远程库
github是远程库
git init 初始化仓库
git status 查看仓库状态
##Untracked files: 是未追踪的文件,也就是文件只处于工作区,不处于暂存区和本地库,红色的文字
##绿色的文件名是存在于暂存区
git add + filename 添加到暂存区
git add -A 全部提交
git add -i 添加到暂存区,但是会有提问
git rm --cached filename 删除暂存区的文件
git commit -m "日志信息" filenaem 提交到本地库
git commit --amend + 日志 #覆盖最新的一次提交日志
##提交之后git status 会显示为没有提交
git reflog 查看提交记录
git log 查看日志,包括提交记录和提交用户
git log --author=xxx 只查看某人的提交记录
git log --pretty=oneline 每一个提交记录只占一行
git log --graph --oneline --decorate --all 通过 ASCII 艺术的树形结构来展示所有的分支
git log --name-status 看哪个文件改变了
-n n为数字 //最新n个提交
##版本穿越,修改HEAD指针 本地原文件一并会被修改
git reset --hard + 版本号
git tag xxx 提交ID前10个字符,创建一个标签
git cherry-pick +xx xxx xx 把某几个分支复制到当前分支上分支操作
git branch 创建分支
git branch -v 查看有哪些分支
-m 改名
-d 删除
git checkout + name 切换分支
git merge + name 将当name合并在当前分支
git reset 撤销提交记录,但是撤销之前的还是存在的,只是处于未加入缓冲区的状态,仅限本地
git revert 撤销更改分享给别人分支冲突:两个人同时对同一个内容 进行了两个不同的修改,git无法决定新的文件手
手动修改后,commit 不要再加上文件名了
HEAD指向的是当前分支
远程开发:
git remote -v 查看所有远程地址别名
git remote add 别名 + 远程地址 给远程地址起一个别名,方便切换
git push +别名/库地址 + 分支名 把这个分支推送到远程库
git pull +别名/库地址 + 分支名 把远程的分支名拉取
git clone + 库地址 克隆到本地 会进行:1.拉取代码2.初始化本地库3.创建别名
###############
git clone -b <branchname> <remote-repo-url> 克隆指定分支
###############
git fetch + xxx
git reset --hard origin/master 获取服务器上最后一次改动,并将本地主分支指向它,实现放弃本地所有改动其他知识
gitk 内建的图形化
##显示历史记录时,每个提交的信息只显示一行:
git config format.pretty oneline其他:
git count-objects -vH #查看仓库大小
git log --reverse #从旧到新查看提交记录
.gitignore配置
- 所有以#开头的行会被忽略
- 可以使用glob模式匹配
- 匹配模式后跟反斜杠(/)表示要忽略的是目录
- 如果不要忽略某模式的文件在模式前加”!”
比如:
# 此为注释 – 将被 Git 忽略
.a # 忽略所有 .a 结尾的文件
!lib.a # 但 lib.a 除外
/TODO # 仅仅忽略项目根目录下的 TODO 文件,不包括 subdir/TODO
build/ # 忽略 build/ 目录下的所有文件
doc/.txt # 会忽略 doc/notes.txt 但不包括 doc/server/arch.txt
工作中常用
git stash //将当前的工作暂存,但是不进行提交
git stash show //显示暂存的内容,哪些被修改了,可指定序号
git stash list //已经暂存的列表和序号
git stash apply + stash@{数字} //切换回来继续工作
//可以加上--index 来回到原来文件的暂存状态
git stash drop //丢弃指定的stash
git stash pop //apply + dropScoop
Scoop是一个Windows系统管理包的开源软件,相比从百度上搜索,从几十条垃圾信息中筛选出一个能用的安装链接,Scoop可以只使用一行代码进行安装
安装环境:
本人使用的是Windows11系统,已经内置PowerShell了,如果是Windows7系统,需要手动安装新版本的PowerShell
Scoop 源文件在GitHub上,推荐使用魔法
步骤:
使用快捷键win+ x 打开 Windows终端,不要打开管理员的终端
之后输入
# 设置 PowerShell 执行策略
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
# 下载安装脚本
irm get.scoop.sh -outfile 'install.ps1'
# 执行安装, --ScoopDir 参数指定 Scoop 安装路径 ' ' 内的是自定义的安装目录
.\install.ps1 -ScoopDir 'D:\Scoop'使用技巧
scoop社区维护的安装路径大部分在国外,所以下载时建议使用魔法
scoop help 命令参考说明
scoop + 动作 + 对象, 对象可以省略
scoop +
search 搜索软件名
install 安装软件
update 更新软件
status 查看软件装填
uninstall 卸载软件
info 查看软件详情
home 打开软件主页举例:
- 查看本机有无安装typora
scoop search typoraScoop下载软件的安装路径是自定义下载路径中的apps文件夹
正则表达式:
$ 匹配末尾位置
^ 匹配开头位置
* 匹配前一个字符的0次或n次 例如: zo* 会匹配z zo zoo zooo z...... 等
+ 匹配前一个字符一次或多次u zo+ 匹配 zo zoo zooo zo...... 等
? 匹配前一个字符0次或1次 zo? z zo
{n,m} 匹配 n 到 m 次
{n} n 次
? + 其他限定符,表示匹配非贪心,默认的匹配会尽力匹配较长的满足条件的字符串,使用这个后尽力匹配较短的字符串
. 匹配任意单个字符
//
(pattern) 匹配pattern 并捕获他的子表达式
(?:pattern) 不捕获子表达式
(?=pattern) 前面的字符匹配到之后,判断后面的是否能够匹配pattern 如果能那么就捕获,否则不匹配
(?!pattern) 反向捕获,不捕获包含patter的字符串
//规则集
x|y 匹配x或y
[xyz] 字符集,匹配三者的任一字符
[^xyz] 反向捕获
[a-z] 匹配a-z 中的任一字符
[^a-z] 反向匹配不包含的
//
\b border 以这个符号之前的字符(串)为边界的匹配
\B 非边界匹配
\cx x 为[a-z] 或 [A-Z] 匹配ctrl + x
\d 数字匹配,十进制[0-9]
\D [^0-9]
\f 匹配换页符
\n 换行符
\r 匹配回车
\w 匹配字类字符 [A-Za-z0-9]
\W 非字类字符
Maven
坐标
- groupId(必须): 定义了当前 Maven 项目隶属的组织或公司。groupId 一般分为多段,通常情况下,第一段为域,第二段为公司名称。域又分为 org、com、cn 等,其中 org 为非营利组织,com 为商业组织,cn 表示中国。以 apache 开源社区的 tomcat 项目为例,这个项目的 groupId 是 org.apache,它的域是 org(因为 tomcat 是非营利项目),公司名称是 apache,artifactId 是 tomcat。
- artifactId(必须):定义了当前 Maven 项目的名称,项目的唯一的标识符,对应项目根目录的名称。
- version(必须):定义了 Maven 项目当前所处版本。
- packaging(可选):定义了 Maven 项目的打包方式(比如 jar,war…),默认使用 jar。
- classifier(可选):常用于区分从同一 POM 构建的具有不同内容的构件,可以是任意的字符串,附加在版本号之后。
依赖
- dependencies:一个 pom.xml 文件中只能存在一个这样的标签,是用来管理依赖的总标签。
- dependency:包含在 dependencies 标签中,可以有多个,每一个表示项目的一个依赖。
- groupId,artifactId,version(必要):依赖的基本坐标,对于任何一个依赖来说,基本坐标是最重要的,Maven 根据坐标才能找到需要的依赖。我们在上面解释过这些元素的具体意思,这里就不重复提了。
- type(可选):依赖的类型,对应于项目坐标定义的 packaging。大部分情况下,该元素不必声明,其默认值是 jar。
- scope(可选):依赖的范围,默认值是 compile。
- optional(可选):标记依赖是否可选
- exclusions(可选):用来排除传递性依赖,例如 jar 包冲突
著作权归JavaGuide(javaguide.cn)所有 基于MIT协议 原文链接:https://javaguide.cn/tools/maven/maven-core-concepts.html
著作权归JavaGuide(javaguide.cn)所有 基于MIT协议 原文链接:https://javaguide.cn/tools/maven/maven-core-concepts.html
xml
eXtensible Markup Language 即可扩展标记语言。
一般用于做数据存储,支持自定义标签
通过 XML,数据能够存储在独立的 XML 文件中。这样您就可以专注于使用 HTML/CSS 进行显示和布局,并确保修改底层数据不再需要对 HTML 进行任何的改变。
通过使用几行 JavaScript 代码,您就可以读取一个外部 XML 文件,并更新您的网页的数据内容。
基础语法:
//文档声明:
<?xml version = "xxx" ? encodiing standlone>
encoding 指定文档的编码 UTF-8等
standalone 文档是否独立 yes or no
注释:
<!--comment -->
标签内要包含要传递的信息
<message> <message/>- 示例: Bob写个Tom的信
<?xml version "1.0" encoding = "UTF-8"> <!--声明--> <note> <!-- 根元素,来表示本文档的类型--> <to> Tom </to> <from> Bob </from> <heading> Reminder </heading> <body> Dont' forget me this weekend </body> </note> - xml文档必须包含一个根元素,且只能有一个根元素,其他所有元素都是根元素的子元素
- 所有的标签都有一个闭标签 </…>
- xml 标签对大小写敏感
- 属性值必须加引号
<note date="12/11/2023"> - 实体引用,用于转义某些符号
< < less than
> > greater than
& & ampersand
' ' apostrophe
" " quotation mark- 标签命名: 尽量用 __ 来进行命名 first_name
- 属性Attribute : 提供有关元素的额外信息 (尽量减少属性的使用,将属性作为一个新的标签即可)
- DTD 用于定义xml文档结构 Schema 基于xml的DTD替代
- XSLT来显示XML
XMLHttpRequest 对象(JavaScript)
功能:
在不重新加载页面的情况下更新网页
在页面已加载后从服务器请求数据
在页面已加载后从服务器接收数据
在后台向服务器发送数据
yaml
特点:
示例:
key:
child-key: value # 给予值的时候要空一个额格
#较为复杂的对象格式,可以使用问号加一个空格代表一个复杂的 key,配合一个冒号加一个空格代表一个 value:
?
- complexkey1
- complexkey2
:
- complexvalue1
- complexvalue2
意思即对象的属性是一个数组 [complexkey1,complexkey2],对应的值也是一个数组 [complexvalue1,complexvalue2]- 数组
# 多维数组 - a - b - c - d - e - f companies: - id: 1 name: company1 price: 200W - id: 2 name: company2 price: 500W
复合结构
数组和对象可以构成复合结构,例:
languages:
- Ruby
- Perl
- Python
websites:
YAML: yaml.org
Ruby: ruby-lang.org
Python: python.org
Perl: use.perl.org
转换为 json 为:
{
languages: [ 'Ruby', 'Perl', 'Python'],
websites: {
YAML: 'yaml.org',
Ruby: 'ruby-lang.org',
Python: 'python.org',
Perl: 'use.perl.org'
}
}Docker
- 安装,并修改安装路径(windows)
此方法官方文档里有
先下载安装包
在想安装的地方建立文件夹Docker即可
然后打开cmd,输入"Docker Desktop Installer.exe" install --installation-dir="E:\Program Files\Docker" 后面的是你自己的路径,根据实际修改即可,等待安装完毕即可
基础概念
容器是镜像的实例化,容器是一个小型的os,包含应用和其本身所需要的环境,镜像是只读的,而容器是可以运行的可写的,其中的容器处于运行状态
命令
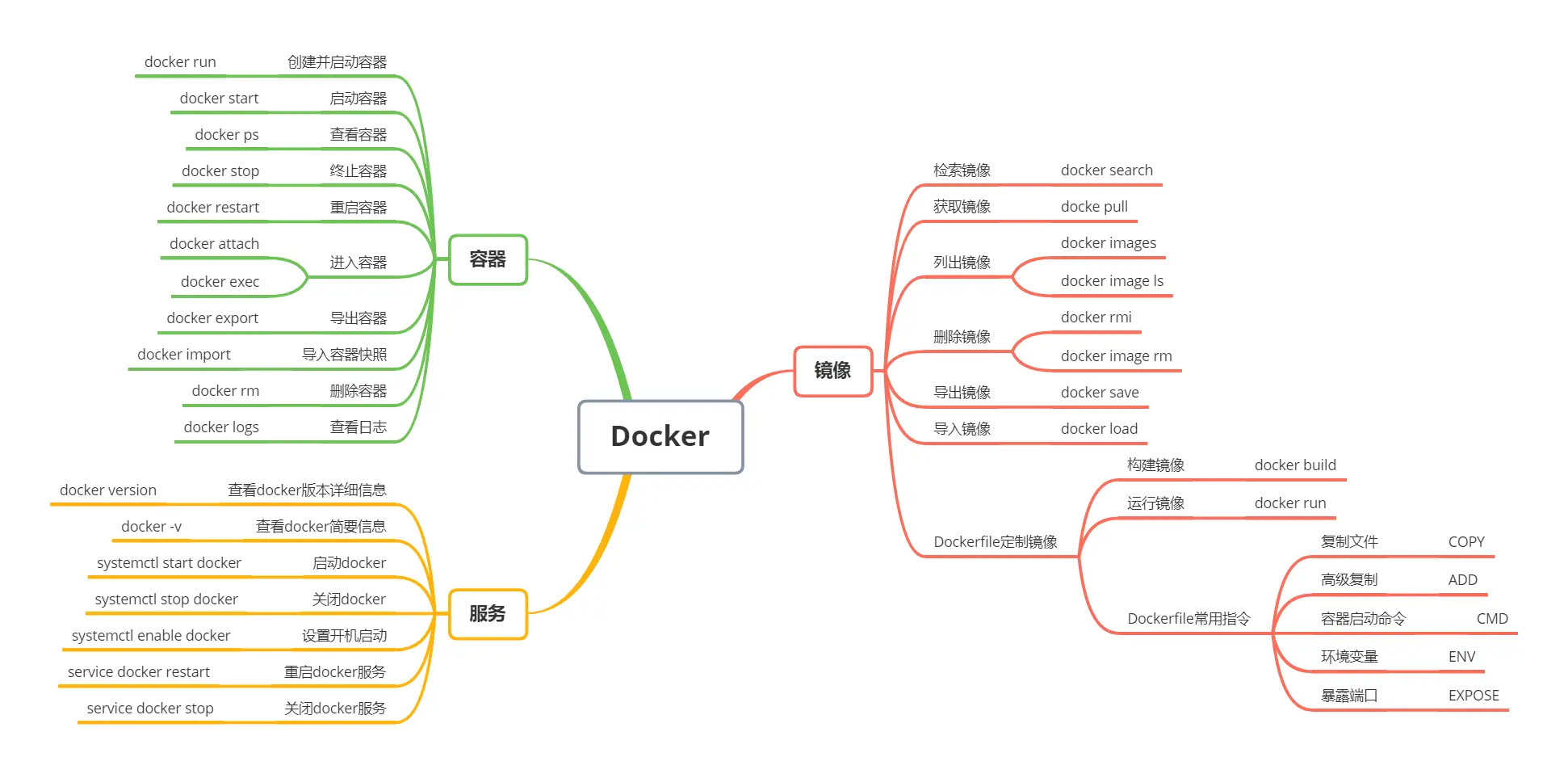
- 基础镜像命令(与git类似)
- ls , tag , inspect
docker tag 旧 新 docker inspect 获得该镜像的详细信息. -f 后面加上想获得的某一项的key就可以单独获得这一项的内容了 格式为{{".key名"}} docker history 查看某一镜像的历史 docker search -f=is-official=true --limit 5 --no-trunc nginx -f 过滤条件 limit 限制输出的数量 --no-trunc 不截断输出结果 docker rmi -f myubuntu 当存在多个标签时,删除的只是标签,当仅仅剩下一个标签时会把这个镜像直接删除 -f 强制删除 docker image prune 清理临时镜像文件,虚悬文件,指的是docker images 中没有名字的文件 -a 删除所有无用image 不光是临时镜像 -filter 只删除符合过滤条件的镜像 - `until`: 根据镜像的创建时间来筛选。例如,`until=24h`将删除24小时之前创建的镜像。 - `label`: 根据标签来筛选。例如,`label=myapp`将删除带有标签为"myapp"的镜像。 - `dangling`: 筛选出悬挂(无用)镜像。使用`dangling=true`来删除悬挂镜像。 -f 强制删除 创建镜像 docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]] docker commit [选项] <容器ID或容器名> [<仓库名>[:<标签>]] docker commit \ --author "Tao Wang <twang2218@gmail.com>" \ --message "修改了默认网页" \ webserver \ nginx:v2 // - `CONTAINER`是要保存状态的容器的名称或容器ID。 - `REPOSITORY[:TAG]`是新镜像的名称和标签。如果不提供标签,将默认使用"latest"标签。 docker commit -m "xxx" 被提交的容器 //导入导出镜像 docker save -o my_images.tar image1:tag image2:tag image3:tag 保存多个到镜像到指定的文件夹 docker load -i my_image.tar
容器操作
docker create xxx
可选。。。
-i 默认打开标准输入
-t分配一个伪终端
docker start xx 启动一个容器
docker run --name 新名字 options 镜像 创建并启动一个容器
可选
-d 以守护态后台运行,容器是否会长久运行,是和 `docker run` 指定的命令有关,和 `-d` 参数无关。
-t 分配一个伪终端
-i 让容器的标准输入保持打开
docker restart 关闭容器并重新启动
docker logs
-details
-f follow 持续保持输出
since string 从某一个时间开始日志
-tail string 输出最近的若干日志
-t timestamps 显示时间戳信息
-until string 输出某个时间段之前的信息
docker exec -it xxx 进入一个后台的容器 使用这个之后再容器内部执行exit 时不会导致容器停止,但是使用 docker attach 进入容器并退出的话会导致容器停止并退出
docker rm
-f 强制终止并删除一个容器
-l 删除容器的链接,但保留容器
-v 删除容器挂在的数据卷
docker top 容器名称 查看容器的进程
docker inspect 容器名称 查看容器信息
docker cp <本地文件/目录路径> <容器ID或名称>:<容器内部路径>
docker cp <容器ID或名称>:<容器内部路径> <本地文件/目录路径>
-a 打包
-L 跟随软连接
docker pause id 暂停- 创建卷: 您可以使用以下命令创建一个卷:
bashCopy code
docker volume create my_volume这将创建一个名为
my_volume的卷。
查看卷列表: 要查看系统中的所有卷,可以运行:
bashCopy code
docker volume ls删除卷: 要删除一个不再需要的卷,可以运行:
bashCopy code
docker volume rm my_volume挂载卷到容器: 在运行容器时,使用
-v或--volume标志来将卷挂载到容器内部。例如:bashCopy code
docker run -d -v my_volume:/path/in/container my_image这将把
my_volume卷挂载到容器内部的/path/in/container目录。挂载主机目录到容器: 您还可以将主机上的目录挂载到容器内。例如:
bashCopy code
docker run -d -v /host/path:/path/in/container my_image这将把主机上的
/host/path目录挂载到容器内的/path/in/container。查看容器的挂载卷: 要查看正在运行的容器挂载了哪些卷,可以使用以下命令:
bashCopy code
docker inspect -f '{{ .Mounts }}' container_name_or_id复制文件到卷: 如果需要将文件复制到卷中,可以运行一个临时容器,然后将文件复制到挂载卷的路径。例如:
bashCopy code
docker run --rm -v my_volume:/path/in/container -v /local/path/to/file:/data busybox cp /local/path/to/file /path/in/container这将复制
/local/path/to/file到my_volume卷的/path/in/container。卷数据备份和恢复: 您可以使用工具如
docker cp或docker export来备份卷数据,然后使用docker create和docker start来恢复它们。备份和恢复数据的确切方法取决于您的需求和容器的情况。挂载数据卷 1.建立数据卷 docker run -it -v /db --name db0 ubuntu docker run -it --volume-from db --name db1 ubuntu docker run -it --volume-from db --name db2 ubuntu
- VOLUME 的使用
将数据读写存储在数据卷中,使得容器尽量不发生读写操作,dockerfile 中的VOLUME是可以呗docker run覆盖的
dockerfile
指令详解
| Dockerfile 指令 | 说明 |
|---|---|
| FROM | 指定基础镜像,用于后续的指令构建。 |
| LABEL | 添加镜像的元数据,使用键值对的形式,方便后续进行filter来筛选。 |
| RUN | 在构建过程中在镜像中执行命令。 |
| CMD | 指定容器创建时的默认命令。(可以被覆盖) |
| ENTRYPOINT | 设置容器创建时的主要命令。(不可被覆盖), |
| EXPOSE | 声明容器运行时监听的特定网络端口,不会自动映射,只是声明,需要自己配置 |
| ENV | 在容器内部设置环境变量。 |
| ADD | 将文件、目录或远程URL复制到镜像,自动解压 |
| COPY | 将文件或目录复制到镜像中。 |
| VOLUME | 为容器创建挂载点或声明卷。 |
| WORKDIR | 设置后续指令的工作目录。 |
| USER | 指定后续指令的用户上下文。 |
| ARG | 定义在构建过程中传递给构建器的变量,可使用 “docker build” 命令设置。 |
| ONBUILD | 当该镜像被用作另一个构建过程的基础时,添加触发器。 |
| STOPSIGNAL | 设置发送给容器以退出的系统调用信号。 |
| HEALTHCHECK | 定义周期性检查容器健康状态的命令 |
| SHELL | 覆盖Docker中默认的shell,用于RUN、CMD和ENTRYPOINT指令。 |
| RUN | 运行指定命令 |
| CMD | 启动容器时指定默认执行的命令 |
| ADD | 添加内容到镜像 |
| COPY | 复制内容到镜像 |
实际操作
推荐使用基础镜像:
BusyBox 集成Linux的命令
Alpine 在BusyBox基础上减小体积和消耗,并提供了apt管理工具
- 使用dockerfile为镜像添加ssh服务
#设置继承镜像 FROM myub #提供作者信息 MAINTAINER docker_user (user@docker.com) #执行命令 RUN apt-get update RUN apt-get install -y openssh-server RUN mkdir -p /var/run/sshd RUN mkdir -p /root/.ssh RUN sed -ri 's/session required pam_loginid.so/#session required pam_loginuid.so/g' /etc/pam.d/sshd #复制配置文件到对应位置,并赋予其可执行权限 ADD authorized_keys /root/.ssh/authorized_eys ADD run.sh /run.sh RUN chmod 755 /run.sh #开放端口 EXPOSE 22 #设置自启动命令 CMD ["/run.sh"]
FROM scratch
如果你以 scratch 为基础镜像的话,意味着你不以任何镜像为基础,接下来所写的指令将作为镜像第一层开始存在。
不以任何系统为基础,直接将可执行文件复制进镜像的做法并不罕见,对于 Linux 下静态编译的程序来说,并不需要有操作系统提供运行时支持,所需的一切库都已经在可执行文件里了,因此直接 FROM scratch 会让镜像体积更加小巧。使用 Go 语言 开发的应用很多会使用这种方式来制作镜像,这也是有人认为 Go 是特别适合容器微服务架构的语言的原因之一。
每一个RUN会建立一层,所以要进行多重操作的时候不要每一行都建立一个RUN而是将他们合在一层
FROM debian:stretch
RUN set -x; buildDeps='gcc libc6-dev make wget' \
&& apt-get update \
&& apt-get install -y $buildDeps \
&& wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz" \
&& mkdir -p /usr/src/redis \
&& tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1 \
&& make -C /usr/src/redis \
&& make -C /usr/src/redis install \
&& rm -rf /var/lib/apt/lists/* \
&& rm redis.tar.gz \
&& rm -r /usr/src/redis \
&& apt-get purge -y --auto-remove $buildDepsdocker 不是虚拟机不存在后台运行,其中的所有应用都是在前台运行的,所以dockerfile 中直接执行这个应用即可,然后退出容器,让容器在后台运行即可
CMD ["nginx", "-g", "daemon off;"]这是因为当存在
ENTRYPOINT后,CMD的内容将会作为参数传给ENTRYPOINT,而这里-i就是新的CMD,因此会作为参数传给curl,从而达到了我们预期的效果。ENV 设置
ENV key1=value1 key2=value2 .....ARG 设置变量 等于
docker build中用--build-arg <参数名>=<值>ARG 指令有生效范围,如果在
FROM指令之前指定,那么只能用于FROM指令中。# 只在 FROM 中生效 ARG DOCKER_USERNAME=library FROM ${DOCKER_USERNAME}/alpine # 要想在 FROM 之后使用,必须再次指定 ARG DOCKER_USERNAME=library RUN set -x ; echo ${DOCKER_USERNAME}HEALTHCHECK
--interval=<间隔>:两次健康检查的间隔,默认为 30 秒;--timeout=<时长>:健康检查命令运行超时时间,如果超过这个时间,本次健康检查就被视为失败,默认 30 秒;--retries=<次数>:当连续失败指定次数后,则将容器状态视为unhealthy,默认 3 次。
FROM nginx
RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/*
HEALTHCHECK \
CMD curl -fs http://localhost/ || exit 1- 多阶段构造镜像
- 多个FROM 和 构造过程写在一个dockerfile 中
- 使用as 来为某一阶段的构造命名 FROM golang:alpine as builder之后构造时直接指定名字即可, $ docker build –target builder -t username/imagename:tag .
- docker 导入导出容器
示例:docker export 7691a814370e > ubuntu.tar cat ubuntu.tar | docker import - test/ubuntu:v1.0 # 将文件读入到标准输入流,再将其导入到镜像中 # 或者使用URL 来导入也行
docker 查看容器ip
docker inspect 容器ID | grep IPAddressNexus 容器
可以方便进行对Maven , Docker ,Yum,PyPI的管理
Lua 一种可以嵌入程序的简便语言
一般只适合在linux上使用
安装:apt-get install luaxxx(版本号)
执行lua xxx.lua
交互式编程
Lua 提供了交互式编程模式。我们可以在命令行中输入程序并立即查看效果。
Lua 交互式编程模式可以通过命令 lua -i 或 lua 来启用
- 基本语法
- 注释 – 单行
--[[xxxx --]]多行注释 - 默认为全局变量,全局变量不需要声明,不需要时置为nil即可,局部变量使用 local 来指定
- 基本数据类型: nil ,boolean , number(为double类型) , string ,userdata (任意存储在变量中的数据结构)
- userdata 是一种用户自定义数据,用于表示一种由应用程序或 C/C++ 语言库所创建的类型。 可以将任意 C/C++ 的任意数据类型的数据(通常是 struct 和 指针)存储到 Lua 变量中调用
- function(由C 或Lua编写的函数) , thread(线程), table(关联数组)
- 使用
[[]]来跨越多行赋值 - Lua可以对多个变量同时赋值,变量列表和值列表的各个元素用逗号分开,赋值语句右边的值会依次赋给左边的变量
html = [[ <html> <head></head> <body> <a href="https://www.twle.cn/">简单编程</a> </body> </html> ]]
- 注释 – 单行
- lua会尝试将字符数字转化为数字来进行数字计算,字符串连接符是
.. string 来计算字符串的长度
- 默认索引是从1开始
- function 可以以匿名函数(anonymous function)的方式通过参数传递
-- !/usr/bin/lua -- -*- encoding:utf-8 -*- -- filename: main.lua -- author: 简单教程(www.twle.cn) -- Copyright © 2015-2065 www.twle.cn. All rights reserved. function testFun(tab,fun) for k ,v in pairs(tab) do print(fun(k,v)); end end tab={key1="val1",key2="val2"}; testFun(tab, function(key,val)--匿名函数 return key.."="..val; end ); - table变量可以使用索引,key,或者 . 来获取值
- 注意 : Lua 中 0 为 true
- 多返回值Lua 中的函数可以返回多个结果值,例如 string.find 返回匹配串 “开始和结束的下标”(如果不存在匹配串返回 nil )
> s, e = string.find("www.twle.cn", "twle") > print(s, e) 5 10 - 可变参数 使用 … 来代表
- 算术运算符 有 ^ 幂运算哦
- 不等于是 -= 不是 !=
- 逻辑运算 and , or ,not
返回字符串个数或者传入参数个数..
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \ | 代表一个反斜线字符’’' | 092 |
| ' | 代表一个单引号(撇号)字符 | 039 |
| " | 代表一个双引号字符 | 034 |
| \0 | 空字符(NULL) | 000 |
| \ddd | 1到3位八进制数所代表的任意字符 | 三位八进制 |
| \xhh | 1到2位十六进制所代表的任意字符 | 二位十六进制 |
常用字符串方法 string + . +
- upper 大写 lower 小写
- gsub(string , findstring , replacestring ,num) 从string中查找findstring,并替换为replacestring ,num是替换的次数
- find () 返回首次出现该字符串的前后位置,包括开始和结束的位置
- reverse 反转
- char(num1,num2…) 将数字变为字母,ascii码
- byte(字母串,指定某个字符) 将字母变为数字
- len 长度
- rep(string,num) 返回重复num次的string
- gmatch(string,pattern) 返回一个迭代器,返回一个符合pattern的字串,可以使用
- format ()格式化 转义码
数组 lua的数组可以从负数开始遍历索引从1开始
for i= -1 , 10 do ...- 迭代器:
-- pairs用于匹配键值对 local myTable = {a = 1, b = 2, c = 3} for key, value in pairs(myTable) do print(key, value) end --ispairs 用于遍历数组,字符串等 local myArray = {10, 20, 30} for index, value in ipairs(myArray) do print(index, value) end --自定义迭代器,实际就是自己写的遍历算法。。 function myIterator(collection) local index = 1 local size = #collection return function() if index <= size then local value = collection[index] index = index + 1 return value end end end local myArray = {100, 200, 300} local iter = myIterator(myArray) for value in iter do print(value) end
table常用方法 table + . +
- concat 是 concatenate (连锁, 连接) 的缩写. table.concat() 函数列出参数中指定 table 的数组部分从 start 位置到 end 位置的所有元素, 元素间以指定的分隔符(sep)隔开
- insert(table,pos,value) 在指定位置添加一个value ,如果未指定位置,默认从尾部加入
- remove(table,post) 返回并移除table 位于pos位置的元素,后面的元素会自动向前
- sort 进行升序排序
lua的模式匹配
开源中国中正则表达式列表
lua模式匹配% 用于将后面的字符转义为字面量而不是特殊字符,例如
%。 匹配的是。而不是其他的
有时也会有特殊含义: %a 代表的是匹配一个字母,%d 代表匹配一个数字
字符类 %d 匹配任意数字,所以可以使用模式串 ‘%d%d/%d%d/%d%d%d%d’ 搜索 dd/mm/yyyy 格式
模块和导包
导包require(模块名),甚至可以加个.var赋给一个变量来调用模块
元表?
协程
nginx
一种高性能的 HTTP 和 反向代理的服务器,默认监听端口是80不是8080
- 基本命令
nginx 启动 nginx -s quit 优雅的退出,完成所有任务后退出 nginx -s stop 强制退出 nginx -s reload 重启,来刷新配置文件 nginx -t 测试配置文件是否可用,同时会显示配置文件的路径 - 配置文件
配置文件分为三类
- 全局块,服务器配置,日志存放等
- events 主要影响服务器和用户的网络连接
- http 可以分很多块
server块 全局块 本机监听配置和ip配置
location 局部块 控制地址定向,转发等 , 在server块内来匹配新的转发路径
用法一:反向代理,作为另一个服务器的转发服务器来隐藏另一个服务器
使用docker 启动一个tomcat服务器,并进入并启动服务
docker run -itd tomcat /bin/sh
进入tomcat/bin目录
./startup.sh错误情况:
docker tomcat无法启动
- 可能没有映射端口或者没有关闭防火墙
- 把webapps.dist目录换成webapps
- 将文件扔到webapps即可
测试第一个方法,解决问题!
进入容器内部
docker exec -it mytomcat /bin/bash复制
rm -rf webapps
mv webapps.dist webapps复制
重启tomcat
docker restart mytomcat查看docker的tomcat ipdocker inspect ID | grep IPAddress
配置文件:
server {
listen 8888 ; ##设置我们nginx监听端口为8888
server_name [服务器的ip地址]; # 不带http
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
proxy_pass http://tomcat服务器ip:8080; ##需要代理的服务器地址
index index.html;
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
打开浏览器输入服务器的ip和代理端口,就可以看到docker容器中tomcat的主界面
实现服务器分发
配置server { listen 8888 ; ##设置我们nginx监听端口为8888 server_name [服务器的ip地址]; # Load configuration files for the default server block. include /etc/nginx/default.d/*.conf; location /hi/ { proxy_pass http://服务器2; ##需要代理的服务器地址 index index.html; } location /hello/ { proxy_pass http://服务器2; ##需要代理的服务器地址 index index.html; } error_page 404 /404.html; location = /40x.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } }-
location [ = | ~ | ~* | ^~ ] /URI { … } location @/name/ { … } ########### 顺序 1. location = # 精准匹配 2. location ^~ # 带参前缀匹配 3. location ~ # 正则匹配(区分大小写) 4. location ~* # 正则匹配(不区分大小写) 5. location /a # 普通前缀匹配,优先级低于带参数前缀匹配。 6. location / # 任何没有匹配成功的,都会匹配这里处理参数 解释 空location 后没有参数直接跟着 标准 URI,表示前缀匹配,代表跟请求中的 URI 从头开始匹配。 =用于标准 URI 前,要求请求字符串与其精准匹配,成功则立即处理,nginx停止搜索其他匹配。 ^~用于标准 URI 前,并要求一旦匹配到就会立即处理,不再去匹配其他的那些个正则 URI,一般用来匹配目录 ~用于正则 URI 前,表示 URI 包含正则表达式, 区分大小写 ~*用于正则 URI 前, 表示 URI 包含正则表达式, 不区分大小写 @@ 定义一个命名的 location,@ 定义的locaiton名字一般用在内部定向,例如error_page, try_files命令中。它的功能类似于编程中的goto。 顺序
- 先精准匹配
=,精准匹配成功则会立即停止其他类型匹配; - 没有精准匹配成功时,进行前缀匹配。先查找带有
^~的前缀匹配,带有^~的前缀匹配成功则立即停止其他类型匹配,普通前缀匹配(不带参数^~)成功则会暂存,继续查找正则匹配; =和^~均未匹配成功前提下,查找正则匹配~和~*。当同时有多个正则匹配时,按其在配置文件中出现的先后顺序优先匹配,命中则立即停止其他类型匹配;- 所有正则匹配均未成功时,返回步骤 2 中暂存的普通前缀匹配(不带参数
^~)结果
- 负载均衡
配置文件(server块)http { ###此处省略一大堆没有改的配置 ##自定义我们的服务列表 upstream myserver{ #### 可以使用 ip_hash 来进行hash 分配,可以与weight一起使用 ip_hash; server 服务器1及端口; # 可加权值来表示优先级,server 服务器1及端口 + weight = 数字; 数字越大,权重越高 server 服务器2及接口; …… } server { listen 8888 ; ##设置我们nginx监听端口为8888 server_name [服务器的ip地址]; # Load configuration files for the default server block. include /etc/nginx/default.d/*.conf; location / { proxy_pass http://myserver; ##叮,核心配置在这里 proxy_connect_timeout 10; #超时时间,单位秒 } error_page 404 /404.html; location = /40x.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } } } - 关闭一个tomcat之后,发现仍然可以访问,但关闭所有的tomcat时发现无法访问了,说明实现了负载均衡
Linux基本操作
常用操作:
lsof -i:9999 查看端口占用情况
top/htop 查看系统资源占用情况Bash界面
快捷键
Ctl-U 删除光标到行首的所有字符,在某些设置下,删除全行
Ctl-W 删除当前光标到前边的最近一个空格之间的字符
Ctl-H backspace,删除光标前边的字符
Ctl-R 匹配最相近的一个文件,然后输出用户操作
useradd -m username 创建用户,-m是会创建对应的用户目录到/home下,不加的话不会创建这个目录,-d 参数用来指定用户目录的位置
userdel -r 直接把用户目录删掉了不加r就不删除目录
who am i 看当前账号是什么
groupadd 创建一个用户组
useradd -g 用户组 用户名 把这个用户加入到用户组
usermod -g 用户组 用户名 修改
usermod -d 目录名 用户名 改变该用户登录的初始目录
其他指令
mkdir -p 创建多级目录
cp -r 递归的复制整个文件夹
cat -n 显示行
head -n 数字 默认看前10行 , 加上-n 之后可以指定查看多少行
tial -n 数字 查看最后几行
tail -f 实时追踪该文件的所有更新
> 将内容覆盖在文件中
>> 在后面追加
ln -s 文件 链接的地方
history
! + history 中的指令编号,重新执行这条指令
date
cal 日历
find 路径
-name 匹配文件名
-user 属于某个用户的
-size +n /-n /n 匹配文件大小 + 代表大于,-代表小于,不加代表等于 可加单位 K/M/G
locate 通过自建的数据库来进行查找,速度迅速,但是需要自己更新数据库
限制性updatedb
grep
|grep + -n 显示行号/ -i 忽略字母大小写匹配 + 要匹配的关键字
权限
1-9位依次是 user group other的武安县
chown -R 用户 文件 改变所属 -R来把里面的文件也执行这种修改
chgrp 组名 文件名 改变所有组任务按时调度
crond -l 显示当前用户的定时任务
crontab -e 来编辑内容
语法:
* * * * * /path/to/command 也可以直接写一行shell脚本
1. 第一个星号:分钟(0-59)
2. 第二个星号:小时(0-23)
3. 第三个星号:日期(1-31)
4. 第四个星号:月份(1-12或使用缩写,如1代表一月,2代表二月,以此类推)
5. 第五个星号:星期几(0-7或使用缩写,0和7都代表星期日,1代表星期一,以此类推)
使用这些星号,您可以定义定时任务的执行时间。例如,以下是一些示例:
- `* * * * *`:每分钟都执行任务。
- `0 * * * *`:每小时的开始时执行任务。
- `0 0 * * *`:每天的午夜(凌晨12点)执行任务。
- `0 0 1 * *`:每个月的第一天(日期1)的午夜执行任务。
- `0 0 * * 5`:每个星期五的午夜执行任务。
如果您想要更具体的时间表,可以将具体的数字替换星号,例如 `30 8 * * 1-5` 表示每个工作日的上午8点30分执行任务。
at 执行一次性任务只会在指定的时间点执行但是不会重复执行措辞
用法
1. at + 时间 hh:mm
2. 输入要执行的指令然后按 ctrl + d 保存
atq 查看计划中的任务
删除计划任务
atrm id
crontab -r 删除定时任务磁盘操作
lsblk 显示所有的磁盘和分区和挂载情况
fdisk 指定目录下的磁盘
mkfs 格式化磁盘
mount 磁盘目录 挂载目录 挂载分区
umount 取消挂载
df-h 查看磁盘状态 -T 查看磁盘类型计算机网络
ifconfig 查看ip
netstat 查看系统网络情况
-an 按照一定顺序排序输出
-p 不加参数 显示哪个进程在调用
进程管理
ps
-a 显示当前所有进程信息
-u 以用户的格式显示进程信息
-x 显示后台运行的参数
-e 显示所有进程 包括父进程等等
-f 全格式
kill + pid 删除进程
-9 强制
killall 进程名称(支持通配符匹配)
pstree 查看进程树
-p 显示pid
-u 显示进程所属用户
/*service*/
systemctl +
start xxx
stop
restart
status 查看某个服务的状态
enable 启动一个服务,使其自启动
list-unit-files --type=service | grep enabled 查看所有已启动的服务
get-default 查看系统的默认目标
set-default 设置默认目标
list-units 列出正在运行的单元
top 和ps相似,但是可以实时更新正在运行的的进程
-d + 秒数 每隔多少秒更新一次
-i 使top不显示任何僵死进程
-p + pid 监视某个指定进程的状态
top中使用
P 按照cpu使用率排序,默认
M 以内存使用率
N 以PID
q 退出shell 编程
- 重定向
- here document
#!/bin/bash cat << END "这里是ls的使用方法" END ls /root/shell_test 输出>>> "这里是ls的使用方法" hell.sh ls.sh say.sh - 管道
|& 将标准输出和错误信息一起传递给后面的命令 - 命令分组
{ commands ....... } > 文件 使用 () 会将命令由子shell来进行执行 :等于true- echo
echo -e 后面就可以加上换行符和制表符等特殊符号了 - printf
printf 格式(%s等) 参数 - set / unset 设置/取消 环境变量
- read 从标准输入读入放入后面给出的变量
- wait 控制多进程
- eval , exec , sed
- source 执行shell脚本
k8s kubernetes
解决容器编排问题,实现分布式部署和替换,实现服务器集群
kubernetes组件
一个kubernetes集群主要是由控制节点(master)、**工作节点(node)**构成,每个节点上都会安装不同的组件。
- master:集群的控制平面,负责集群的决策 ( 管理 )
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等
Etcd :负责存储集群中各种资源对象的信息
- node:集群的数据平面,负责为容器提供运行环境 ( 干活 )
Kubelet : 负责维护容器的生命周期,即通过控制docker,来创建、更新、销毁容器
KubeProxy : 负责提供集群内部的服务发现和负载均衡
Docker : 负责节点上容器的各种操作
- 基础概念
Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控
Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的docker负责容器的运行
Pod:kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器
Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
Service:pod对外服务的统一入口,下面可以维护者同一类的多个pod
Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
NameSpace:命名空间,用来隔离pod的运行环境
Jenkins
Jenkins原理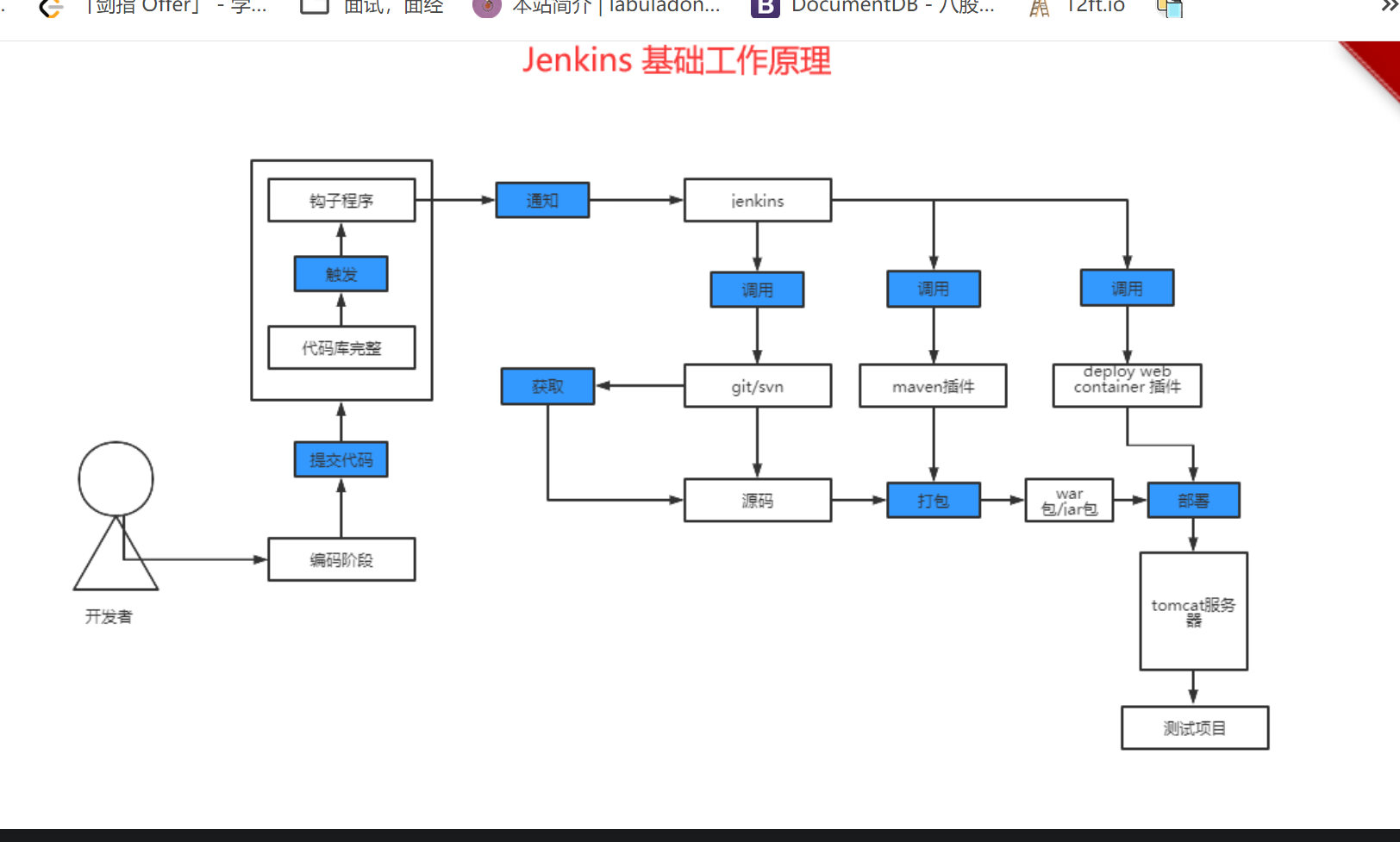
Gradle
与Maven相比,Maven更侧重于包的管理,而Gradle侧重于大项目构建
SVN
一种不同于git 的版本控制系统
SVN主要是集中式的版本控制系统:所有的文件版本信息都存储在中央服务器,用户进行工作时是创建一个副本,所以版本的历史是线性的
目录也是版本控制的一部分,分支和标签是目录的复制
而git是每个人的电脑上都是一个具体的版本库,版本的历史不是线性的,分支处理更加高效。
SVN的分支实际上就是新建一个目录,然后把原来的文件复制一份进去。
优缺点对比:
- SVN:
- 优点 更加高效的处理二进制文件,版本历史线性,容易理解,更好的处理权限访问和控制。
- 缺点:提交和更改需要联网,然后分支合并更加麻烦,速度慢,每次操作都需要与服务器通信。
- Git
- 优点:分布式控制,离线也可以进行开发,速度更快
- 缺点:学习比SVN复杂,对二进制的处理不好,容易造成性能问题。