OS
系统调用跳到内核与标准的函数调用跳到另一个函数相比,区别是什么?
Kernel的代码总是有特殊的权限。当机器启动Kernel时,Kernel会有特殊的权限能直接访问各种各样的硬件,例如磁盘。而普通的用户程序是没有办法直接访问这些硬件的。所以,当你执行一个普通的函数调用时,你所调用的函数并没有对于硬件的特殊权限。然而,如果你触发系统调用到内核中,内核中的具体实现会具有这些特殊的权限,这样就能修改敏感的和被保护的硬件资源,比如访问硬件磁盘。我们之后会介绍更多有关的细节。
Kernel
内核使用CPU提供的硬件保护机制来确保每个在用户空间执行的进程只能访问它自己的内存。内核程序的执行拥有操控硬件的权限,它需要实现这些保护;而用户程序执行时没有这些特权。当用户程序调用系统调用时,硬件会提升权限级别,并开始执行内核中预先安排好的函数。
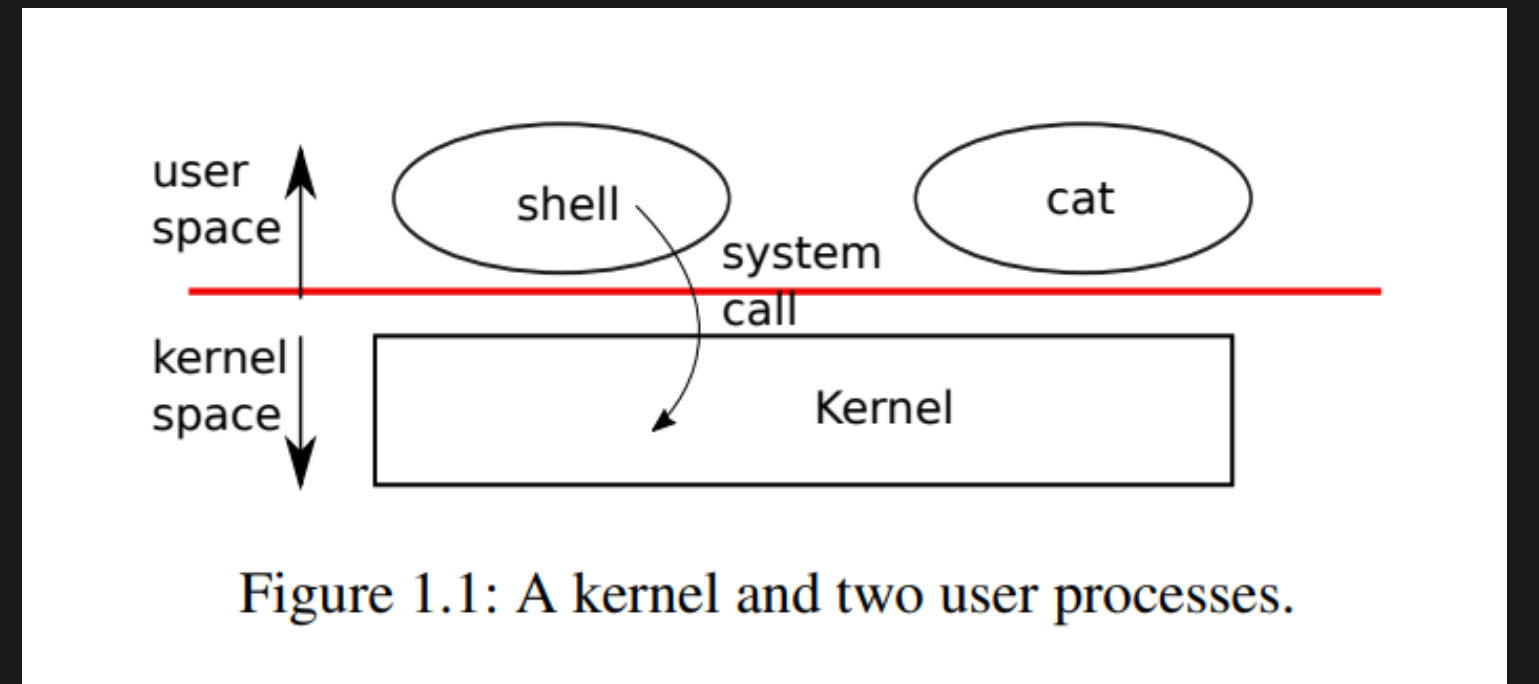
xv6提供的系统调用
看文档Shell 是一个普通的进程,是一个用户程序,用户使用Shell来与系统调用进行交互
进程
- 进程由 用户空间内存(指令、数据和堆栈)和对内核私有的每个进程状态组成
- Xv6 采用分时进程,等待执行中的进程集合切换可用的CPU,当进程没有执行时,xv6会保存他的CPU寄存器,并在下一次运行时恢复,使用进程id或PID标示进程、
I/O
- 文件描述符是一个小整数(small integer),表示进程可以读取或写入的由内核管理的对象
- 进程从文件描述符0读取(标准输入),将输出写入文件描述符1(标准输出),并将错误消息写入文件描述符2(标准错误)。
- 管道:作为一对文件描述符公开给进程的小型内核缓冲区,一个用于读取,一个用于写入。将数据写入管道的一端使得这些数据可以从管道的另一端读取。管道为进程提供了一种通信方式。
首先,管道会自动清理自己;在文件重定向时,shell使用完
/tmp/xyz后必须小心删除其次,管道可以任意传递长的数据流,而文件重定向需要磁盘上足够的空闲空间来存储所有的数据。
第三,管道允许并行执行管道阶段,而文件方法要求第一个程序在第二个程序启动之前完成。
第四,如果实现进程间通讯,管道的阻塞式读写比文件的非阻塞语义更高效。
操作系统架构
操作系统必须满足三个要求:多路复用、隔离和交互。
- 隔离:禁止应用程序直接访问敏感的硬件资源,将资源抽象成服务。提供系统调用
- 用户想要执行内核函数必须由用户模式过渡到管理模式
- 整个操作系统都驻留在内核中,这样所有系统调用的实现都以管理模式运行。这种组织被称为宏内核(monolithic kernel)。
- 缺点是操作系统不同部分之间的接口通常很复杂(正如我们将在本文的其余部分中看到的),因此操作系统开发人员很容易犯错误。在宏内核中,一个错误就可能是致命的,因为管理模式中的错误经常会导致内核失败。如果内核失败,计算机停止工作,因此所有应用程序也会失败。计算机必须重启才能再次使用。
- 微内核
- 操作系统设计者可以最大限度地减少在管理模式下运行的操作系统代码量,并在用户模式下执行大部分操作系统。这种内核组织被称为微内核(microkernel)
- 文件系统作为用户级进程运行。作为进程运行的操作系统服务被称为服务器。为了允许应用程序与文件服务器交互,内核提供了允许从一个用户态进程向另一个用户态进程发送消息的进程间通信机制。
- 进程
- 进程抽象给程序提供了一种错觉,即它有自己的专用机器。进程为程序提供了一个看起来像是私有内存系统或地址空间的东西,其他进程不能读取或写入。
- 启动过程: 初始化自己并运行一个存储在只读内存中的引导加载程序。引导加载程序将xv6内核加载到内存中。然后,在机器模式下,中央处理器从
_entry(kernel/entry.S:6)开始运行xv6。Xv6启动时页式硬件(paging hardware)处于禁用模式:也就是说虚拟地址将直接映射到物理地址。
页表
页表是操作系统为每个进程提供私有地址空间和内存的机制。页表决定了内存地址的含义,以及物理内存的哪些部分可以访问。
Lab
lab1
推荐使用2021版的官方教程,2020的我打开不了
不建议在root用户下进行
sleep (easy)
实现xv6的UNIX程序sleep:您的sleep应该暂停到用户指定的计时数。一个滴答(tick)是由xv6内核定义的时间概念,即来自定时器芯片的两个中断之间的时间。您的解决方案应该在文件user/sleep.c中
思路:先查看系统调用的代码
- 引入头文件,即
kernel/types.h声明类型的头文件和user/user.h声明系统调用函数和ulib.c中函数的头文件。 - 编写
main(int argc,char* argv[])函数。其中,参数argc是命令行总参数的个数,参数argv[]是argc个参数,其中第 0 个参数是程序的全名,其他的参数是命令行后面跟的用户输入的参数。 - 在Makefile中加入$U/_sleep
参考答案:
Makefile://引入type定义和系统调用文件 #include "kernel/types.h" #include "user/user.h" //编写main函数 //argc 是shell接受的参数个数,argv指向对应的参数 //argv[0] 始终指向函数的全名 int main(int argc, char **argv) { //shell 中应该输入 sleep +参数,所以只接受一个参数, argc 应为 2 if(argc != 2) { //write(int fd ,char *buf, int n) // fd是文件描述符 0 是标准输入,1标准输出,2是标准错误 //buf 存放要写入写出的字符数组 // n 是要传输的字节数 write(2,"Usage: sleep time\n", strlen("Usage: sleep time\n")); //exit(status) 0 标示正常退出,非0藐视错误退出 exit(1); } //使用atoi来转为int型 sleep(atoi(argv[1])); exit(0); }
单元测试:UPROGS=\ $U/_cat\ $U/_echo\ $U/_forktest\ $U/_grep\ $U/_init\ $U/_kill\ $U/_ln\ $U/_ls\ $U/_mkdir\ $U/_rm\ $U/_sh\ $U/_stressfs\ $U/_usertests\ $U/_grind\ $U/_wc\ $U/_zombie\ $U/_sleep\ # 这是我们要写的 - make qemu 之后在shell中 sleep 100 看看是否停顿, 如果make qemu 报错,可能是没有 自动编译,建议重新启动
- 不启动xv6,在xv6-labs-2021 路径下使用: ./grade-lab-util sleep —-sleep可替换为其他待测的,也可以不加,直接把全部实验代码都进行测,权限不够自己sudo, 报错了可能没安装python3
pingpong (Easy)
编写一个使用UNIX系统调用的程序来在两个进程之间“ping-pong”一个字节,请使用两个管道,每个方向一个。父进程应该向子进程发送一个字节;子进程应该打印“
<pid>: received ping”,其中<pid>是进程ID,并在管道中写入字节发送给父进程,然后退出;父级应该从读取从子进程而来的字节,打印“<pid>: received pong”,然后退出。您的解决方案应该在文件_user/pingpong.c_中。
思路:
- 使用pipe来建立管道
- fork来建立子进程并用来区分父进程和子进程
- getpid来获取进程pid
- read 和 write来进行读写
- Makefile
// pingpong.c #include "kernel/types.h" #include "user/user.h" #include "stddef.h" // int main(int argc, char **argv) { // argc是输入的参数个数,argv指向对应的参数 //定义两个pipe int pp2c[2],pc2p[2]; // p parent to child //p[0] 是文件描述符0, 0 是输入端,1是输出端 pipe(pp2c); //父进程 -> 子进程 pipe(pc2p); //使用fork来判断子进程和父进程 if(fork() != 0 ) { //父进程 //write(文件描述符,指针,字节数) write(pp2c[1],"!",1); //父进程向子进程发出一个字节 char buf ; //待读入缓冲区,用于存储 read(pc2p[0],&buf,1); printf("%d: received pong\n",getpid()); wait(0); } else { char buf; //从父进程读入 read(pp2c[0],&buf,1); printf("%d: received ping\n",getpid()); //子进程重新发送给父进程 write(pc2p[1],&buf,1); } exit(0); }
prime
思路:使用筛法,每次输出一个素数之后,把这个素数的倍数删除,之后再重新写入pipe中供下一个子进程使用即可。注意回收文件描述符即可
注意: 一定要使用子进程 ,不使用子进程会导致阻塞致死
#include "kernel/types.h"
#include "user/user.h"
#include "stddef.h" // 为了得到NULL
//将描述符重新定向
void mapping(int n , int pd[]) {
close(n);
//dup会返回一个最小的未使用的文件描述符,然后我们close
//了n,也就是会返回n,之后会将这个描述符指向pd[n]所指向的文件
dup(pd[n]);
//再关闭pd 就实现了将pd[n] 重定向到n的操作
close(pd[0]);
close(pd[1]);
}
void primes() {
//开始读入数据
int current,next; //current来保存现在的数
int fd[2];
// 从0中读取数据,并写入current,读取字节长度为sizeof(int)
if(read(0,¤t,sizeof(int))) {
printf("prime %d\n",current);
pipe(fd);
//开始筛选,每经历一个子进程就drop一些数据
if(fork() == 0) {
mapping(1,fd);//定向到写入端
//重复从1中读入,判断是否是current的倍数
while(read(0,&next,sizeof(int))) {
if(next % current != 0) {
write(1,&next,sizeof(int));
}
}
} else {
wait(NULL); //等待子进程结束
//反复调用即可
mapping(0,fd);
primes();
}
}
}
//0用来读取, 1用来写入
int main(int argc, char **argv) {
int fd[2]; //文件描述符
//fd是共用的
pipe(fd); //fd[0]是读入端,也就是从pipe中读取字节,fd[1]是写入端,可以向pipe中写入
if(fork() == 0) {
//子进程写入 2 - 35
mapping(1,fd);//将标准输出指向fd的写入端,也就是将输指向写入端
for(int i = 2; i <= 35; i ++) {
//write 是向标准输出写入东西,标准输出已经指向fd[1]了,也就是向fd写入数据
write(1,&i,sizeof(int));
}
} else {
wait(NULL);//等待子进程写完
/**
* 当调用 wait(NULL) 时,父进程会被阻塞,直到任意一个子进程终止。一旦子进程终止,wait(NULL) 函数会返回被终止的子进程的进程 ID(PID),并且如果提供了 status 参数,
* 子进程的退出状态会存储在 status 中。
*/
mapping(0,fd);//将标准输入指向fd来进行读入
primes();
}
exit(0);
}