Elasticsearch学习笔记
Analyzer
Analyzer是ES中的一个组件,用于将输入的文本转化为索引时锁使用的文本特征向量。将文本分解,然后转化为特定的文本特征。
分片
分片就是将索引内部的数据分割成多个部分的机制,用于分布、存储和管理索引的数据 。允许索引被拆分为多个物理或逻辑部分从而实现分布式存储和处理数据的能力
面试常问:
- 索引文档的过程:
1. 协调节点默认使用文档ID参与计算,为路由提供合适的分片,转发请求
2. 分片所在节点接收到请求之后,将请求写入内存缓冲区,定时refresh到文件系统缓存,经过这一步既可以被搜索到了,当Filesystem cache中的数据写入到磁盘中时,才会清除掉translog,这个过程叫做flush;- es的删除:es中的文件并没有删除,每个段都有一个.del文件,删除是在这里进行标志,该文档仍然能够匹配到,但是会在结果中被过滤掉,后续在执行merge(周期性的将较小的段合并为一个较大的段)操作时,会被彻底清除掉
- 更新:每次更新都是先标记旧的文档为已删除,重新建立一个文档,并通过版本号来区分
- 搜索过程:
- Query Then Fetch
- 查询广播到每一个分片,分片本地执行搜索,建立一个优先队列,搜索只能搜到文件缓存的内容,所以并不是完全实时的
- 分片返回优先队列中文档的ID和排序值给协调节点,协调节点合并结果并排序
- 协调节点确定要取回的文档,然后向对应分片发送请求,最后协调节点返回给客户端
- 写过程:客户端选择一个node(作为协调节点)发请求,协调节点对文档进行路由,将请求转发给有这个文档的主分片的节点,主分片处理请求,并将将数据同步到副本中,之后协调节点根据完成状态,相应给客户端
- 读过程:协调节点根据doc id来查询,然后对doc id进行hash来确认到了哪个分片上,然后转发请求到对应的节点,使用负载均衡 来选取一个分片来处理,并转发给它,之后由这个节点来读取并返回给协调节点,协调节点返回给客户端
- es相对于mongodb,mysql的优势:1.全文检索,相关性排名 2.近实时性3.分布式处理4.数据分析 缺点:不支持事务
- DSL查询:由es提供的基于JSON的DSL语句
- 叶子查询:在特定字段中查询特定值
- 符合查询:以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式
- 指定高亮字段:
GET /{索引库名}/_search { "query": { "match": { "搜索字段": "搜索关键字" } }, "highlight": { "fields": { "高亮字段名称": { "pre_tags": "<em>", "post_tags": "</em>" } } } }
- 索引 :
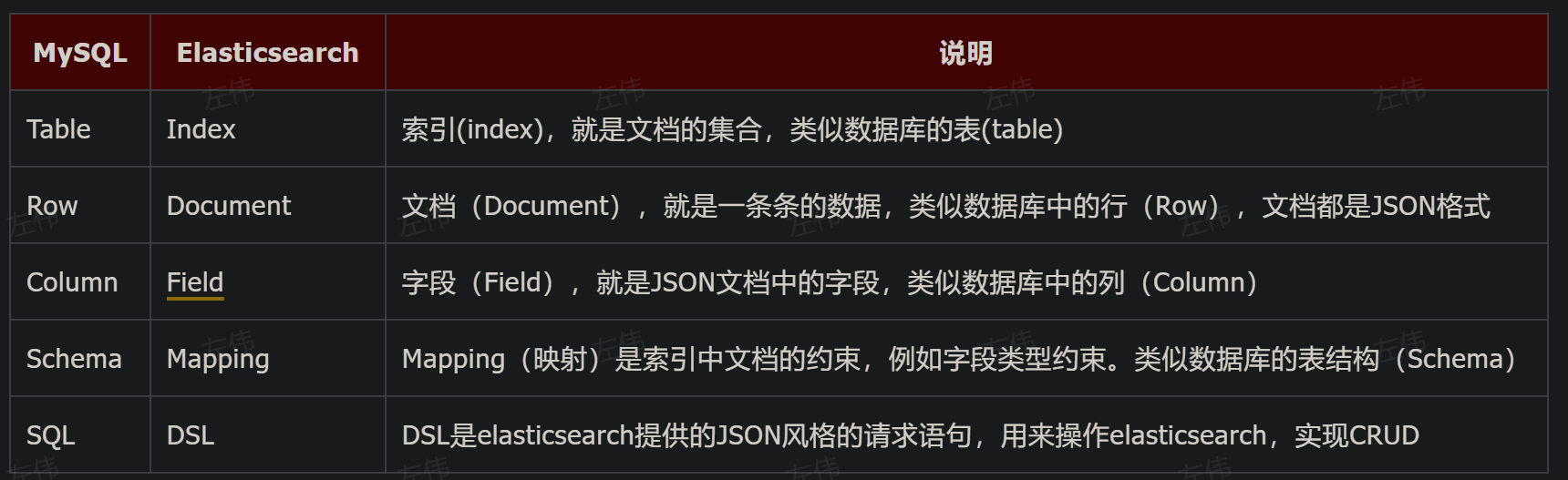
- 倒排索引和正排索引的区别:
- 正排索引是词条分到文档中
- 倒排索引是给词条统计文档

- 使用索引模板来加快索引的创建与属性设置
- 索引结构:倒排索引,使用分词,记录每一个分词出现的文档编号和在文档中出现的位置
- 搜索模块,路由值时,
- 索引搜索:
- 当搜索请求不带路由值时,接收到请求的节点成为协调节点,之后会选择使用的分片,之后会转发请求到拥有这些分片的节点上,每个分片产生一部分的局部结果汇总给协调节点,由协调节点汇总并排序之后返回。
- 使用路由条件进行搜索时,会将请求转发,之后直接由选中的节点进行返回
- 索引映射:
- 相当于指定了索引字段的名字和能够存储的类型
- 常用的数据类型:long , integer,short,byte,double,date(date可以在后面加一个format字段来执行时间的格式转换),keyword(用于保存原始文本,不会进行分词处理,用于精确匹配),boolean,geo_poinst经纬度类型,json格式(需要使用properties来指定内部对象的属性,实际存储时会使用 . 来表示层次结构),lists(数组)
- **如何既能快速匹配,又能精确匹配?**,给字段添加一个fields参数,然后在里面放一个keyword字段
- 在每一个字段的后面使用:”copy_to”:”复制出来的新字段名字” 可以做到复制这些字段的内容
- 倒排索引和正排索引的区别:
PUT mysougoulog/_mapping
{
"properties":{
"visitTime":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss || epoch_millis",
"ignore_malformed":true # 这个字段类型不对时,不写入,但是不影响其他字段的写入
}
}
}
# 二者兼得
PUT mysougoulog/_mapping
{
"properties":{
"key":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256 # 表示256个字符后面的内容被忽略,用来节省字段
}
}
}
}
}- 文档:
- CRUD时如何控制并发:
- 修改时,加上?if_seq_no = xx&if_primary_term=xx来使用乐观锁来控制,这两个字段是可以查到的,Elastisearch不支持事务管理
- 文本分析:
- 文本分析需要经过>=0个字符过滤器一个分词器,>=0 个分词过滤器
- 字符过滤器:对原始文档本进行转换,如去掉html标签
- 分词器:按照规则切分为单词,
- 分词过滤器:过滤掉一些没有用的词比如,的,删除停用词,也可进行分词的处理,如大小写转化,添加同义词
- 文本分析需要经过>=0个字符过滤器一个分词器,>=0 个分词过滤器
- CRUD时如何控制并发:
- 分词器:
- 创建倒排索引时对文档进行分词,用户搜索时,对输入的内容进行分词
- IK分词器:
- ik_smart 智能切分模式,粗粒度
- ik_max_word:最细切分,细粒度
数据:
- 搜索数据:
1. 精确搜索:搜索内容不经过文本分析直接进行文本匹配,适用于非text类,一般用于keyword字段
2. 全文检索:对检索内容和字段都会进行文本分析
3. 经纬度搜索,可以指定某个区域,例如⚪
4. 复合搜索:
- 布尔搜索:通过指定布尔逻辑条件来组织多条查询语句,同时满足整个布尔条件的才会被搜索出来
- 等等
- 父子关联:
- 因为es会把数据折叠起来,使用点,所以当一个对象有多个相同的key时,不能进行搜索了,例如goods商品,里面存放商品id和生产时间,就会被折叠 警告: 避免使用对象数组
- 解决方法:使用嵌套对象
- 使用join字段来明确父子关系
- 聚集统计:用于分析索引和文档,类似于mysql中的聚集操作- 集群:
- 新集群的产生:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理,主节点和数据节点不是一个
- 初始化投票配置:将配置文件中的候选节点写入投票配置,所有节点均可参与投票
- 选举主节点:超过半数就可成为主节点
- 发现集群中的其他节点,节点尝试连接主节点,连接上之后主节点把最新的状态发布到这些节点中
- 集群完成,对外启动统一的服务
- 集群状态的发布过程: 删除或者新增节点时触发
- 主节点把最新的集群状态发送到每个节点上,每个节点将数据保存并向主节点发送确认响应
- 主节点接收到半数以上的确认消息,开始提交,发送给每个节点通知使用最新的集群状态,子节点接收后发送确认响应,所有的都确认即可完成发布
- 响应超过时间限制,则删除这个子节点
- 新集群的产生:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理,主节点和数据节点不是一个
- 如何实现master选举?
- 对于所有可以成为master的节点,根据nodeId来排序,每个节点把自己直到的节点排一次序,然后选出第一个节点,认为他是master节点,入股某个节点到达可以成为超过master节点的一半,那就成为了master节点
- 脑裂问题:
- 设置最小主节点设置,设置的值应该是集群中节点总数的一半 + 1
- 读写一致:
- 版本控制:每个文档在ES中都有一个版本号,每次被修改后,版本号会增加,获取文档时,会同时或者它的版本号,更新时可以指定这个版本号,如果版本号不匹配,更新操作就会被拒绝
- 刷新与同步:向ES中写入数据时,数据先被写入内存缓冲区,然后每隔一段时间刷新一次或者缓冲区满时被刷新到磁盘后就可以被搜索到了,但是没有被写入磁盘,之后定期同步到磁盘中,同步后就是持久化存储了
- 副本和分片:只有主节点可以写入数据,然后被复制到副本分片中,读取数据时可以从任何一个包含该数据的分片中获取
- 设置写入确认级别
- 代码中使用:
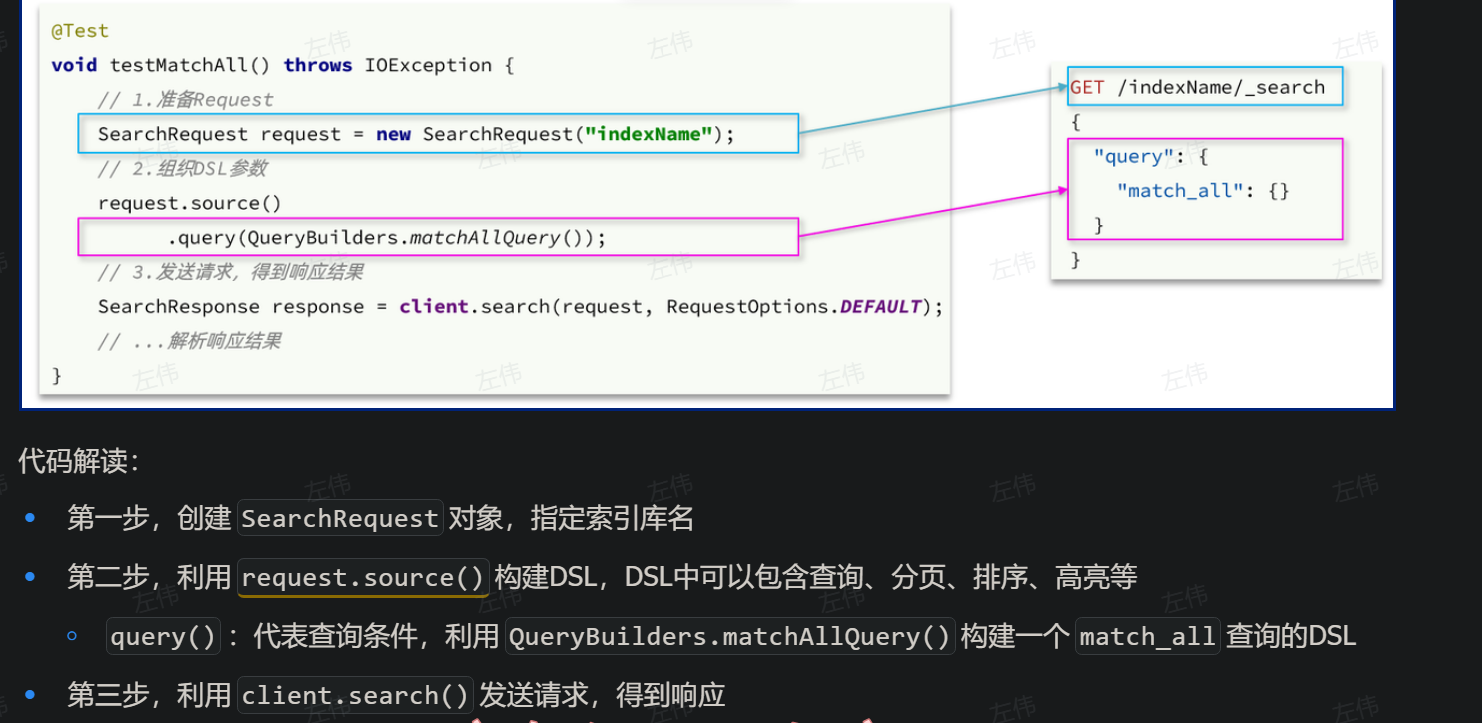
@Test void testMatchAll() throws IOException { // 1.创建Request SearchRequest request = new SearchRequest("items"); // 2.组织请求参数 request.source().query(QueryBuilders.matchAllQuery()); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response); } private void handleResponse(SearchResponse response) { SearchHits searchHits = response.getHits(); // 1.获取总条数 long total = searchHits.getTotalHits().value; System.out.println("共搜索到" + total + "条数据"); // 2.遍历结果数组 SearchHit[] hits = searchHits.getHits(); for (SearchHit hit : hits) { // 3.得到_source,也就是原始json文档 String source = hit.getSourceAsString(); // 4.反序列化并打印 ItemDoc item = JSONUtil.toBean(source, ItemDoc.class); System.out.println(item); } }
MeiliSearch->轻量级的ES
ES虽然扩展性和实时性都比较好,但是中小型项目中,ES有些过剩,对设备的要求也比较高,可以使用MeiliSearch来替代。同时MeiliSearch本身就支持中文搜索,而无需配置