ZooKeeper是什么
ZooKeeper是一个开源的分布式协调服务,设计目标是将哪些复杂且容易出错的分布式一致性服务封装起来,构成一个高效的原语(原语的执行必须连续且不可分割)集,并以一系列简单易用的接口提供给用户时使用
常用场景
- 命名服务:通过ZooKeepe的顺序节点生成全局唯一ID
- 数据发布/订阅:通过Watcher机制可以很方便的实现数据发布/订阅。其他机器可以通过监听ZooKeeper上的节点变化来实现配置的动态更新
- 分布式锁:通过创建唯一节点获得分布式锁,当获得锁的乙方执行完相关的代码或者挂掉后就释放,也需要使用Watcher机制
一些可以使用的场景
[[手写rpc#注册中心|使用ZooKeeper作为注册中心手写RPC]]
使用ZooKeeper作为分布式锁
重要概念
Data model
ZooKeeper数据模型使用层次化的多叉树形结构,每个节点上都可以存储数据,而且数据可以是数字、字符串、二进制序列。每个节点可以有N个子节点。每个数据节点叫做znode,是数据的最小单元,每个znode都有唯一的路径标识
znode存储的数据大小上线为1M,避免将大数据保存在ZooKeeper中
znode
分类:
- 持久(PERSISTENT)节点:一旦创建就存在即使ZooKeeper集群宕机,知道将其删除
- 临时(EPHEMERAL)节点:临时节点的声明周期与客户端会话绑定。会话节点小时则节点消失,临时节点只能作为叶子节点,不可创建属于自己的子节点。
- 持久顺序节点:除了具有持久节点外,子节点的名称还有顺序性。
znode的组成:
- stat:状态信息

- data:节点存放数据的具体内容
版本:
ZooKeeper会为每一个znode维护一个叫做Stat的数据结构
Stat中记录了三个znode相关的版本:
- dataVersion:当前znode节点的版本号
- cversion:当前znode子节点的版本
- aclVersion:当前znode的ACL的版本
ACL:权限控制
- CREATE:创建子节点
- READ:获取节点数据和列出其子节点
- WRITE:设置/更新节点数据
- DELETE:删除子节点
- ADMIN:设置节点ACL的权限
身份认证有四种方式: - world:默认,任何用户都可以无条件访问
- auth : 不适用任何id,代表任何已经认证的用户
- digest:用户名:密码的方式
- ip:对指定ip进行限制
Watcher(事件监听器)
ZooKeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发时,ZooKeeper服务器会将事件通知到感兴趣的客户端上。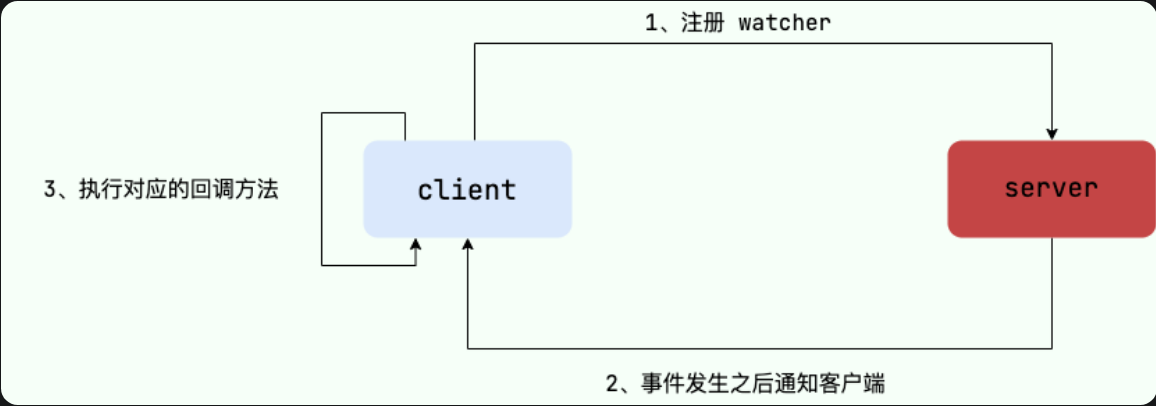
Session
ZooKeeper服务端与客户端之间的一个TCP长连接。客户端可以通过它进行心跳检测与服务器保持有效的会话,也能够向ZooKeeper服务器发送请求并接受响应。同时也能接收来在服务器的Watcher事件通知
集群
ZooKeeper将集群中节点的角色分为三类:
- Leader 为客户端提供读写服务,负责投票的发起和决议,更新系统状态
- Follower:只读,将写服务转发给Leader,参与选举过程的头票
- Observer:只读,写服务转发给Leader,不参与选举中的投票,也不参与”过半写成功”策略。 在不影响写性能的情况下提升集群的读性能。
Leader的选举过程
条件:
当Leader服务器出现网络中断、崩溃退出与重启等异常情况是,会进去Leader选举过程。
流程:
- Leader election 选举阶段:开始投票,只要有一个节点获得过半节点的票数即可作为准Leader
- Discovery发现阶段:followers跟准节点leader进行通信,同步followers最近接收的事务提议
- Synchronization 同步阶段:利用leader前一阶段获得的最新提议历史,同步集群中所有的副本,同步之后,准leader成为正式节点
- Broadcast 广播阶段:Zookeeper集群正式对外提供事务服务,leader及逆行消息广播,如果有新的节点加入,还需要进行同步
节点的状态:
- LOOKING:寻找Leader
- LEADING:Leader状态,对应的节点成为Leader
- FOLLOWING:对应的节点成为Follower
- OBSERVING:对应的节点成为OBSERVING
脑裂问题通过过半机制解决
ZAB协议
ZooKeeper Atomic Broadcast,原子广播
###3 模式
- 崩溃恢复:启动或者出现异常状况时,进行崩溃恢复状态,当选举出新的Leader节点,并且已经进行状态同步之后,退出恢复状态。
- 消息广播:当集群中已经完成状态通过,整个服务架构进入消息广播模式。新加入的节点会自觉进入数据恢复状态。
常见的Java API
curator-x-discovery是 Apache Curator 库中的一个模块,用于简化与 Apache ZooKeeper 交互时的服务发现和注册功能
ServiceDiscovery 用于管理服务的注册和发现
ServiceInstance 描述一个服务的信息
CuratorFramework zk连接客户端