个人博客
个人随笔:https://www.yuque.com/qingqiufw
https://zuofw.github.io/
本项目详细介绍和实现:
手写rpc | QingQiu’Blog (zuofw.github.io)
源码地址:Zuofw/zuofw-rpc: 一个废物的手写rpc (github.com)
项目介绍
zuofw-rpc是一款基于Java、Netty、Zookeeper实现的RPC通信框架,它具有以下核心特性:
- 使用”微内核+可插拔”架构,通过自定义SPI加载机制,支持缓存,动态替代扩展点组件
- 灵活使用设计模式来提高系统可扩展性,如单例模式、工厂模式、建造者模式
- 实现服务调用负载均衡机制,支持轮询、随机、一致性哈希算法,优化调用体验
- 通过自定义通信协议、支持多种序列化方式,同时实现Gzip压缩,提高网络传输效率。
- 实现自定义request - response模型,在异步通信条件下确保消息的请求和响应成功
- 基于自定义starter实现,优化SpringBoot环境下的使用。
基本架构
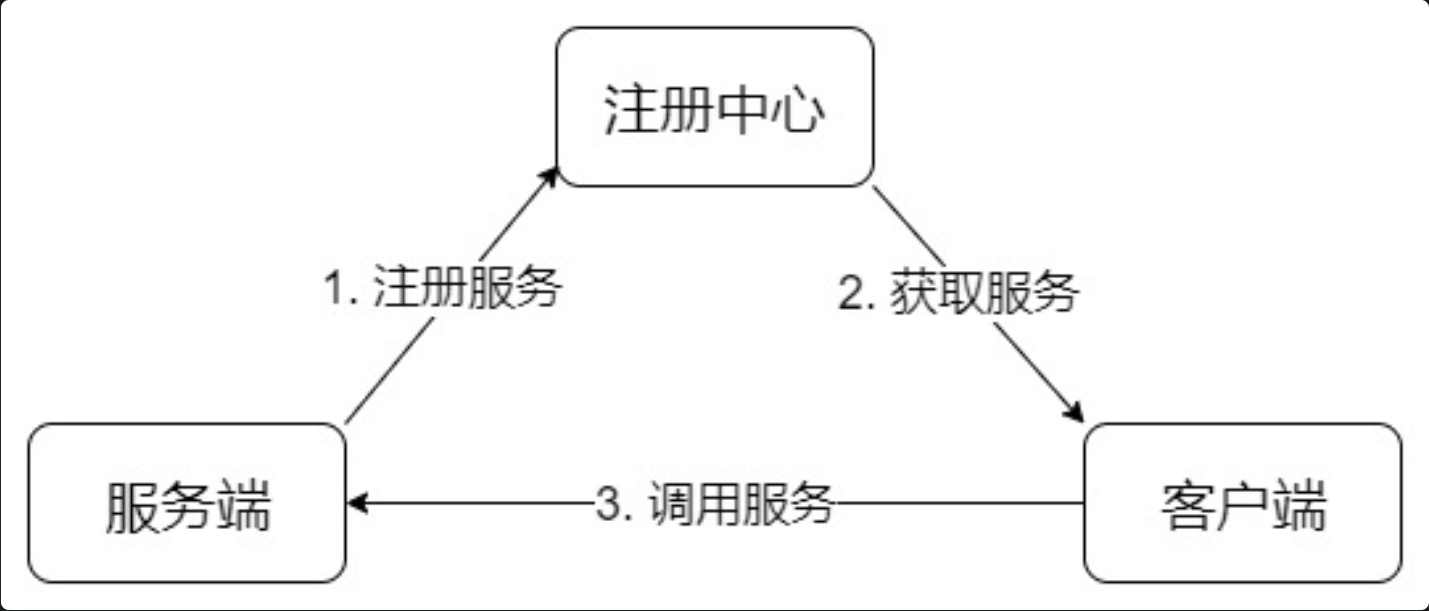
- 注册中心,用于服务注册和获取
- 服务端:提供服务的一方Provider
- 客户端:调用服务的一方Consumer
基本流程: - 服务端把服务信息注册到注册中心上,一般包括服务端地址、接口类和方法
- 客户端从注册中心获取对应的服务信息
- 客户端根据服务的信息,通过网络调用服务端的接口
快速开始
- SpringBoot环境下引入依赖
<dependency> <groupId>com.zuofw.rpc.spring.boot.starter</groupId> <artifactId>zuofw-rpc-spring-boot-starter</artifactId> <version>0.0.1-SNAPSHOT</version> </dependency> - 在启动类上加上
@EnableZuofwRpc(needServer = false)服务提供者将false改为true@SpringBootApplication @EnableZuofwRpc(needServer = false) public class ZuofwRpcSpringConsumerApplication { public static void main(String[] args) { SpringApplication.run(ZuofwRpcSpringConsumerApplication.class, args); } } - 服务提供者在实现类上加上
@ZuofwRPCService注解@Service @ZuofwRPCService public class UserserviceImpl implements UserService { @Override public User getUser(User user) { System.out.println("服务端接收到请求,请求参数为:" + user); return user; } } - 服务调用者在需要使用的服务上加上
@ZuofwRPCReference即可使用@ZuofwRPCReference private UserService userService; public void sayHello(String name) { User user = new User(); user.setName("zuofw"); User resultUser = userService.getUser(user); System.out.println("consumer get User:" + resultUser.getName()); }
设计
- 注册中心:如何实现或者使用哪个
- 动态代理:客户端调用接口,需要框架去根据接口去远程调用服务,需要使用动态代理,常见的有 JDK Proxy、CGLIb、Javassist等
- 网络传输:RPC实际上是网络传输,使用Netty
- 自定义协议:网络传输需要搭配良好的协议提高传输效率
- 序列化:将对象转化为字节流/转换回对象,网络传输只能传输字节流,所以需要实现序列化。
- 负载均衡:请求大量调用时,服务端如何选择?
- 集群容错:当请求异常时,如何处理? 报错?重试?还是请求其他服务?
开发过程
数据模型
- 请求
public class RPCRequest implements Serializable { /** * 服务名称 */ private String serviceName; /** * 方法名称 */ private String methodName; /** * 参数类型列表 * Class是Java反射机制中的类,用于描述类的类型信息 * 为何使用Class<?>而不是Class<T>? * Class<?>表示未知类型,而Class<T>表示具体类型 */ private Class<?>[] parameterTypes; /** * 参数列表 */ private Object[] args; } - 响应
public class RPCResponse implements Serializable { /** * 请求ID */ private long requestId; /** * 响应数据 */ private Object data; /** * 响应数据类型 */ private Class<?> dataType; /** * 响应信息 */ private String message; /** * 异常信息 */ private Exception exception; }
初始化配置
- 配置定义
@Data public class RPCConfig { private String name = "zuofw-rpc"; private String version = "1.0"; private String serverHost = "127.0.0.1"; private Integer serverPort = 8080; private boolean mock = false; /** * 序列化器 */ private String serializer = SerializerKeys.JDK; private RegistryConfig registryConfig = new RegistryConfig(); } // 注册中心配置 @Data public class RegistryConfig { /** * 注册中心类型 */ private String registry = "zookeeper"; /** * 地址 */ private String address = "http://192.168.61.190:2181"; /** * 用户名 */ private String username; /** * 密码 */ private String password; /** * 超时时间 */ private Long timeout = 100000L; } - 初始化过程(重点):读取properties文件中的内容,然后填入我们配置中即可
- init()实现
public static void init() { RPCConfig newRpcConfig; try { newRpcConfig = ConfigUtils.loadConfig(RPCConfig.class, RPCConstant.DEFAULT_CONFIG_PREFIX); } catch (Exception e) { // 读取配置文件失败,使用默认配置 System.out.println("读取文件失败"); log.info("读取文件配置失败"); newRpcConfig = new RPCConfig(); } System.out.println("newRpcConfig: " + newRpcConfig); init(newRpcConfig); } - 读取文件实现,使用hutool工具
public static <T> T loadConfig(Class<T> tClass, String prefix, String environment) { StringBuilder configFileBuilder = new StringBuilder("application"); // 如果有环境,加载对应环境的配置 if (StrUtil.isNotBlank(environment)) { // application-dev.properties configFileBuilder.append("-").append(environment); } configFileBuilder.append(".properties"); //读取yaml配置文件 Props props = new Props(configFileBuilder.toString()); return props.toBean(tClass, prefix); }
- 实际使用:
RPCApplication.init();
服务注册
基本接口定义
public interface Registry {
/**
* 初始化
*
* @param registryConfig
*/
void init(RegistryConfig registryConfig);
/**
* 注册服务 服务端
*
* @param serviceMetaInfo
* @throws Exception
*/
void register(ServiceMetaInfo serviceMetaInfo) throws Exception;
/**
* 取消注册服务 服务端
*
* @param serviceMetaInfo
*/
void unRegister(ServiceMetaInfo serviceMetaInfo);
/**
* 服务发现 获取某服务的所有节点 客户端 消费端
*
* @param serviceKey
* @return
*/
List<ServiceMetaInfo> serviceDiscovery(String serviceKey);
}- 本地注册
本地是实现的核心思路就是使用一个ConcurrentHashMap作为注册中心,将服务信息保存在里面。 - ZooKeeper实现
ZooKeeper是一个开源的分布式协调服务,设计目标是将哪些复杂且容易出错的分布式一致性服务封装起来,构成一个高效的原语(原语的执行必须连续且不可分割)集,并以一系列简单易用的接口提供给用户时使用
首先引入依赖
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-x-discovery</artifactId> <version>5.6.0</version> </dependency>我们使用curator框架,而不是官方提供的原生方案。因为这个框架简化了与ZooKeeper的交互。
简化的API:提供了更高层次的API,简化了与ZooKeeper的交互。
内置的重试机制:自动处理ZooKeeper的连接和会话超时,提供了内置的重试机制。
服务发现和注册:提供了服务发现和注册的功能,简化了分布式系统中服务的管理。
集成度高:与Curator的其他模块无缝集成,提供了更多的功能和灵活性。核心实现
@Data @Slf4j public class ZooKeeperRegistry implements Registry { // zk客户端 private CuratorFramework client; // 服务发现 private ServiceDiscovery<ServiceMetaInfo> serviceDiscovery; // 根节点 private static final String ZK_ROOT_PATH = "/rpc/zk"; /** * 本地注册节点 key 集合 用于维护续期 */ private final Set<String> localRegisterNodeKeySet = new HashSet<>(); /** * 注册中心缓存 */ private final RegistryInstanceCache registryServiceCache = new RegistryInstanceCache(); /** * 监听的key集合, 用于续期 */ private final Set<String> watchingKeySet = new HashSet<>(); @Override public void init(RegistryConfig registryConfig) { //Client 是 Curator 提供的一个类,用于管理与 Zookeeper 的连接,它提供了一些方法用于创建、删除、读取节点等操作。 client = CuratorFrameworkFactory.builder() .connectString(registryConfig.getAddress()) .retryPolicy(new ExponentialBackoffRetry(Math.toIntExact(registryConfig.getTimeout()), 3)) .build(); // 构建serviceDiscovery 实例 //Discovery 是用于管理服务的注册和发现的组件,它提供了服务注册、服务发现、服务状态监控等功能。 serviceDiscovery = ServiceDiscoveryBuilder.builder(ServiceMetaInfo.class) .client(client) .basePath(ZK_ROOT_PATH) .serializer(new JsonInstanceSerializer<>(ServiceMetaInfo.class)) .build(); try { client.start(); serviceDiscovery.start(); } catch (Exception e) { throw new RuntimeException(e); } } @Override public void register(ServiceMetaInfo serviceMetaInfo) throws Exception { //注册过去 serviceDiscovery.registerService(buildServiceInstance(serviceMetaInfo)); log.info("服务注册成功:{}", serviceMetaInfo); String registerKey = ZK_ROOT_PATH + "/" + serviceMetaInfo.getServiceNodeKey(); // 添加节点信息到本地缓存,方便续期 localRegisterNodeKeySet.add(registerKey); } @Override public void unRegister(ServiceMetaInfo serviceMetaInfo) { try { serviceDiscovery.unregisterService(buildServiceInstance(serviceMetaInfo)); String registerKey = ZK_ROOT_PATH + "/" + serviceMetaInfo.getServiceNodeKey(); localRegisterNodeKeySet.remove(registerKey); } catch (Exception e) { throw new RuntimeException(e); } } @Override public List<ServiceMetaInfo> serviceDiscovery(String serviceKey) { // 优先从缓存中获取 List<ServiceMetaInfo> serviceMetaInfoList = registryServiceCache.getCache(); //!= null 和 isEmpty()和 isBlank()的区别, isBlank()是Apache commons-lang3包中的方法,用来判断字符串是否为空或者空格 //isBlank()方法是对字符串进行处理后再判断是否为空,而isEmpty()方法是直接判断字符串是否为空,不做任何处理。 if(serviceMetaInfoList != null && !serviceMetaInfoList.isEmpty()){ return serviceMetaInfoList; } try { // 从zk中获取 List<ServiceMetaInfo> collect = serviceDiscovery.queryForInstances(serviceKey) .stream() .map(ServiceInstance::getPayload) .collect(Collectors.toList()); // 缓存 registryServiceCache.setCache(collect); return collect; } catch (Exception e) { throw new RuntimeException(e); } } @Override public void destroy() { log.info("当前服务销毁"); try(CuratorFramework client = this.client) { for (String key : localRegisterNodeKeySet) { try { client.delete().forPath(key); } catch (Exception e) { throw new RuntimeException(key + "下线失败", e); } } } } @Override public void heartbeat() { } @Override public void watch(String serviceNodeKey) { //监听节点 String watchKey = ZK_ROOT_PATH + "/" + serviceNodeKey; boolean newWatch = watchingKeySet.add(watchKey); //forDeletes()方法用于监听节点的删除事件,当节点被删除时,会触发监听器的回调方法。 //forChanges()方法用于监听节点的变化事件,当节点的数据发生变化时,会触发监听器的回调方法。 if(newWatch) { //cache是Curator提供的一个类,用于监听节点的变化,包括节点的增加、删除、数据的变化等。 CuratorCache curatorCache = CuratorCache.build(client, watchKey); curatorCache.start(); curatorCache.listenable().addListener( CuratorCacheListener.builder() .forDeletes(childData -> registryServiceCache.clearCache()) .forChanges((oldData, data) -> registryServiceCache.clearCache()) .build() ); } } private ServiceInstance<ServiceMetaInfo> buildServiceInstance(ServiceMetaInfo serviceMetaInfo) throws Exception { //ServiceInstance 是 Curator 提供的一个类,用于描述一个服务实例的信息,包括服务名称、服务地址、服务端口等。 String serviceAddress = serviceMetaInfo.getServiceHost() + ":" + serviceMetaInfo.getServicePort(); return ServiceInstance .<ServiceMetaInfo>builder() .id(serviceAddress) .name(serviceMetaInfo.getServiceKey()) .address(serviceAddress) .port(serviceMetaInfo.getServicePort()) .payload(serviceMetaInfo) .build(); } }服务注册
构造一个服务实例,然后使用serviceDiscovery注册即可@Override public void register(ServiceMetaInfo serviceMetaInfo) throws Exception { //注册过去 serviceDiscovery.registerService(buildServiceInstance(serviceMetaInfo)); log.info("服务注册成功:{}", serviceMetaInfo); String registerKey = ZK_ROOT_PATH + "/" + serviceMetaInfo.getServiceNodeKey(); // 添加节点信息到本地缓存,方便续期 localRegisterNodeKeySet.add(registerKey); } private ServiceInstance<ServiceMetaInfo> buildServiceInstance(ServiceMetaInfo serviceMetaInfo) throws Exception { //ServiceInstance 是 Curator 提供的一个类,用于描述一个服务实例的信息,包括服务名称、服务地址、服务端口等。 String serviceAddress = serviceMetaInfo.getServiceHost() + ":" + serviceMetaInfo.getServicePort(); return ServiceInstance .<ServiceMetaInfo>builder() .id(serviceAddress) .name(serviceMetaInfo.getServiceKey()) .address(serviceAddress) .port(serviceMetaInfo.getServicePort()) .payload(serviceMetaInfo) .build(); }初始化连接客户端
@Override public void init(RegistryConfig registryConfig) { //Client 是 Curator 提供的一个类,用于管理与 Zookeeper 的连接,它提供了一些方法用于创建、删除、读取节点等操作。 client = CuratorFrameworkFactory.builder() .connectString(registryConfig.getAddress()) .retryPolicy(new ExponentialBackoffRetry(Math.toIntExact(registryConfig.getTimeout()), 3)) .build(); // 构建serviceDiscovery 实例 //Discovery 是用于管理服务的注册和发现的组件,它提供了服务注册、服务发现、服务状态监控等功能。 serviceDiscovery = ServiceDiscoveryBuilder.builder(ServiceMetaInfo.class) .client(client) .basePath(ZK_ROOT_PATH) .serializer(new JsonInstanceSerializer<>(ServiceMetaInfo.class)) .build(); try { client.start(); serviceDiscovery.start(); } catch (Exception e) { throw new RuntimeException(e); } }
RPC调用(代理)
RPC的调用实际上就是由框架去代理被注解的对象去远程调用服务。
代理分为动态代理和静态代理
二者区别:
静态代理实际上在编译期间就已经生成对应的字节码文件,需要手动编写,实现与目标类相同的接口,在内部调用目标类的方法,实际就是由代理类去包裹实现类,并在代理类内部去调用被代理类。
// 接口
public interface Service {
void perform();
}
// 目标类
public class RealService implements Service {
@Override
public void perform() {
System.out.println("Performing service...");
}
}
// 代理类
public class StaticProxyService implements Service {
private final RealService realService;
public StaticProxyService(RealService realService) {
this.realService = realService;
}
@Override
public void perform() {
System.out.println("Before performing service...");
realService.perform();
System.out.println("After performing service...");
}
}
// 使用静态代理
public class StaticProxyDemo {
public static void main(String[] args) {
RealService realService = new RealService();
Service proxyService = new StaticProxyService(realService);
proxyService.perform();
}
}JDK动态代理实现
创建接口:定义一个接口,声明需要代理的方法。
实现接口:创建一个类实现该接口。
创建代理类:实现InvocationHandler接口,重写invoke方法。
生成代理对象:使用Proxy.newProxyInstance方法生成代理对象
//实际interface
interface A {
void say();
}
//代理类
class AProxy implements A {
void say() {
system.out.println("A");
}
}
//实际调用
实际实现:使用工厂模式来获取具体的代理类
public class ServiceProxyFactory {
public static <T> T getProxy(Class<T> serviceClass) {
// 三个参数分别是:ClassLoader指定使用哪个类加载器来加载代理类,一般使用加载目标类的方式来加载。
// new Class[]{} 一个数组,包括代理列要实习那的接口,这里传入的是目标类实现的接口。
// new ServiceProxy() 自定义的InvocationHandler实现类。
return (T) Proxy.newProxyInstance(
serviceClass.getClassLoader(),
new Class[]{serviceClass},
new ServiceProxy()
);
}
}动态代理->jdk实现
public class ServiceProxy implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 参数分别是: proxy 代理类, method 调用的方法, args方法的参数
// 构造请求
JDKSerializer jdkSerializer = new JDKSerializer();
RPCRequst rpcRequst = RPCRequst.builder()
.serviceName(method.getDeclaringClass().getName())
.methodName(method.getName())
.parameterTypes(method.getParameterTypes())
.args(args)
.build();
try {
byte[] bodyBytes = jdkSerializer.serialize(rpcRequst);
// 发送请求
try(HttpResponse httpResponse = HttpRequest.post("http://localhost:8080").body(bodyBytes).execute()) {
byte[] result = httpResponse.bodyBytes();
RPCResponse response = jdkSerializer.deserialize(result, RPCResponse.class);
return response.getData();
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}实际使用:
public static void main(String[] args) {
UserService userService = ServiceProxyFactory.getProxy(UserService.class);
User user = new User();
user.setName("zuofw");
User newUser = userService.getUser(user);
if (newUser != null) {
System.out.println("Get user success, name: " + newUser.getName());
} else {
System.out.println("Get user failed");
}
RPCConfig rpcConfig = ConfigUtils.loadConfig(RPCConfig.class, "rpc");
System.out.println(rpcConfig);
// testMock();
}- jdk动态代理的原理:我们通过实现 InvocationHandler来实现自定义代理处理器,当我们调用动态代理对象代理的对象的方法时,这个方法的调用就会被转发到我们实现的这个接口的invoke方法来调用,从而实现动态进行一些操作。
补充:
CGLIB动态代理机制
JDK动态代理的一个缺点:
只能代理实现了接口的类,Spring AOP中就使用到了CGLIB来进行动态代理->如果目标实现了接口,默认使用JDK代理,否则使用CGLIB动态代理。
CGLIB是一个基于ASM的字节码生成库,允许在运行时对字节码进行修改和动态生成。 CGLIB在Java 9及更高版本中无法访问某些受保护的JDK内部API导致的。具体来说,java.lang.ClassLoader.defineClass方法在Java 9及更高版本中变得不可访问。推荐使用JDK代理或者其他代理框架
实例:
@Slf4j
public class CGServiceProxy implements MethodInterceptor {
private final Invoker invoker = InvokerFactory.getInstance("netty");
// 获取代理类
public Object getProxy(Class<?> clazz) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(clazz);
enhancer.setCallback(this);
return enhancer.create();
}
// 拦截方法
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
// 构造请求
RPCRequest rpcRequest = RPCRequest.builder()
.serviceName(method.getDeclaringClass().getName())
.methodName(method.getName())
.parameterTypes(method.getParameterTypes())
.args(args)
.build();
RPCResult invoke = invoker.invoke(rpcRequest);
log.info("invoke result:{}", invoke.getData());
RPCResponse response = (RPCResponse) invoke.getData();
return response.getData();
}
}序列化器实现
- JDK原生序列化:
优点:使用方便,无需引入额外依赖
缺点:速度慢,占空间、有安全问题 - JSON:
优点:跨语言,使用简单,易读
缺点:序列化结果较大,性能一般,可能存在反序列化漏洞,不能很好处理负载的数据结构和循环引用,导致性能下降或者序列化失败 - Kryo
优点:高性能,体积小,适合分布式
去点:不跨语言,只有Java,序列化格式复杂
如何实现?
使用interface 来定义,方便扩展和使用
当使用泛型进行序列化时,会出现泛型擦除,原始类型信息在编译时会被擦除掉,使得使用泛型作为方法参数和返回值时,实际上类型是Object类型public interface Serializer { /* * @description: 序列化 * @author zuofw * @date: 2024/9/6 10:28 * @param obj * @return byte[] */ <T> byte[] serialize(T obj) throws IOException; /** * 反序列化 * @param bytes * @param clazz * @return * @param <T> * @throws IOException */ //<T>是泛型方法的声明,表示这是一个泛型方法,T是泛型参数,表示这个方法是一个泛型方法,T是泛型参数,表示这个方法可以接受任意类型的参数 <T> T deserialize(byte[] bytes, Class<T> clazz) throws IOException; }
- JDK实现
public class JDKSerializer implements Serializer { /* * @description: JDK实现 * @author zuofw * @date: 2024/9/6 11:06 * @param obj * @return byte[] */ @Override public <T> byte[] serialize(T obj) throws IOException { //这是一个字节数组输出流,数据会被写到一个字节数组中 ByteArrayOutputStream outputStream = new ByteArrayOutputStream(); //将对象写入到字节数组输出流中 ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream); objectOutputStream.writeObject(obj); objectOutputStream.close(); return outputStream.toByteArray(); } @Override public <T> T deserialize(byte[] bytes, Class<T> clazz) throws IOException { ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes); ObjectInputStream objectInputStream = new ObjectInputStream(inputStream); try { return (T) objectInputStream.readObject(); } catch (ClassNotFoundException e) { throw new IOException(e); } finally { objectInputStream.close(); } } } - JSON实现
public class JSONSerializer implements Serializer{ //全局唯一 private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper(); @Override public <T> byte[] serialize(T obj) throws IOException { //将对象转换为字节数组 return OBJECT_MAPPER.writeValueAsBytes(obj); } @Override public <T> T deserialize(byte[] bytes, Class<T> clazz) throws IOException { T obj = OBJECT_MAPPER.readValue(bytes, clazz); if(obj instanceof RPCRequest) { return handleRequest((RPCRequest) obj, clazz); } else if(obj instanceof RPCResponse){ return handleResponse((RPCResponse) obj,clazz); } return obj; } public <T> T handleResponse(RPCResponse rpcResponse, Class<T> type) throws IOException { //为什么要将data转换为字节数组,再转换为对象? //因为data是一个Object类型,我们不知道它的具体类型,所以我们需要将它转换为字节数组,再转换为具体的对象 //将data转换为字节数组 byte[] bytes = OBJECT_MAPPER.writeValueAsBytes(rpcResponse.getData()); //将字节数组转换为对象 rpcResponse.setData(OBJECT_MAPPER.readValue(bytes, rpcResponse.getDataType())); // 通过反射创建对象 return type.cast(rpcResponse); } public <T> T handleRequest(RPCRequest rpcRequest, Class<T> type) throws IOException { // 获取参数类型 Class<?>[] parameterTypes = rpcRequest.getParameterTypes(); // 获取参数 Object[] args = rpcRequest.getArgs(); // 循环处理每个参数的类型 for (int i = 0; i < parameterTypes.length; i++) { Class<?> clazz = parameterTypes[i]; // 如果类型不同,需要重新转换 //isAssignableFrom()方法是用来判断一个类Class1和另一个类Class2是否相同或是另一个类的超类或接口 if (!clazz.isAssignableFrom(args[i].getClass())) { byte[] bytes = OBJECT_MAPPER.writeValueAsBytes(args[i]); args[i] = OBJECT_MAPPER.readValue(bytes, clazz); } } return type.cast(rpcRequest); } }
实现方式:
- 引入依赖
<dependency> <groupId>com.github.jsonzou</groupId> <artifactId>jmockdata</artifactId> <version>4.3.0</version> </dependency> - 实现代理接口
/** * Mock 服务代理 JDK动态代理 */ @Slf4j public class MockServiceProxy implements InvocationHandler { /** * 调用代理 * * @throws Throwable */ @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // 根据方法的返回值类型,生成特定的默认值对象 Class<?> returnType = method.getReturnType(); Object mockData = JMockData.mock(returnType); log.info("mockData:{}", mockData); return mockData; } }
SPI机制->热拔插
面向对象鼓励模块之间基于接口而非具体实现变成来降低耦合,支持开闭原则(对扩展开放,对修改封闭),但是直接依赖实现,在替代实现时需要修改代码,违背了开闭原则。SPI因此诞生。
SPI(Service Provider Interface 服务提供者的接口)与API(应用提供的接口,供外部调用)类似,是JDK内置的一种服务提供发现机制,可以用来启用框架拓展和替换组件。SPI 允许框架或应用程序通过接口定义服务,并允许第三方或用户提供这些服务的实现。SPI 的主要目的是提供一种可插拔的架构,使得服务的实现可以在运行时动态加载和替换。类似于IOC,只不过将装配的控制移交到了程序之外
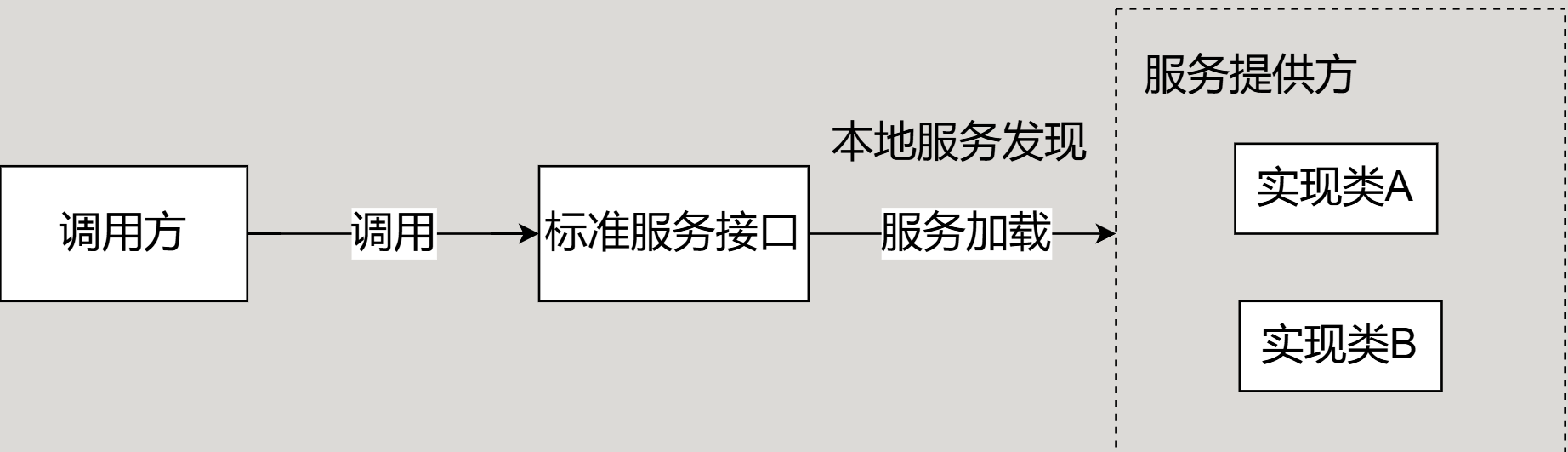
实现热拔插的流程
- 服务的提供者实现一种接口的实现,然后在classpath路径下的META-INF/services/目录里创建一个以服务接口命名的文件。里面填写需要加载的实现类的全限定符
- 使用自定义加载,加载实现的接口
最核心的就是通过类的全限定符去找到这个类,然后通过反射来进行加载
自定义加载实现:
public calss SPILoader {
// 只展示核心方法,完整内容可以去看源码
// 参数:要加载的类型
public static Map<String,Class<?>> load(Class<?> loadClass) {
log.info("加载类型为{} 的SPI",loadClass.getName());
//扫描路径,用户自定义的SPI优先级高于系统SPI
Map<String, Class<?>> keyClassMap = new HashMap<>();
// SCANS_DIRS是我们自定义的加载路径
for(String dir : SCANS_DIRS) {
log.info("扫描路径为{}",dir);
//获取资源
log.info("资源为{}",dir + loadClass.getName());
List<URL> resources = ResourceUtil.getResources(dir + loadClass.getName());
//URL是什么类型,为什么要用它,因为它是一个统一资源定位符,可以用来定位资源
//url.openStream()是什么意思,是打开一个输入流,可以用来读取资源
for(URL resource : resources) {
try {
//打开一个输入流
InputStreamReader inputStreamReader = new InputStreamReader(resource.openStream());
//缓冲读取字符流
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line;
while ((line = bufferedReader.readLine()) != null) {
String[] splits = line.split("=");
if(splits.length < 2) {
log.error("SPI配置文件格式错误");
continue;
}
String key = splits[0];
String className = splits[1];
//Class.forNam用于动态加载一个类
keyClassMap.put(key, Class.forName(className));
}
} catch (IOException e) {
throw new RuntimeException("加载SPI配置文件失败",e);
} catch (ClassNotFoundException e) {
throw new RuntimeException("需要加载的类不存在",e);
}
}
}
loaderMap.put(loadClass.getName(), keyClassMap);
return keyClassMap;
}
}获取实例:
public static <T> T getInstance(Class<?> tClass, String key) {
// 获得类名
String tClassName = tClass.getName();
Map<String, Class<?>> keyClassMap = loaderMap.get(tClassName);
if (keyClassMap.isEmpty()) {
throw new RuntimeException(String.format("SpiLoader 未加载 %s 类型", tClassName));
}
if (!keyClassMap.containsKey(key)) {
throw new RuntimeException(String.format("SpiLoader 的 %s 不存在 key= %s", tClassName, key));
}
// 通过类名获得实现类
Class<?> implClass = keyClassMap.get(key);
// 从缓存中加载指定类型的实例
String implClassName = implClass.getName();
// 判断缓存中是否有实例
if (!instanceCache.containsKey(implClassName)) {
try {
instanceCache.put(implClassName, implClass.getDeclaredConstructor().newInstance());
} catch (InstantiationException | IllegalAccessException | NoSuchMethodException | InvocationTargetException e) {
throw new RuntimeException(String.format("实例化 %s 失败", implClassName), e);
}
}
return (T) instanceCache.get(implClassName);
}文件内容:

核心流程:
- 通过URL来定位文件位置
- 读取文件内容,将类的信息加载到map中
- 获取实例时根据类型来加载具体的类型和是实现类。
- 核心还是反射。
常见的反射使用方法
Class.forNmae(className)根据传入的类名,动态加载并返回一个Class对象,不会新建一个对象
Class.newInstance()或者通过构造函数反射来进行实例化一个新的对象采用加载Class对象和创建实例分离的方式,使得SPI只有在需要实现类的时候才触发实例化,更加高效灵活
//通过类名获得实现类
Class<?> implClass = keyClassMap.get(key);
// 从缓存中加载指定类型的实例
String implClassName = implClass.getName();
//判断缓存中是否有实例
if(!instanceCache.containsKey(implClassName)) {
try {
instanceCache.put(implClassName, (Objects) implClass.getDeclaredConstructor().newInstance());
} catch (Exception e) {
throw new RuntimeException(String.format("实例化 %s 失败", implClassName), e);
}
}
return (T) instanceCache.get(implClassName);自定义协议
RPC框架使用Netty通信时,实际上是将数据转化为ByteBuf的方式放松的,那么该如何转化?如果直接转化会出现粘包和拆包问题
什么是粘包和拆包问题
使用TCP时,使用的是没有界限的二进制流传输,TCP会根据缓冲区来进行数据包的划分,但是划分不一定就是实际的一个业务上的完整的包,所以会出现接收端将多个数据包合并成一个数据包或者将一个数据包拆分成多个包
如何解决?
- 固定长度的消息
- 使用特定的分隔符
- 消息头:包含消息的长度。
实现:
结构设计
参考:从零开始实现简单 RPC 框架 7:网络通信之自定义协议(粘包拆包、编解码) - 小新是也 - 博客园 (cnblogs.com)自定义协议(重点) | 手写RPC框架 (yunfeidog.github.io)
int占用4个自己额,byte占用1个字节
消息所需要的信息
- 魔数:标识是我们自定义的RPC消息,同时用来校验消息是否合法 1B
- 版本号:1B
- 序列化类型:标识使用的序列化方式,用来方便同意序列化和反序列化 1B
- 类型:标识消息的类型,普通请求,心跳,响应 1B
- 状态:标识消息是否成功推送 1B
- 请求id:标识当前消息的唯一标识 8B
- 压缩类型:将字节流进行压缩,传输更快,但是会消耗CPU资源。 1B
- 消息长度:标识消息的长度,解决粘包 4B
- 消息体:
所以请求占用字节为 18B
问题: [[JVM学习#内部类引用外部类|静态内部类的好处]]
消息定义
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
// 使用T泛型,可以接收任意类型的消息体
public class ZMessage<T> {
/**
* 请求头
*/
private Header header;
/**
* body
*/
private T body;
/**
* 使用静态内部类,定义请求头,优点是可以直接通过ZMessage.Header访问,方便解耦,内部类也不会出现外部引用
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public static class Header {
/**
* 魔数
*/
private byte magic;
/**
* 版本
*/
private byte version;
/**
* 序列化器
*/
private byte serialize;
/**
* 消息类型
*/
private byte type;
/**
* 消息状态
*/
private byte status;
/**
* 请求id
*/
private long requestId;
/**
* 压缩格式
*/
private byte compress;
/**
* 消息体长度
*/
private int bodyLength;
}
}解压缩
- 接口定义
public interface Compressor { /** * 压缩 * * @param bytes 压缩前的字节数组 * @return 压缩后的字节数组 */ byte[] compress(byte[] bytes); /** * 解压 * * @param bytes 解压前的字节数组 * @return 解压后的字节数组 */ byte[] decompress(byte[] bytes); } - gzip实现
public class GzipCompressor implements Compressor{ /** * 4k 缓冲区 */ private static final int BUFFER_SIZE = 4096; @Override public byte[] compress(byte[] bytes) { Assert.notNull("bytes should not null"); try (ByteArrayOutputStream out = new ByteArrayOutputStream(); GZIPOutputStream gzip = new GZIPOutputStream(out)) { gzip.write(bytes); gzip.flush(); gzip.finish(); return out.toByteArray(); } catch (IOException e) { throw new RuntimeException("gzip compress error", e); } } @Override public byte[] decompress(byte[] bytes) { Assert.notNull("bytes should not null"); try (ByteArrayOutputStream out = new ByteArrayOutputStream(); GZIPInputStream gunzip = new GZIPInputStream(new ByteArrayInputStream(bytes))) { byte[] buffer = new byte[BUFFER_SIZE]; int n; while ((n = gunzip.read(buffer)) > -1) { out.write(buffer, 0, n); } return out.toByteArray(); } catch (IOException e) { throw new RuntimeException("gzip decompress error", e); } } }
解码器和编码器
本文使用的通信方式是基于Netty实现的
Netty中的Decoder和Encoder
- LengthFieldBasedFrameDecoder是ByteToMessageDecoder的一个实现类,可以解决存在定长的消息的解码问题
- MessageToByteEncoder和ByteToMessageDecoder是最基础的两个编码类。LengthFieldBasedFrameDecoder是ByteToMessageDecoder的一个实现,可以根据自己的需求选择。
编码
解码:@Slf4j public class ProtocolDecoder extends ByteToMessageDecoder { @Override protected void decode(ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf, List<Object> list) throws Exception { log.info("解码消息"); log.info("可读字节数:{}", byteBuf.readableBytes()); // 一共18B,但是Length占4B,所以最少要14B if (byteBuf.readableBytes() < 14) { return; } byteBuf.markReaderIndex(); log.info("读指针:{}", byteBuf.readerIndex()); byte magic = byteBuf.readByte(); if (magic != ProtocolConstant.MAGIC) { throw new RuntimeException("不支持的协议"); } byte version = byteBuf.readByte(); byte serialize = byteBuf.readByte(); byte type = byteBuf.readByte(); byte status = byteBuf.readByte(); // 读取8个字节 long requestId = byteBuf.readLong(); byte compress = byteBuf.readByte(); // 读取4个字节 int bodyLength = byteBuf.readInt(); log.info(String.valueOf( byteBuf.readableBytes())); // 如果可读字节数小于bodyLength,说明数据还没到齐,等待下一次读取 if (byteBuf.readableBytes() < bodyLength) { // 重置读指针 byteBuf.resetReaderIndex(); return; } byte[] body = new byte[bodyLength]; byteBuf.readBytes(body); Compressor compressor = CompressorFactory.getInstance("gzip"); byte[] unCompressBody = compressor.decompress(body); // 序列化 SerializerEnum serializerEnum = SerializerEnum.getByKey(serialize); log.info("serializer种类是{}", serializerEnum.getValue()); if (serializerEnum == null) { throw new RuntimeException("不支持的序列化器"); } Serializer serializer = SerializerFactory.getInstance(serializerEnum.getValue()); // Class<?> 是一个通配符,表示任意类型 Class<?> clazz = type == MessageType.REQUEST.getValue() ? RPCRequest.class : RPCResponse.class; Object bodyObj = serializer.deserialize(unCompressBody, clazz); ZMessage.Header header = new ZMessage.Header(magic, version, serialize, type, status, requestId, compress, bodyLength); ZMessage zMessage = new ZMessage(header, bodyObj); log.info("解码消息:{}", zMessage); list.add(zMessage); } }
如何加入Netty中?@Slf4j public class ProtocolEncoder extends MessageToByteEncoder<ZMessage<?>> { @Override protected void encode(ChannelHandlerContext channelHandlerContext, ZMessage<?> zMessage, ByteBuf byteBuf) throws IOException { if(zMessage == null || zMessage.getHeader() == null){ return; } log.info("Message{}",zMessage); ZMessage.Header header = zMessage.getHeader(); byteBuf.writeByte(header.getMagic()); byteBuf.writeByte(header.getVersion()); byteBuf.writeByte(header.getSerialize()); byteBuf.writeByte(header.getType()); byteBuf.writeByte(header.getStatus()); byteBuf.writeLong(header.getRequestId()); byteBuf.writeByte(header.getCompress()); SerializerEnum serializerEnum = SerializerEnum.getByKey(header.getSerialize()); if(serializerEnum == null) { throw new RuntimeException("不支持的序列化器"); } log.info("serializer的种类是{}", serializerEnum.getValue()); Serializer serializer = SerializerFactory.getInstance(serializerEnum.getValue()); byte[] bodyBytes = serializer.serialize(zMessage.getBody()); byte[] compressedBody = CompressorFactory.getInstance("gzip").compress(bodyBytes); log.info("Serialized message body length: {}", compressedBody.length); // 添加日志以确认序列化后的消息长度 byteBuf.writeInt(compressedBody.length); byteBuf.writeBytes(compressedBody); } }
我们需要在netty的handler中添加这个即可,注意需要在我们消息handler处理类之前添加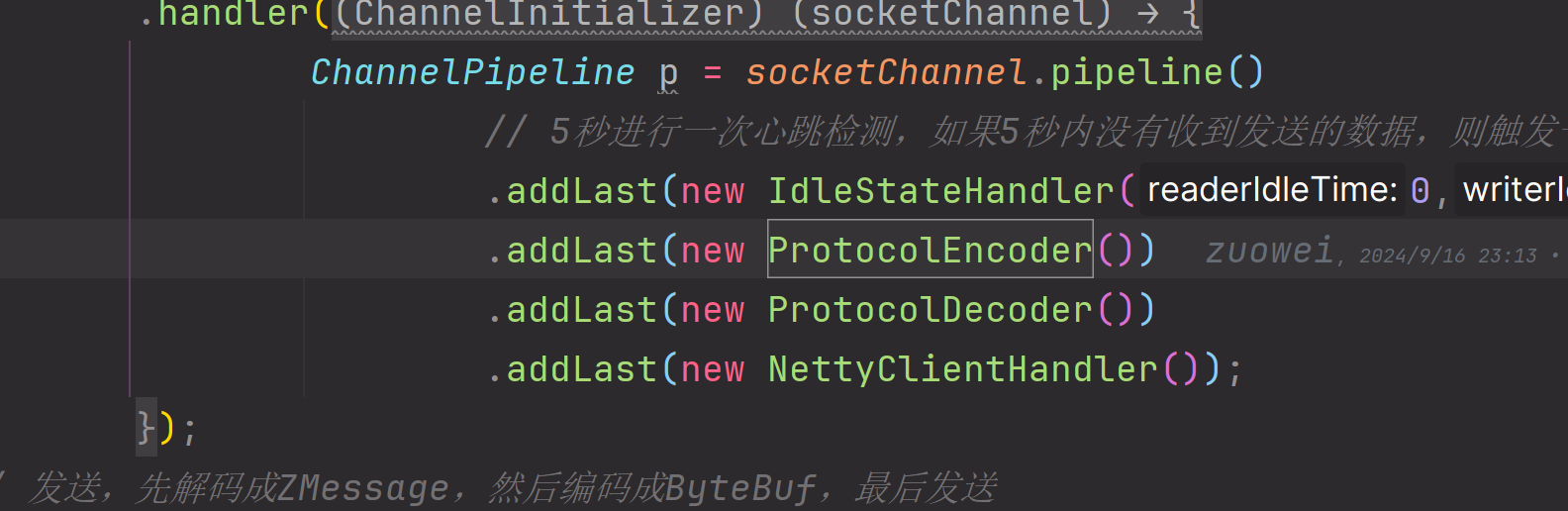
同时对于一个消息的发送和接收,Netty中的路径顺序是不一样的,发送消息时,我们先经过解码器,将要发送的内容解码成ZMessage,之后经过编码器,将其解码成字节的形式
接收消息时我们要经历的流程是相反的,要先将byte编码成我们的自定义的字节格式,之后再解码成我们的ZMessage。
网络传输的实现
Netty实现
- 网络通信层:支持多种网络协议,当网络数据读取到内核缓冲区后,会触发各种网络事件,会分发给事件调度层进行处理。核心是
- BootStrap,负责Netty客户端的启动、初始化、服务器连接等过程
- ServerBootStrap:用于服务端绑定本地端端口,会绑定Boss和Worker两个EventLoopGroup
- Channle 通道,基于NIO更高层次的抽象吗
request - response模型
Netty的通信是异步通信,也就是说我们的客户端和服务端是不能够同步来确认请求和响应是否成功,所以我们可以使用一个未处理请求来确定我们的请求是否成功得到响应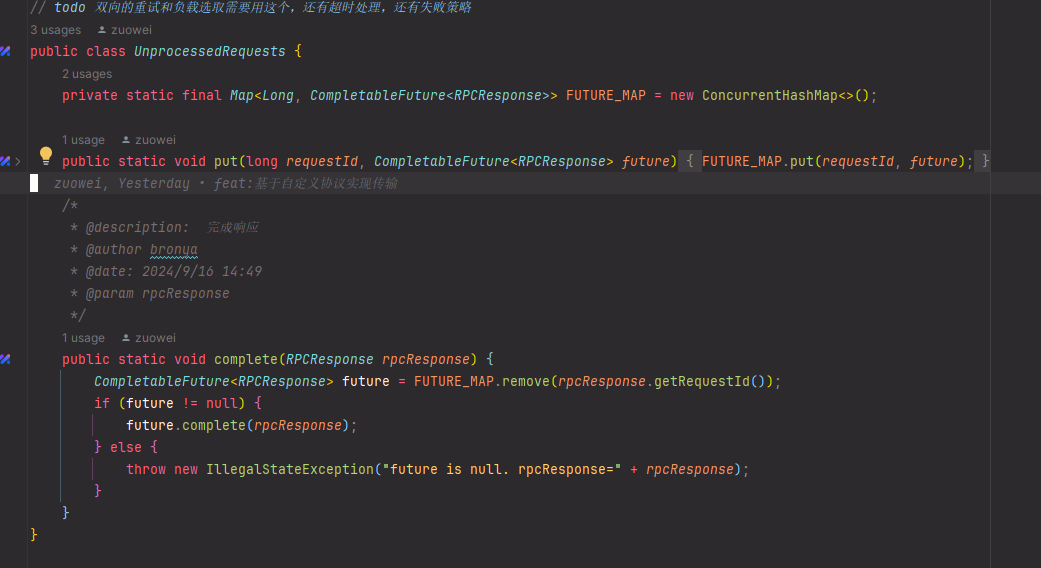
在Invoker中,我们成功发送请求之前先将这个结果放入map中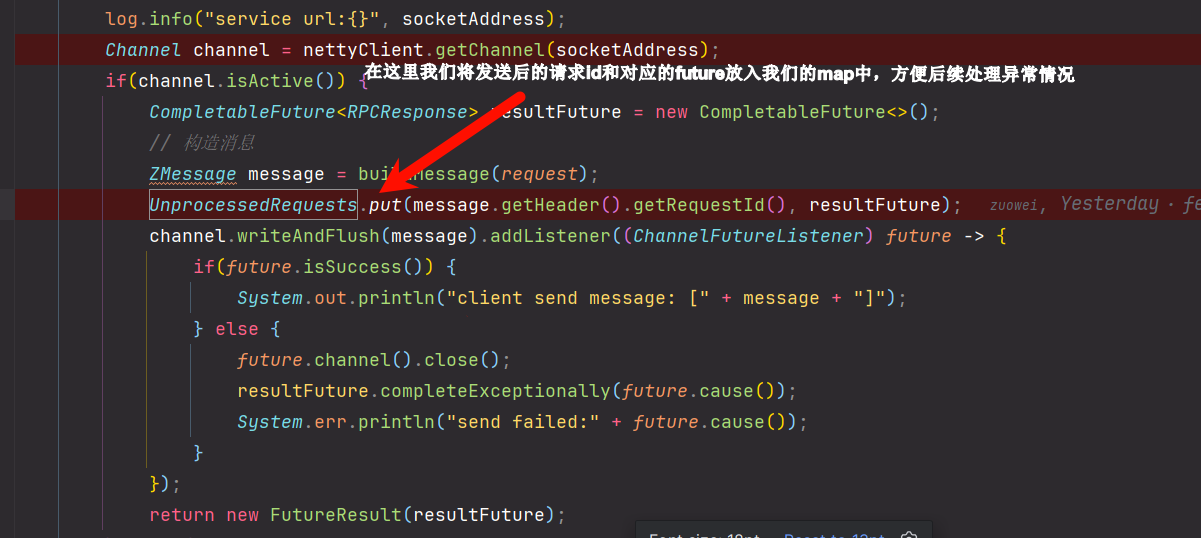
在我们的ClientHandler中,我们可以通过响应的requestId来确认我们是否成功收到了回复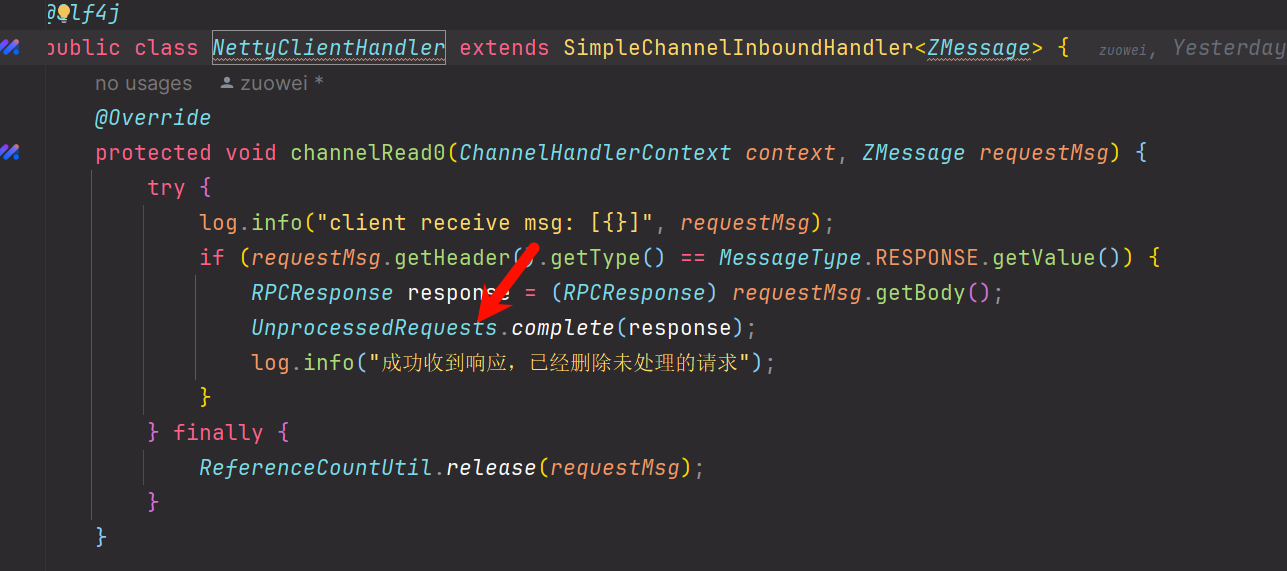
心跳机制
更加详细的介绍 从零开始实现简单 RPC 框架 9:网络通信之心跳与重连机制 - 小新是也 - 博客园 (cnblogs.com)
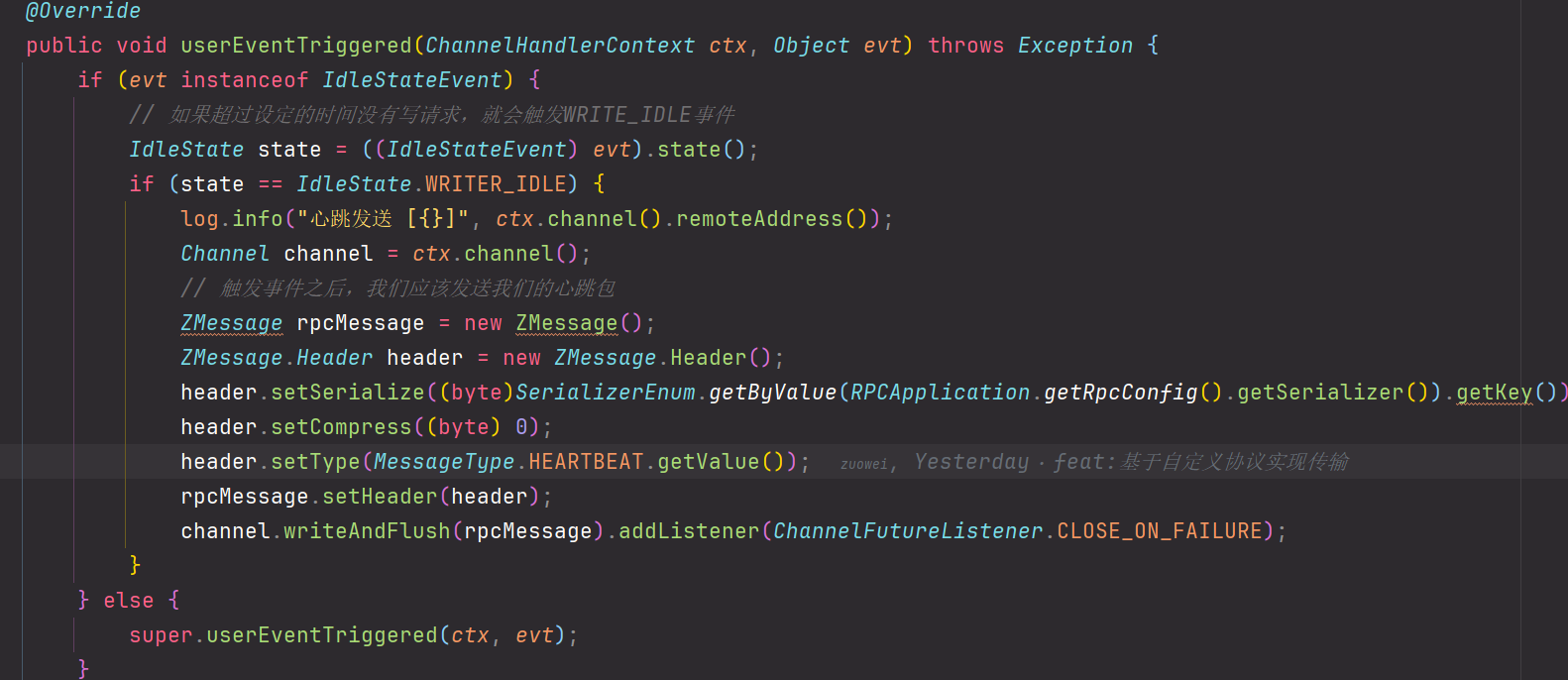
Netty已经帮我们提供了一个心跳Handler IdleStateHandler,当连接的空闲时间过长时,IdleStateHandler会触发一个 IdleStateEvent 事件,传递的到下一个Handler,我们可以通过在自定义的Handler中重写userEventTrigged方法来处理这个事件。需要注意的是自定义的Handler应该追加在心跳Handler之后。
1.完整的构造函数
observeOutput:是否考虑出站较慢的情况。如果为true就不触发此次事件,如果false就会触发。默认为falsereaderIdleTime:读空闲时间,0表示禁用读空闲时间事件writerIdleTime:写空闲事件,0表示禁用写空闲事件。allIdleTime:读或者写空闲时间,0表示禁用事件unit:单位
2.核心的事件处理机制IdleStateHandler继承ChannelDuplexHandler,重写了出站和入站的事件,我们来看看代码。
当 channel 添加、注册、活跃的时候,会初始化initialize(ctx),删除、不活跃的时候销毁destroy(),读写的时候设置lastReadTime和lastWriteTime字段。
最底层的调用,也即是实际上如何进行public class IdleStateHandler extends ChannelDuplexHandler { @Override public void handlerAdded(ChannelHandlerContext ctx) throws Exception { if (ctx.channel().isActive() && ctx.channel().isRegistered()) { initialize(ctx); } } @Override public void handlerRemoved(ChannelHandlerContext ctx) throws Exception { destroy(); } @Override public void channelRegistered(ChannelHandlerContext ctx) throws Exception { if (ctx.channel().isActive()) { initialize(ctx); } super.channelRegistered(ctx); } @Override public void channelActive(ChannelHandlerContext ctx) throws Exception { initialize(ctx); super.channelActive(ctx); } @Override public void channelInactive(ChannelHandlerContext ctx) throws Exception { destroy(); super.channelInactive(ctx); } @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { // 判断是否开启 读空闲 或者 读写空闲 监控 if (readerIdleTimeNanos > 0 || allIdleTimeNanos > 0) { // 设置 reading 标志位 reading = true; firstReaderIdleEvent = firstAllIdleEvent = true; } ctx.fireChannelRead(msg); } // 读完成之后 @Override public void channelReadComplete(ChannelHandlerContext ctx) throws Exception { // 判断是否开启 读空闲 或者 读写空闲 监控,检查 reading 标志位 if ((readerIdleTimeNanos > 0 || allIdleTimeNanos > 0) && reading) { // 设置 lastReadTime,后面判断读超时有用 lastReadTime = ticksInNanos(); reading = false; } ctx.fireChannelReadComplete(); } @Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { // 判断是否开启 写空闲 或者 读写空闲 监控 if (writerIdleTimeNanos > 0 || allIdleTimeNanos > 0) { // writeListener 的方法在下面,主要是设置 lastWriteTime ctx.write(msg, promise.unvoid()).addListener(writeListener); } else { ctx.write(msg, promise); } } private final ChannelFutureListener writeListener = new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture future) throws Exception { lastWriteTime = ticksInNanos(); firstWriterIdleEvent = firstAllIdleEvent = true; } }; }
可以看到,其实实际上就是将事件传给下一个Handler,也就是调用了userEventTriggered方法private void invokeUserEventTriggered(Object event) { if (invokeHandler()) { try { // 触发事件,说白了,就是直接调用 userEventTriggered 方法而已 ((ChannelInboundHandler) handler()).userEventTriggered(this, event); } catch (Throwable t) { notifyHandlerException(t); } } else { fireUserEventTriggered(event); } }
3.实现- 客户端Client实现
- 服务端实现:对于心跳包我们没必要去回复,我们只需要处理是否有写事件是否发生即可
4.断线重连的秘密
核心就是我们的这个缓存,对于每一个连接,我们都通过连接地址来保存他的Channel
核心函数是这个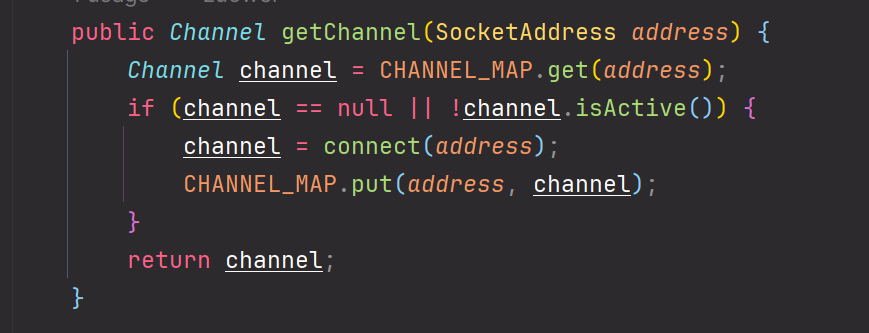
当我们检测到这个channel不存在或者不活跃时我们重新建立连接并放在缓存中即可
需要保证我们的字节数要对的上,因为我们自定义协议的字节不满足会放在缓冲区,
然后如果不需要处理其他协议比如HTTP可以不加那种Handler
消息的处理Handler
具体实现可以参考 NettyClientHandler和NettyServerHandler两个类的实现,思路很简单这里就不贴出源码了。
负载均衡的实现
- 随机:随机数选取
- 轮询:使用AtomicInteger来保证线程安全和原子操作,保证轮询的实现。
- 一致性哈希算法
实现思路仍然是根据SPI实现,然后篇幅原因,具体的实现可以参照源码。
一致性哈希
主要是在Hash算法的基础上增加环形空间、虚拟节点等。从而当服务器数量出现变化时不会导致
重试与容错
出现故障时,如何处理
Callable对象:
Callable 是 Java 中的一个接口,用于表示可以返回结果并可能抛出异常的任务。它与 Runnable 接口类似,但 Runnable 不能返回结果,也不能抛出受检异常。
主要用途
异步任务:Callable 常用于需要在后台线程中执行并返回结果的任务。
异常处理:Callable 可以抛出受检异常,允许更灵活的错误处理。
常见的重试策略
- 固定间隔重试:固定间隔
- 线性重试:时间间隔线性增加
- 最大重试次数
- 不重试
固定间隔实现:@Slf4j public class FixedIntervalRetryStrategy implements RetryStrategy{ @Override public RPCResponse doRetry(Callable<RPCResponse> callable) throws Exception { // Retryer是重试的核心类,RetryerBuilder是构建Retryer的工厂类 Retryer<RPCResponse> retryer = RetryerBuilder.<RPCResponse>newBuilder() // 重试条件,当发生Exception时重试 .retryIfExceptionOfType(Exception.class) // 重试间隔时间策略,每次重试间隔3秒 .withWaitStrategy(WaitStrategies.fixedWait(3L, TimeUnit.SECONDS)) // 重试停止策略,重试3次后停止 .withStopStrategy(StopStrategies.stopAfterAttempt(3)) // 重试监听器,监听重试事件 .withRetryListener(new RetryListener() { @Override public <V> void onRetry(Attempt<V> attempt) { // 重试日志 log.info("重试第{}次", attempt.getAttemptNumber()); } }).build(); return retryer.call(callable); } }
常见的容错策略
容错机制是分布式系统设计中非常重要的一部分,它的目标是在部分组件或节点出现故障时,仍能保证系统整体的正常运转和服务可用性。
- 失败自动切换(Failover)
- 快速失败(Failfast):立刻抛出异常,不进行重试或者降级
故障转移实现:
实际使用:@Slf4j public class FailOverTolerantStrategy implements TolerantStrategy{ @Override public RPCResponse doTolerant(Map<String, Object> context, Exception e) { List<ServiceMetaInfo> metaInfos = (List<ServiceMetaInfo>) context.get(TolerantStrategyConstant.SERVICE_LIST); ServiceMetaInfo metaInfo = (ServiceMetaInfo) context.get(TolerantStrategyConstant.CURRENT_SERVICE); RPCRequest rpcRequest = (RPCRequest) context.get(TolerantStrategyConstant.RPC_REQUEST); if(metaInfos == null || metaInfos.isEmpty()) { log.error("故障转移失败,metaInfos为空"); return null; } NettyClient nettyClient = NettyClient.getInstance(); ZMessage message = NettyInvoker.buildMessage(rpcRequest); for(ServiceMetaInfo serviceMetaInfo: metaInfos) { if (serviceMetaInfo.equals(metaInfo)) { continue; } RetryStrategy retryStrategy = RetryStrategyFactory.getInstance("fixedinterval"); try { return retryStrategy.doRetry(() -> { InetSocketAddress socketAddress = new InetSocketAddress(serviceMetaInfo.getServiceHost(), serviceMetaInfo.getServicePort()); Channel channel = nettyClient.getChannel(socketAddress); if (channel.isActive()) { CompletableFuture<RPCResponse> resultFuture = new CompletableFuture<>(); UnprocessedRequests.put(message.getHeader().getRequestId(), resultFuture); channel.writeAndFlush(message).addListener((ChannelFutureListener) future -> { if (future.isSuccess()) { log.info("client send message{}", message); } else { future.channel().close(); resultFuture.completeExceptionally(future.cause()); log.info("send failed{}", future.cause()); } }); return resultFuture.get(); } else { throw new RuntimeException("channel is not active. address=" + socketAddress); } }); } catch (Exception ex) { log.error("故障转移失败,重试失败"); } } throw new RuntimeException("容错失败,所有的服务重试都失败"); } }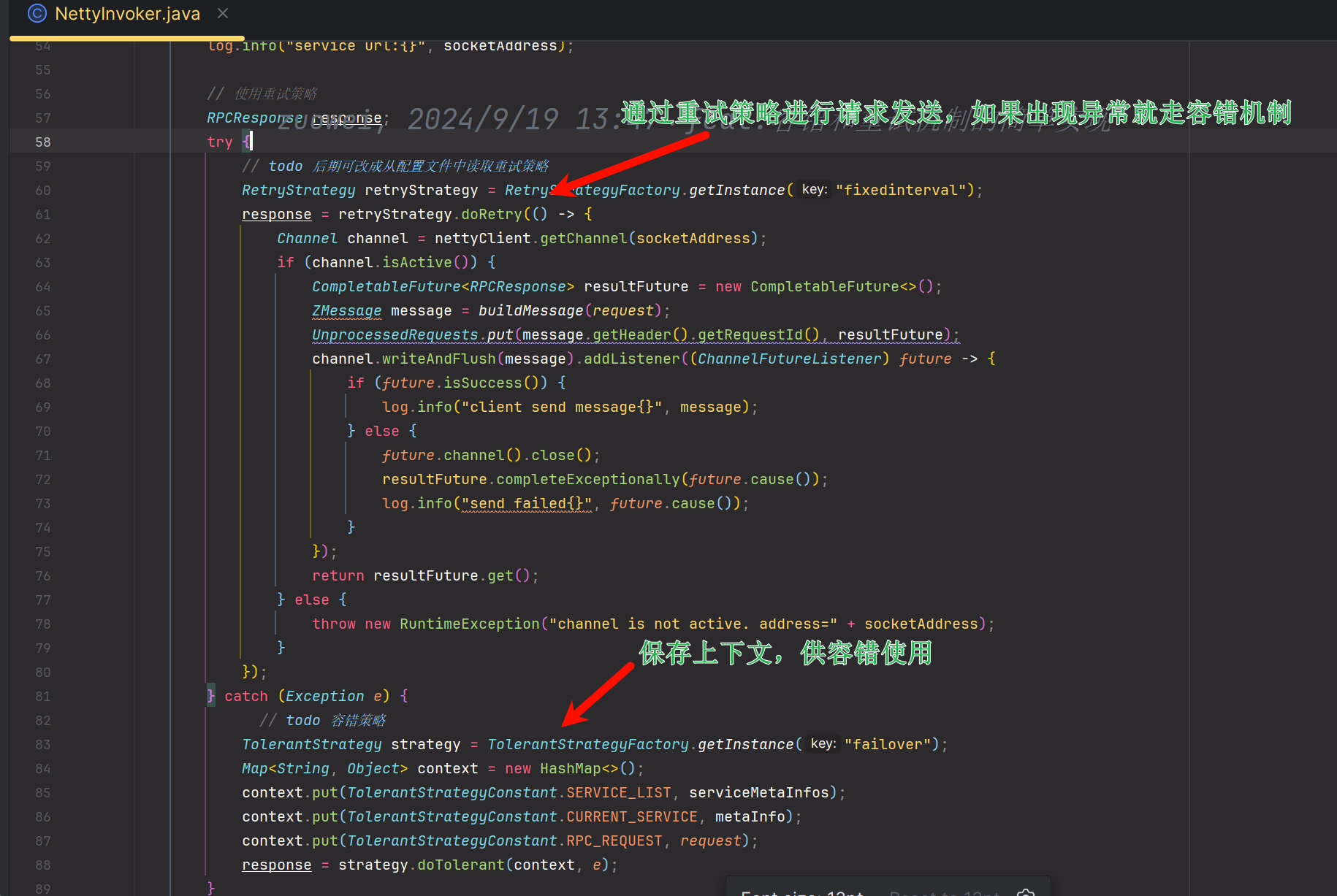
Starter包
- 服务扫描设计
使用BeanPostProcessor来加载被@ZuoRpcService注解的类BeanPostProcessor 是 Spring 框架中的一个接口,允许在 Spring 容器实例化 bean 之后但在依赖注入发生之前对 bean 进行自定义修改。它提供了两个主要方法:
postProcessBeforeInitialization(Object bean, String beanName):在 bean 初始化之前进行处理。
postProcessAfterInitialization(Object bean, String beanName):在 bean 初始化之后进行处理。
如何编写一个Starter包?
引入springboot启动依赖,编写bootstrap类
ImportBeanDefinitionRegistrar 是 Spring 框架中的一个接口,用于在运行时动态注册 Bean 定义。它允许您在 Spring 应用程序上下文中注册额外的 Bean 定义,而无需在 XML 配置文件或注解中显式声明它们。
注册服务应该在服务启动之前就进行,因为Netty会阻塞,导致后续无法注册成功
遇到的问题
我使用的依赖是
<dependency>
<groupId>org.apache.zookeeper<groupId>
<artifactId>zookeeper<artifactId>
<version>3.6.3<version> <dependency>
<dependency>
<groupId>org.springframework.cloud<groupId>
<artifactId>
spring-cloud-starter-zookeeper-discovery
<artifactId>
<version>4.1.2<version>
<dependency>这个依赖也可以直接使用curator,但是他的zookeeper的配置是单独的,会绑定spring启动,我们自定义写的registry中心不能和这个绑定,就导致一直是绑定到本地zookeeper,即使我们已经成功注册了
所以使用curator的依赖来解决
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-x-discovery</artifactId>
<version>5.6.0</version>
</dependency>基础设置启动
注解设计
启动注解
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Import({RPCInitBootStrap.class, RPCProviderBootstrap.class, RPCConsumerBootstrap.class}) // 自动按照顺序加载这几个类
public @interface EnableZuofwRpc {
/**
* 需要启动server
*
* @return
*/
boolean needServer() default true;
}客户端调用:
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface ZuofwRPCReference {
/**
* 服务接口类
* @return
*/
Class<?> interfaceClass() default void.class;
/**
* 服务版本
* @return
*/
String serviceVersion() default RPCConstant.DEFAULT_SERVICE_VERSION;
}服务提供者
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Component
public @interface ZuofwRPCService {
/**
* 服务接口类
*
* @return
*/
Class<?> interfaceClass() default void.class;
/**
* 服务版本
*
* @return
*/
String serviceVersion() default RPCConstant.DEFAULT_SERVICE_VERSION;
}扫描类实现
初始化类加载
@Slf4j
public class RPCInitBootStrap implements ImportBeanDefinitionRegistrar {
/**
* Spring初始化执行时候,初始化Rpc框架
*
* @param importingClassMetadata
* @param registry
*/
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
// 获取EnableRpc 注解的属性值
boolean needServer = (boolean) importingClassMetadata.getAnnotationAttributes(EnableZuofwRpc.class.getName()).get("needServer");
// Rpc框架初始化(配置和注册中心)
RPCApplication.init();
final RPCConfig rpcConfig = RPCApplication.getRpcConfig();
// 启动服务器
if (needServer) {
NettyServer nettyServer = new NettyServer();
new Thread(() -> {
log.info("port:{}", rpcConfig.getServerPort());
nettyServer.start(rpcConfig.getServerPort());
}).start();
} else {
log.info("Rpc server is not started");
}
}
}代理扫描实现
@Slf4j
public class RPCConsumerBootstrap implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
Class<?> beanClass = bean.getClass();
// 遍历对象的所有属性
Field[] declaredFields = beanClass.getDeclaredFields();
for (Field field : declaredFields) {
ZuofwRPCReference rpcReference = field.getAnnotation(ZuofwRPCReference.class);
if (rpcReference != null) {
// 为属性生成代理对象
Class<?> interfaceClass = rpcReference.interfaceClass();
if (interfaceClass == void.class) {
interfaceClass = field.getType();
}
System.out.println("生成代理对象:" + interfaceClass.getName()+" "+field.getType());
field.setAccessible(true);
log.info("生成代理对象:{}", interfaceClass.getName());
Object proxy = ServiceProxyFactory.getProxy(interfaceClass);
// Object proxy = ServiceProxyFactory.getCGProxy(interfaceClass);
try {
field.set(bean, proxy);
field.setAccessible(false);
} catch (IllegalAccessException e) {
System.out.println("生成代理对象失败");
throw new RuntimeException(e);
}
}
}
return BeanPostProcessor.super.postProcessAfterInitialization(bean, beanName);
}
}服务扫描和注册实现
@Slf4j
public class RPCProviderBootstrap implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
Class<?> beanClass = bean.getClass();
ZuofwRPCService rpcService = beanClass.getAnnotation(ZuofwRPCService.class);
if (rpcService != null) {
// 需要注册服务
// 获取服务基本信息
Class<?> interfaceClass = rpcService.interfaceClass();
// 默认值处理
if (interfaceClass == void.class) {
interfaceClass = beanClass.getInterfaces()[0];
}
String serviceName = interfaceClass.getName();
String serviceVersion = rpcService.serviceVersion();
// 注册服务
// 本地注册
LocalRegistry.register(serviceName, beanClass);
// 全局配置
final RPCConfig rpcConfig = RPCApplication.getRpcConfig();
// 注册到注册中心
RegistryConfig registryConfig = rpcConfig.getRegistryConfig();
Registry registry = RegistryFactory.getInstance(registryConfig.getRegistry());
ServiceMetaInfo serviceMetaInfo = new ServiceMetaInfo();
serviceMetaInfo.setServiceName(serviceName);
serviceMetaInfo.setServiceVersion(serviceVersion);
serviceMetaInfo.setServiceHost(rpcConfig.getServerHost());
serviceMetaInfo.setServicePort(rpcConfig.getServerPort());
try {
registry.register(serviceMetaInfo);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
return BeanPostProcessor.super.postProcessAfterInitialization(bean, beanName);
}
}总结
感谢观看,到这里我们基本缕清了一遍RPC的实现原理,具体的实现可以到我的Github中查看源码。