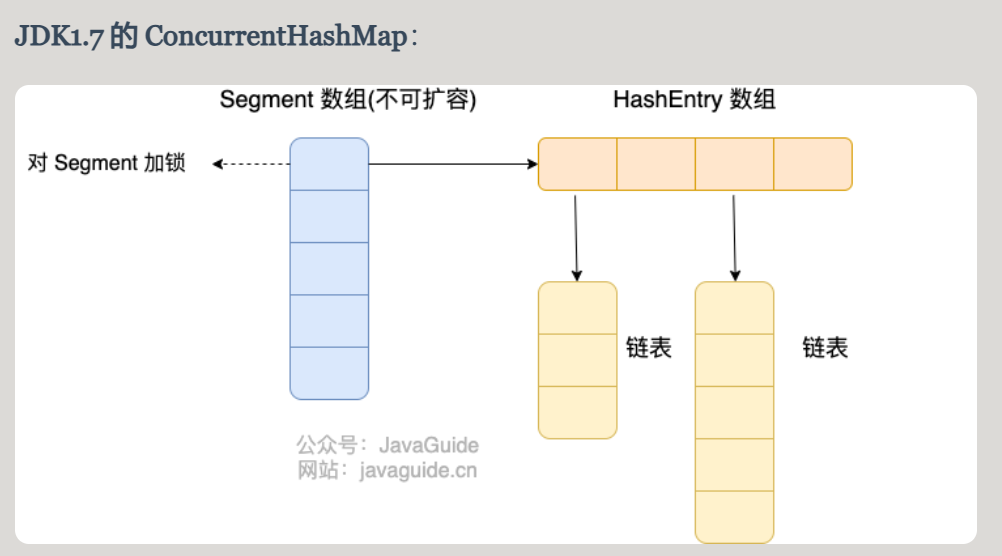
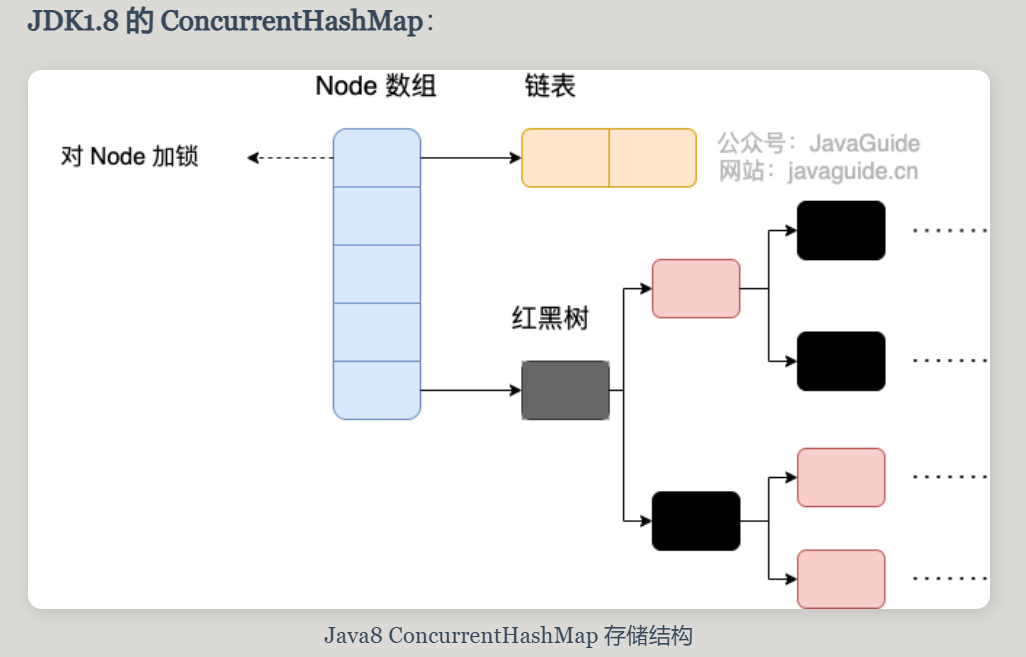
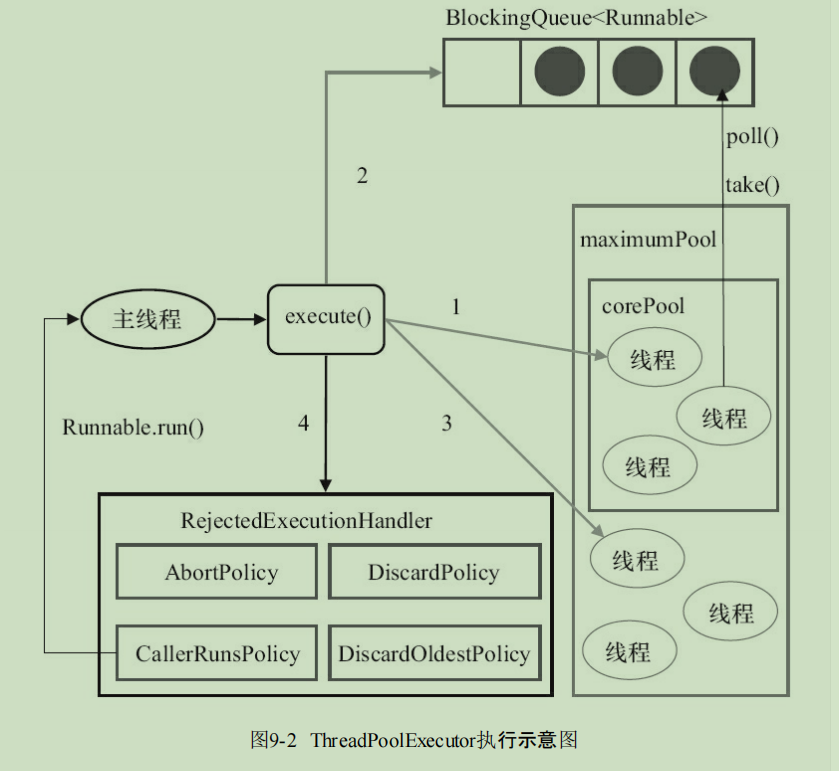
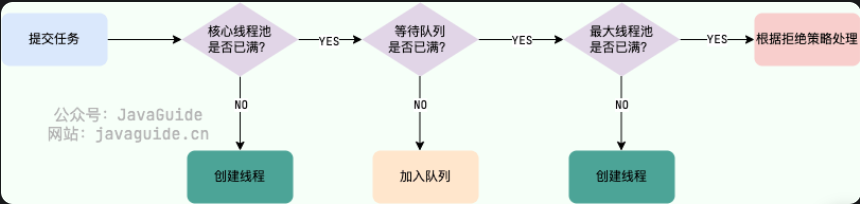
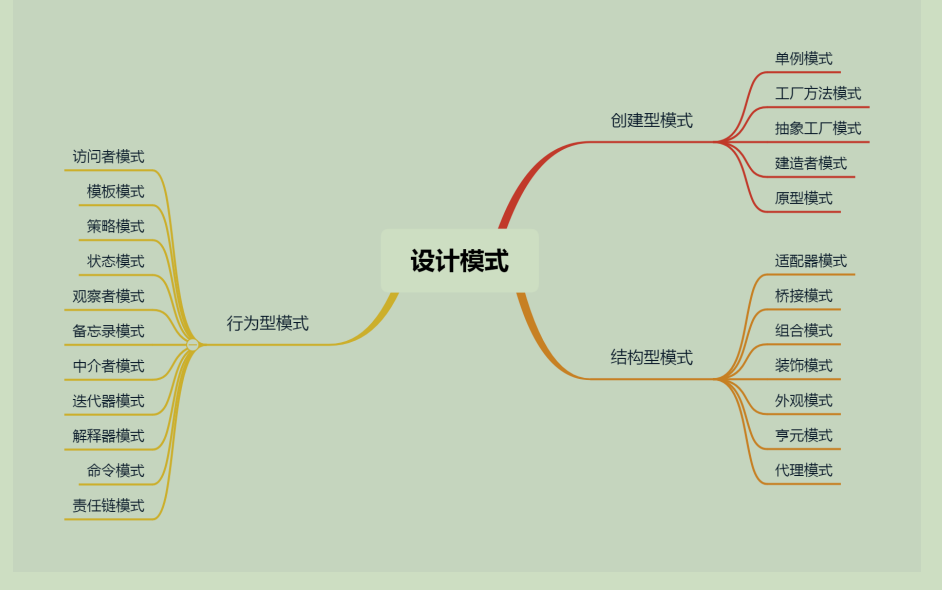
面试常问
注解
- @Nullable 注解的主要作用是为开发者和静态分析工具提供信息,指示某个字段、方法返回值或参数可以为 null。具体来说,它会: 帮助静态分析工具:静态分析工具可以利用 @Nullable 注解来检查代码中是否正确处理了可能为 null 的情况,并在发现潜在问题时发出警告。增强代码可读性:开发者可以通过查看注解来了解哪些变量或返回值可能为 null,从而在使用这些变量时进行适当的空值检查。文档生成:在生成文档时,@Nullable 注解可以帮助其他开发者理解哪些字段、方法返回值或参数可以为 null。它不会直接阻止 NullPointerException 的发生,但能帮助开发者在编写和维护代码时进行适当的空值检查,从而减少空指针异常的发生
- Bean相关
- @Autowired和@Resource
@Autowired默认注入方式是byType,也就是优先根据接口类型去匹配并注入Bean
@Resource默认是byName注入的,如果不能通过name匹配会变为byType,可以使用只当以下两个属性其中之一来确定,不建议同时指定两个属性
public @interface Resource {
String name() default "";
Class<?> type() default Object.class;
}
@RestController注解是@Controller和@ResponseBody,会将函数的返回值直接填入HTTP响应体中,是REST风格的控制器- @Scope(““)生命作用域:
- singleton单例作用域,默认全是单例
- prototype 每次请求都创建一个新的实例
- request 每次HTTP请求都会创建一个bean,在当前HTTP request有效
- session 在当前的HTTP session中有效
@SpringBootApplication 是@Configuration、@EnableAutoConfiguration、@ComponentScan 注解的集合。
@EnableAutoConfiguration 启动自动装配@ComponentScan:扫描注解标记的组件,默认送奥妙该类所在的包下的所有的类@Configuration 允许在 Spring 上下文中注册额外的 bean 或导入其他配置类
- 读取配置信息并且与bean绑定
Bean
- Bean的作用域
- singleton单例:Spring中的bean默认都是单例的
- prototype:每次获取都会创建一个新的Bean,也就是连续两次获取Bean都会是不同的Bean实例
- request:每一次HTTP请求都会产生一个新的bean,bean在当前HTTP request内生效
- sesson:在HTTP的session中有效,session是多个HTTP之间使用的连续会话
- application/global-session (仅 Web 应用可用):每个 Web 应用在启动时创建一个 Bean(应用 Bean),该 bean 仅在当前应用启动时间内有效。
- websocket:每一次WebSocket都会产生一个新的bean
配置方式:@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public Person personPrototype() {
return new Person();
}
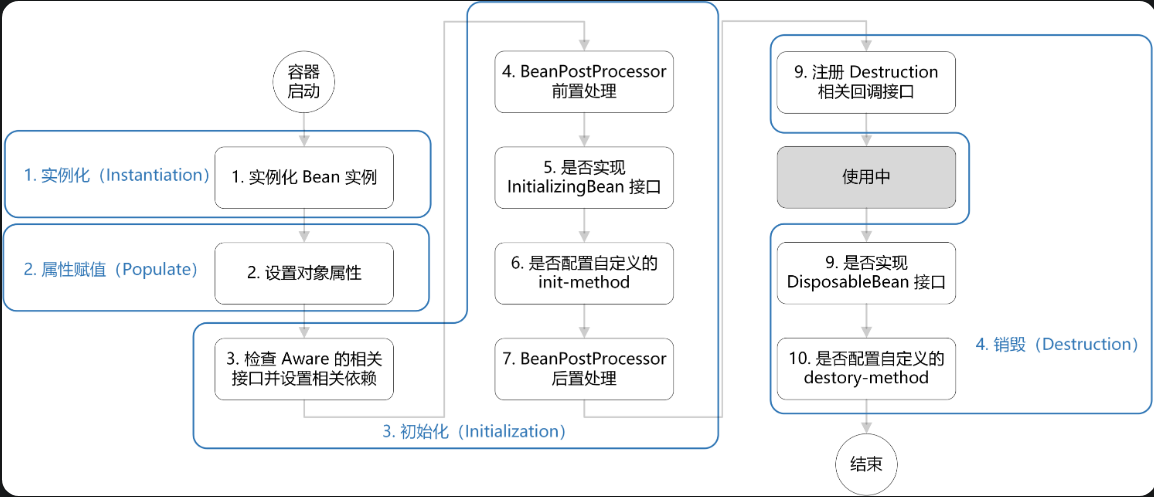
- Bean的生命周期
- 创建Bean的实例:Bean容器会先找到Bean的定义,然后通过Java反射API来创建Bean的实例
- Bean属性赋值/填充:为Bean设置相关属性和依赖,例如填入@Autowired等注解注入的对象,setter方法和构造函数
- Bean初始化:

- 销毁Bean:把Bean的销毁方法记录下来,将爱需要销毁Bean或者销毁容器时,调用这些方法去释放Bean所持有的资源
- 如果 Bean 实现了
DisposableBean 接口,执行 destroy() 方法。
- 如果 Bean 在配置文件中的定义包含
destroy-method 属性,执行指定的 Bean 销毁方法。或者,也可以直接通过@PreDestroy 注解标记 Bean 销毁之前执行的方法。
AOP
常见实现
Spring AOP实现方式有动态代理、字节码等操作方式
常见术语: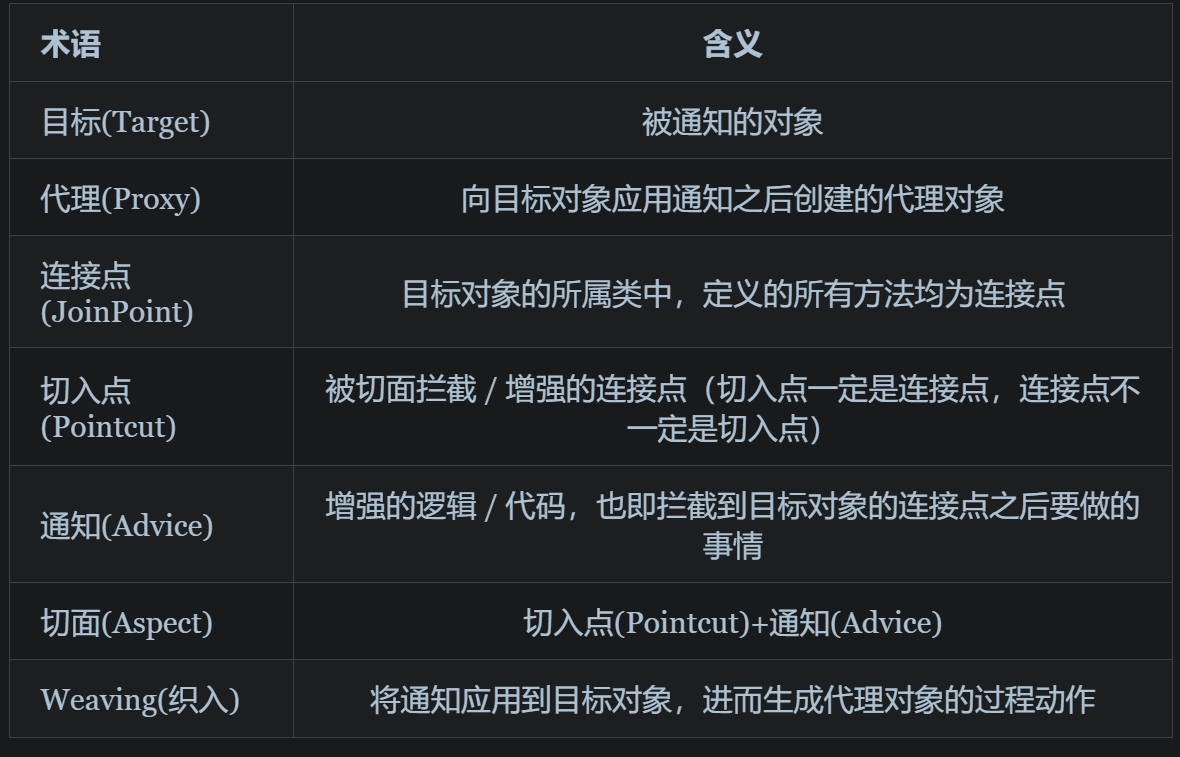
AspectJ定义的通知类型
- Before 前置通知:在目标方法调用之前,所以获得不到目标方法的具体东西
- After 后置通知:目标方法调用之后,类似于finally,无论方法是否成功都会调用
- AfterReturing:目标方法调用之后,返回结果之后触发,只有方法完成成功会调用
- AfterThrowing:异常通知,出现异常时触发,类似catch
- Around环绕通知:可以拿到目标对象
对于多个切面的执行顺序可以通过@Order(数字) 来指定
Spring MVC
MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。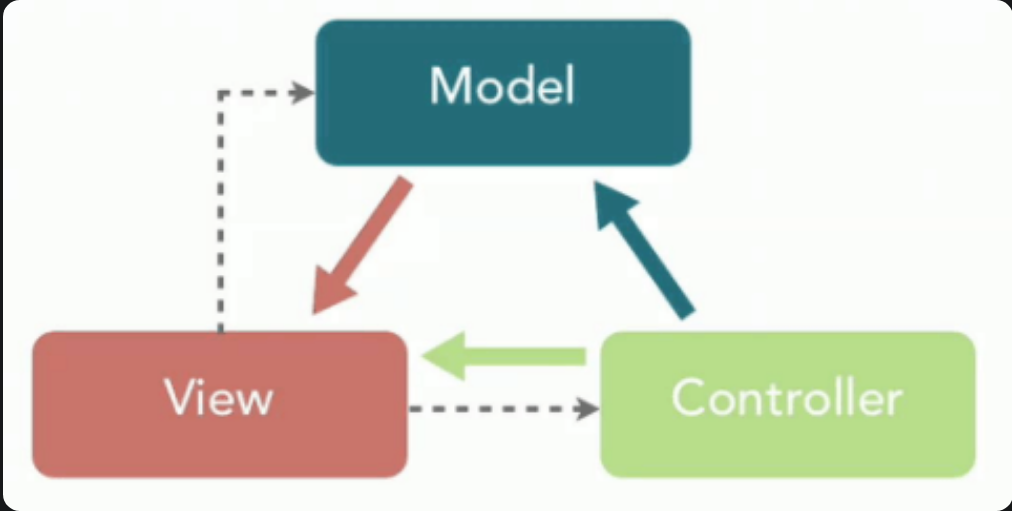
核心组件:
- **
DispatcherServlet**“:核心中央处理器,用汉语接受请求、分发请求,给予客户端响应
- HandlerMapping:处理器映射器,根据URL去匹配查找能处理的Handler,并将涉及的拦截器和Handler一起封装
- HandlerAdapter:处理器适配器,根据HandlerMapping找到的Handler,设配置型对应的Handler
- Handler:请求处理器
- ViewResolver:视图解析器,根据Handler返回的逻辑视图/试图,解析并渲染真正的试图,传递给DispatcherServlet响应客户端。
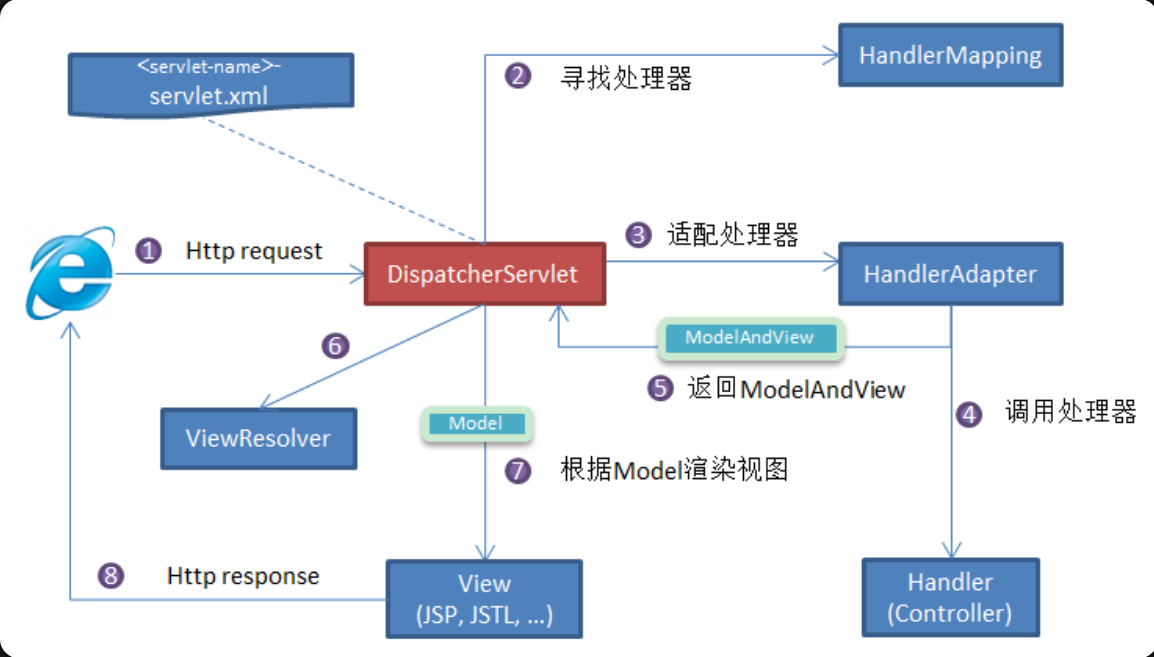
流程说明(重要):
- 客户端(浏览器)发送请求,
DispatcherServlet拦截请求。
DispatcherServlet 根据请求信息调用 HandlerMapping 。HandlerMapping 根据 URL 去匹配查找能处理的 Handler(也就是我们平常说的 Controller 控制器) ,并会将请求涉及到的拦截器和 Handler 一起封装。DispatcherServlet 调用 HandlerAdapter适配器执行 Handler 。Handler 完成对用户请求的处理后,会返回一个 ModelAndView 对象给DispatcherServlet,ModelAndView 顾名思义,包含了数据模型以及相应的视图的信息。Model 是返回的数据对象,View 是个逻辑上的 View。ViewResolver 会根据逻辑 View 查找实际的 View。DispaterServlet 把返回的 Model 传给 View(视图渲染)。- 把
View 返回给请求者(浏览器)
Spring使用的设计模式:

Spring事务
ACID AID是手段,最终目的是保证C
相关接口
**PlatformTransactionManager**:(平台)事务管理器,Spring 事务策略的核心。
**TransactionDefinition**:事务定义信息(事务隔离级别、传播行为、超时、只读、回滚规则)。
**TransactionStatus**:事务运行状态。
- 编程式事务 (推荐在分布式系统中使用)通过手动使用TransactionTemplate或者TranctionManager手动管理事务,事务范围过大会出现事务未提交导致超时,因此事务要比锁的颗粒度更小
public class UserService {
private TransactionTemplate transactionTemplate;
public UserService(TransactionTemplate transactionTemplate) {
this.transactionTemplate = transactionTemplate;
}
public User createUser(final String username) {
return transactionTemplate.execute(new TransactionCallback<User>() {
@Override
public User doInTransaction(TransactionStatus status) {
try {
} catch (Exception e) {
status.setRollbackOnly();
throw e;
}
}
});
}
}
- 声明式事务:通过使用@Tranctional全注解
事务
Spring事务中有哪几种传播行为
- **
TransactionDefinition.PROPAGATION_REQUIRED**,默认,如果当前存在事务,就加入该事务,否则创建一个新的 事务
TransactionDefinition.PROPAGATION_REQUIRES_NEW 创建一个新事务,当前存在事务就把TransactionDefinition.PROPAGATION_NESTED 没有事务就创建一个事务左伟当前事务的嵌套事务,存在事务就和 1 相同TransactionDefinition.PROPAGATION_MANDATORY 如果存在事务就加入该事务,不存在事务就报错
TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
Spring事务隔离级别
- **
TransactionDefinition.ISOLATION_DEFAULT**:使用后端数据库的默认隔离等级,MySQL采用可重复读,Oracle默认采用读已提交
- **
TransactionDefinition.ISOLATION_READ_UNCOMMITTED**:最低的隔离等级,允许读已提交,可能会导致脏读,幻读和不可重复读
- **
TransactionDefinition.ISOLATION_READ_COMMITTED**:允许读并发事务已提交的事务,可以阻止脏读,但是幻读和不可重复仍有可能发生。
- **
TransactionDefinition.ISOLATION_REPEATABLE_READ**:对同意字段多次读都是相同的,可以组织脏读和不可重复读,但是幻读仍然会发生
- **
TransactionDefinition.ISOLATION_SERIALIZABLE**: 序列化,最高的隔离级别,影响程序性能
Transactional(rollbackFor = Exception.class)
默认回滚是只有遇到RuntimeException运行时异常或者Error才进行回滚,而不会回滚,Checked Exception(Checked Exception是那些在编译时期就需要被处理的异常),
@Transactional(rollbackFor = Exception.class,rollbackFor = Exception.class)
public void someMethod() {
}
Spirng Data JPA (Java Persistence API)
是Java平台上的一个规范,用于将对象映射到关系数据库
如何使用JPA在数据库中非持久化一个字段
非持久化:也就是不被数据库存储
可以使用注解的方式:
@Entity(name = "student")
public class Student {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
@Column(name = "id")
private Long id;
@Column(name = "name")
private String name;
@Column(name = "age")
private Integer age;
@Transient
private String secrect;
}
JPA审计功能
审计功能主要是帮助我们记录数据库操作的具体行为比如某条记录是谁创建的、什么时间创建的、最后修改人是谁、最后修改时间是什么时候。
示例:
@Data
@AllArgsConstructor
@NoArgsConstructor
@MappedSuperclass
@EntityListeners(value = AuditingEntityListener.class)
public abstract class AbstractAuditBase {
@CreatedDate
@Column(updatable = false)
@JsonIgnore
private Instant createdAt;
@LastModifiedDate
@JsonIgnore
private Instant updatedAt;
@CreatedBy
@Column(updatable = false)
@JsonIgnore
private String createdBy;
@LastModifiedBy
@JsonIgnore
private String updatedBy;
}
Spring Security
控制访问权限的方法:
permitAll():无条件允许任何形式访问,不管你登录还是没有登录。anonymous():允许匿名访问,也就是没有登录才可以访问。denyAll():无条件决绝任何形式的访问。authenticated():只允许已认证的用户访问。fullyAuthenticated():只允许已经登录或者通过 remember-me 登录的用户访问。hasRole(String) : 只允许指定的角色访问。hasAnyRole(String) : 指定一个或者多个角色,满足其一的用户即可访问。hasAuthority(String):只允许具有指定权限的用户访问hasAnyAuthority(String):指定一个或者多个权限,满足其一的用户即可访问。hasIpAddress(String) : 只允许指定 ip 的用户访问。
参数校验
Hibernate Validator
使用时建议使用**javax.validation.constraints**中的注解
常见的注解:
@NotEmpty 被注释的字符串的不能为 null 也不能为空@NotBlank 被注释的字符串非 null,并且必须包含一个非空白字符@Null 被注释的元素必须为 null@NotNull 被注释的元素必须不为 null@AssertTrue 被注释的元素必须为 true@AssertFalse 被注释的元素必须为 false@Pattern(regex=,flag=)被注释的元素必须符合指定的正则表达式@Email 被注释的元素必须是 Email 格式。@Min(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@Max(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值@DecimalMin(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@DecimalMax(value) 被注释的元素必须是一个数字,其值必须小于等于指定的最大值@Size(max=, min=)被注释的元素的大小必须在指定的范围内@Digits(integer, fraction)被注释的元素必须是一个数字,其值必须在可接受的范围内@Past被注释的元素必须是一个过去的日期@Future 被注释的元素必须是一个将来的日期@Positive和@PositiveOrZero验证数字必须为正数/包括0,同理 @Negative为负数
示例1:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Person {
@NotNull(message = "classId 不能为空")
private String classId;
@Size(max = 33)
@NotNull(message = "name 不能为空")
private String name;
@Pattern(regexp = "((^Man$|^Woman$|^UGM$))", message = "sex 值不在可选范围")
@NotNull(message = "sex 不能为空")
private String sex;
@Email(message = "email 格式不正确")
@NotNull(message = "email 不能为空")
private String email;
}
@RestController
@RequestMapping("/api")
public class PersonController {
@PostMapping("/person")
public ResponseEntity<Person> getPerson(@RequestBody @Valid Person person) {
return ResponseEntity.ok().body(person);
}
}
示例2:验证请求参数,要求在类上加@Validated注解
@RestController
@RequestMapping("/api")
@Validated
public class PersonController {
@GetMapping("/person/{id}")
public ResponseEntity<Integer> getPersonByID(@Valid @PathVariable("id") @Max(value = 5,message = "超过 id 的范围了") Integer id) {
return ResponseEntity.ok().body(id);
}
}
使用@Validated来指定不同的组别条件下使用不同的校验方法
- 定义组别接口,为空即可
public class User {
@NotBlank(groups = CreateGroup.class)
private String username;
@Size(min = 6, max = 14, groups = UpdateGroup.class)
private String password;
}
- 定义类的校验规则,根据组别来写
public class User {
@NotBlank(groups = CreateGroup.class)
private String username;
@Size(min = 6, max = 14, groups = UpdateGroup.class)
private String password;
}
- 不同的方法上的传参使用不同的组别来进行校验
public class User {
@NotBlank(groups = CreateGroup.class)
private String username;
@Size(min = 6, max = 14, groups = UpdateGroup.class)
private String password;
}
全局处理Controller层异常
@ControllerAdvice
@ResponseBody
public class GlobalExceptionHandler {
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<?> handleMethodArgumentNotValidException(MethodArgumentNotValidException ex, HttpServletRequest request) {
......
}
}
JPA
@Entity声明一个类对应一个数据库实体。@Table 设置表名@Id声明主键GeneratedValue 主键填充策略public enum GenerationType {
TABLE,
SEQUENCE,
IDENTITY,
AUTO
}
@Column 设置字段
@Column(columnDefinition = "tinyint(1) default 1")
private Boolean enabled;
@Transient 声明不需要持久化的字段,也就是不需要保存进数据库- 声明大字段:
- 创建枚举字段:自己创建枚举类,然后在枚举字段上加上@Enumerated注解即可
public enum Gender {
MALE("男性"),
FEMALE("女性");
private String value;
Gender(String str){
value=str;
}
}
@Entity
@Table(name = "role")
public class Role {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String description;
@Enumerated(EnumType.STRING)
private Gender gender;
省略getter/setter......
}
- 审计:
待补
- 删除/修改数据:
@Repository
public interface UserRepository extends JpaRepository<User, Integer> {
@Modifying
@Transactional(rollbackFor = Exception.class)
void deleteByUserName(String userName);
}
- 关联关系:
@OneToOne 声明一对一关系@OneToMany 声明一对多关系@ManyToOne 声明多对一关系@ManyToMany 声明多对多关系
JSON处理
@JsonIgnoreProperties 用于类上JsonIgnore 用于属性上
进行序列化时,会忽略标记的值,示例:{
"from": "user1",
"to": "user2",
"content": {"text": "Hello"},
"image": "image_url",
"readed": 1,
"date": "2023-01-01 12:00:00"
}
那么序列化之后的结果是
{
"from": "user1",
"to": "user2",
"content": {"text": "Hello"},
"readed": 1,
"date": "2023-01-01 12:00:00"
}
- JSON扁平化:
@JsonUnwrapped.
测试相关
IOC
控制反转,将new 交由Spring框架管理,Bean的生命周期都由Spring调用
优点:
- 资源变得容易管理:
- 降低对象之间的耦合和依赖
SpringBoot
@SpringBootConfiguration注解
里面包含三个注解
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(
excludeFilters = {@Filter(
type = FilterType.CUSTOM,
classes = {TypeExcludeFilter.class}
), @Filter(
type = FilterType.CUSTOM,
classes = {AutoConfigurationExcludeFilter.class}
)}
)
其中@EnableAutoConfiguration注解又包括以下两种注解:
@AutoConfigurationPackage
@Import({AutoConfigurationImportSelector.class})
这是@AutoConfigurationPackage注解的内容
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import({AutoConfigurationPackages.Registrar.class})
public @interface AutoConfigurationPackage {
String[] basePackages() default {};
Class<?>[] basePackageClasses() default {};
}
1、利用getAutoConfigurationEntry(annotationMetadata);给容器中批量导入一些组件
2、调用List configurations = getCandidateConfigurations(annotationMetadata, attributes)获取到所有需要导入到容器中的配置类
3、利用工厂加载 Map<String, List> loadSpringFactories(@Nullable ClassLoader classLoader);得到所有的组件
4、从META-INF/spring.factories位置来加载一个文件。默认扫描我们当前系统里面所有META-INF/spring.factories位置的文件,按照条件装配( @ C o n d i t i o n a l ) 最终会按需配置 {按照条件装配(@Conditional)最终会按需配置}按照条件装配(@Conditional)最终会按需配置
SpringBoot自动装配原理
@EnableAutoConfiguration:实现自动装配的核心
先说结论:实际上就是从META-INF/spring.factories文件中获取需要进行自动装配的类,生成响应的Bean对象,然后交给Spring容器管理。这个和手写starter包很类似
Spring源码阅读
推荐文章:xuchengsheng/spring-reading(github.com)
Resource
Resource 是Spring框架中用于简化和统一对底层资源(如文件、classpath 资源、URL 等)的访问的一个核心接口。
基本概念
classpath 是 Java 虚拟机(JVM)和 Java 编译器用来查找类文件和资源文件的路径。它指定了 Java 应用程序在运行时或编译时需要的类和资源的位置。classpath 可以包含目录、JAR 文件或 ZIP 文件。
主要功能
- 统一的资源抽象,无论资源来自文件系统、classpath、URL还是其他,Resource提供统一的抽象
- 资源描述通过getDescription来获得底层资源提供的描述性信息
- 读取能力:Resource提供了getInputStream方法,允许直接读取资源内容而无需关心资源的实际来源。
- 存在与可读性:Resource提供了两个方法来确定资源是否存在以及是否可读。
- 开放性检查:isOpen()用来检查资源是否标识一个已经打开的流,有助于避免重复读取流资源。
- 文件访问:当资源代表一个文件夹中的文件时,可以通过getFile()直接访问该文件
- Spring提供了多种Resource的实现
源码:
public interface InputStreamSource {
InputStream getInputStream() throws IOException;
}
ResourceLoader
Spring 框架中的一个关键接口,它定义了如何获取资源(例如类路径资源、文件系统资源或网页资源)的策略。这个接口是 Spring 资源加载抽象的核心,使得应用程序可以从不同的资源位置以统一的方式加载资源。
用于获取Resource对象的工厂。
主要功能
- 统一的资源加载,提供了一个标准化的方法来加载资源,不论资源是存放在类路径、文件系统、网络URL还是其他位置
- 资源位置解析:根据提供的资源字符串位置,可以确定资源的类型,并且为其创建响应的Resource实例
- 返回Resource实例:getResource(String location)方法,返回一个Resource对象,代表了指定位置的资源。
- 与ClassLoader交互:通过getClassLoader()方法返回其关联的ClassLoader
- 扩展性:
ResourceLoader 是一个接口,这意味着我们可以实现自己的资源加载策略,或者扩展默认的策略以满足特定需求。
- 内置实现与整合:Spring 提供了默认的
ResourceLoader 实现,如 DefaultResourceLoader。但更重要的是,org.springframework.context.ApplicationContext 也实现了 ResourceLoader,这意味着 Spring 上下文本身就是一个资源加载器。
源码:
public interface ResourceLoader {
String CLASSPATH_URL_PREFIX = "classpath:";
Resource getResource(String var1);
@Nullable
ClassLoader getClassLoader();
}
默认实现
public class DefaultResourceLoader implements ResourceLoader {
@Nullable
private ClassLoader classLoader;
private final Set<ProtocolResolver> protocolResolvers = new LinkedHashSet(4);
private final Map<Class<?>, Map<Resource, ?>> resourceCaches = new ConcurrentHashMap(4);
public <T> Map<Resource, T> getResourceCache(Class<T> valueType) {
return (Map)this.resourceCaches.computeIfAbsent(valueType, (key) -> {
return new ConcurrentHashMap();
});
}
public Resource getResource(String location) {
Assert.notNull(location, "Location must not be null");
Iterator var2 = this.getProtocolResolvers().iterator();
Resource resource;
do {
if (!var2.hasNext()) {
if (location.startsWith("/")) {
return this.getResourceByPath(location);
}
if (location.startsWith("classpath:")) {
return new ClassPathResource(location.substring("classpath:".length()), this.getClassLoader());
}
try {
URL url = new URL(location);
return (Resource)(ResourceUtils.isFileURL(url) ? new FileUrlResource(url) : new UrlResource(url));
} catch (MalformedURLException var5) {
return this.getResourceByPath(location);
}
}
ProtocolResolver protocolResolver = (ProtocolResolver)var2.next();
resource = protocolResolver.resolve(location, this);
} while(resource == null);
return resource;
}
protected Resource getResourceByPath(String path) {
return new ClassPathContextResource(path, this.getClassLoader());
}
protected static class ClassPathContextResource extends ClassPathResource implements ContextResource {
public ClassPathContextResource(String path, @Nullable ClassLoader classLoader) {
super(path, classLoader);
}
public String getPathWithinContext() {
return this.getPath();
}
public Resource createRelative(String relativePath) {
String pathToUse = StringUtils.applyRelativePath(this.getPath(), relativePath);
return new ClassPathContextResource(pathToUse, this.getClassLoader());
}
}
}
computeIfAbsent 是 Java 8 引入的 Map 接口中的一个默认方法。它用于在 Map 中查找指定键的值,如果该键不存在,则使用提供的映射函数计算该键的值,并将其插入到 Map 中,第二个参数可以传入lambda
ResourcePatternResolver
用于解析资源模式,支持通过模式匹配检索多个资源,支持通过模式匹配检索多个资源。
主要功能
资源模式解析
- 通过
getResources(String locationPattern)方法,支持使用通配符的资源模式,如classpath*:com/example/**/*.xml,用于检索匹配特定模式的多个资源。
资源获取
- 通过
getResources(Resource location)方法,根据给定的资源对象,返回匹配的资源数组。这使得可以获取与特定资源相关联的其他资源,例如获取与给定类路径下的一个文件相关的所有资源。
多种资源位置支持
- 可以处理不同的资源位置,包括类路径(classpath)、文件系统、URL等。这使得应用程序能够以不同的方式组织和存储资源,而不影响资源的检索和加载。
灵活的资源加载
- 结合
ResourceLoader的能力,ResourcePatternResolver允许在应用程序中以统一的方式加载各种资源,而无需关心底层资源的存储位置或形式。
通用资源操作
- 通过
Resource接口,提供了对资源的通用操作,例如获取资源的URL、输入流、文件句柄等。
源码
public interface ResourcePatternResolver extends ResourceLoader {
String CLASSPATH_ALL_URL_PREFIX = "classpath*:";
Resource[] getResources(String locationPattern) throws IOException;
}
DocumentLoader
用于加载和解析 XML 文档
主要功能
- 加载XML文档
- 解析XML文档
- 支持验证:通过指定验证模式(如 DTD 或 XML Schema 验证),可以确保文档的结构和内容符合规定的标准。
- 处理实体引用
- 错误处理
一些重要概念
内部类在编译后,其文件名格式为 OuterClass$InnerClass.class。
主要功能
- 获取类的基本信息
- 获取类上的注解信息
- 获取方法上的注解信息
- 获取类的成员类信息
- 获取类的资源信息
- 获取类的超类信息
源码
public interface MetadataReaderFactory {
MetadataReader getMetadataReader(String var1) throws IOException;
MetadataReader getMetadataReader(Resource var1) throws IOException;
}
SpringMVC
拦截器和过滤器的区别
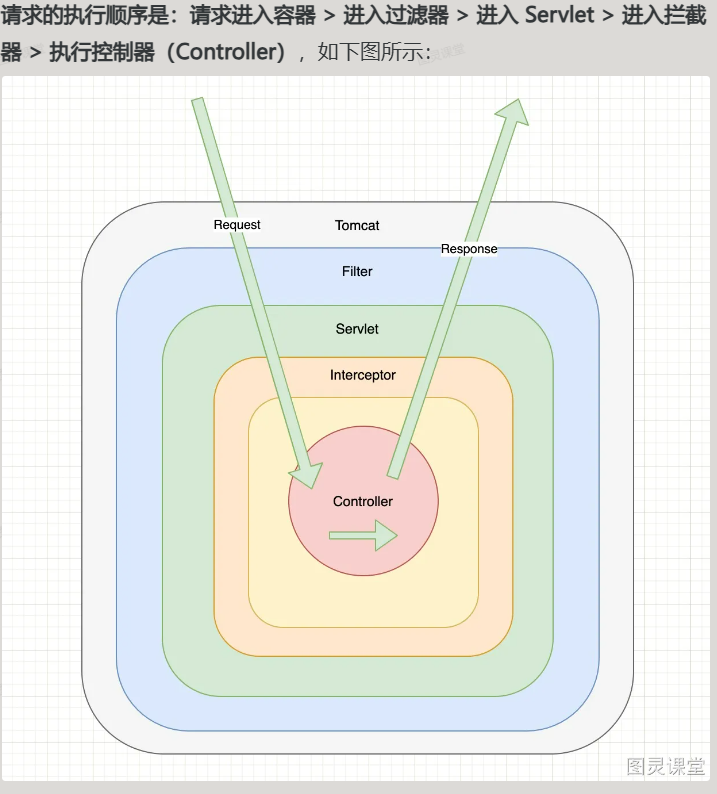
- 过滤器来自Servlet,而拦截器属于Spring框架中的
- 请求进入容器->过滤器->Servlet->进入拦截器->执行Controller
- 过滤器是基于方法回调,doFilter来执行的,而拦截器则是基于动态代理实现的


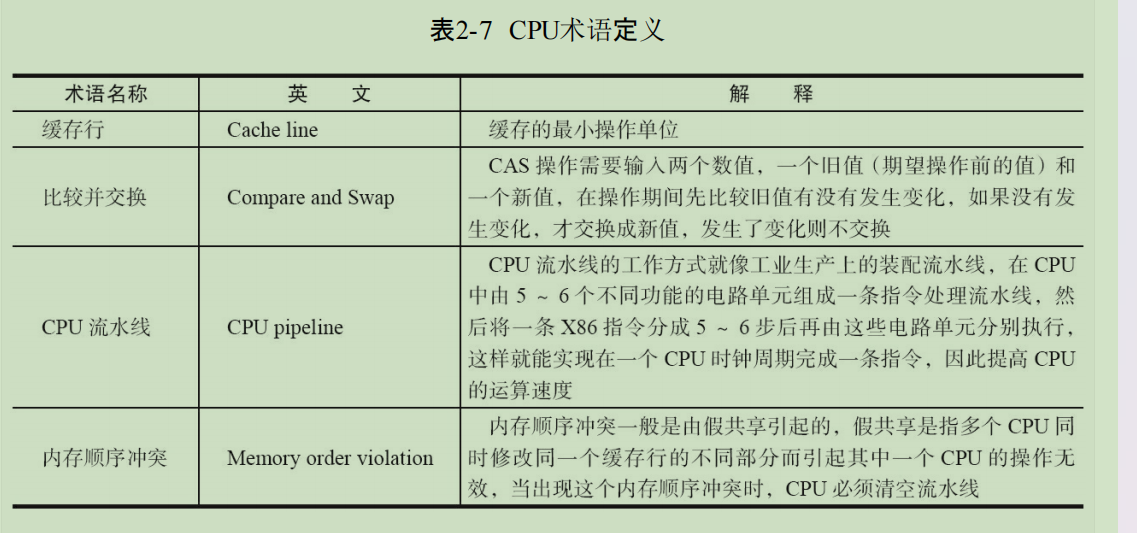
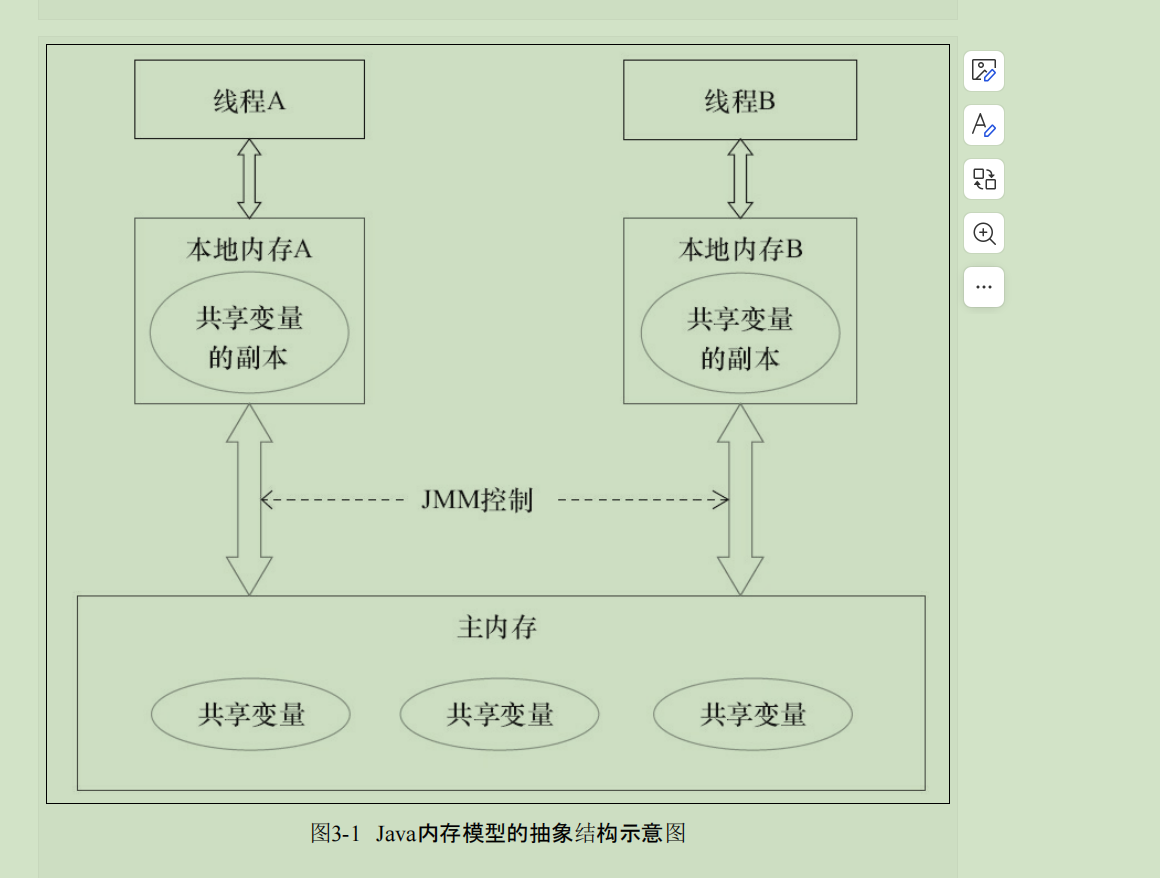
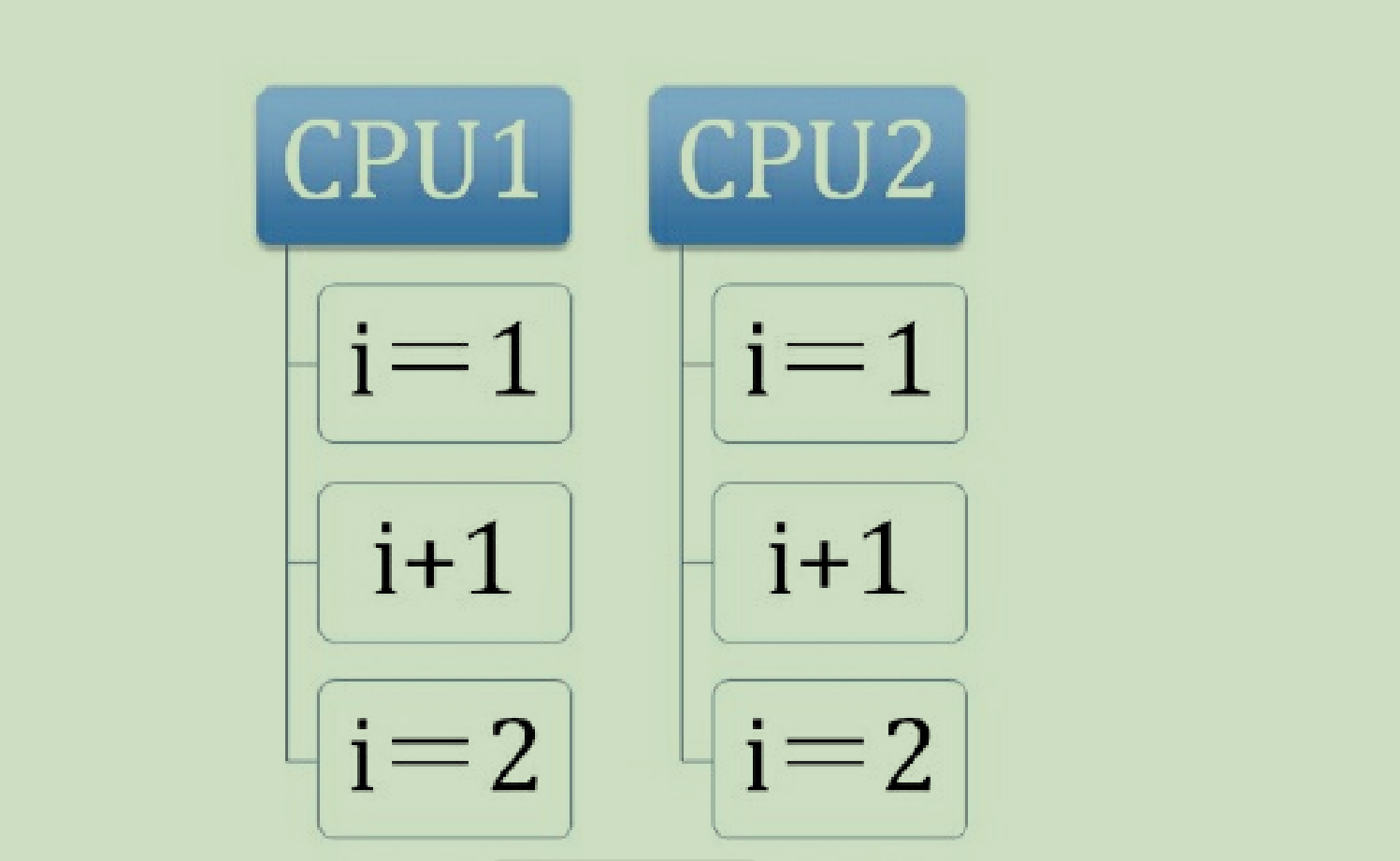 因为他们会从自己的缓存中读取变量i,然后分别进行+1,之后分别写入系统内存中
因为他们会从自己的缓存中读取变量i,然后分别进行+1,之后分别写入系统内存中