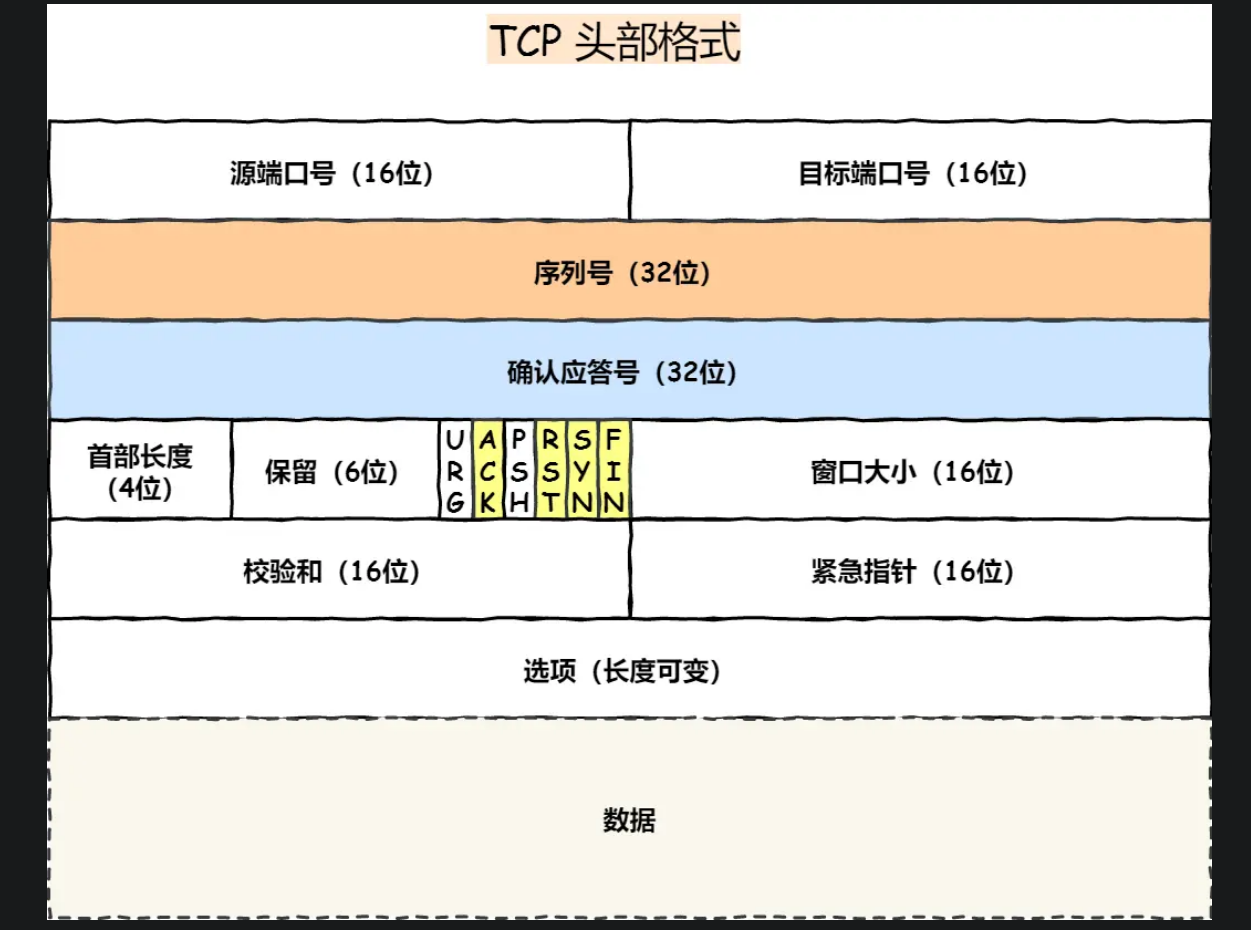
JAVA 快写
TreeMap
TreeMap<Integer, Integer> map = new TreeMap<>();
map.getOrDefault(key,0) 获得这个数,如果为空,返回默认值,可以自己设定
k = map.higherKey(k); 获得下一个顺序的键
把toCharArray向右移动一位
a = (' '+ re.readLine()).toCharArray();
a ~ z 之间偏移量确认
a[i] = (char)('a' + ((a[i] + offset - 'a')%26));
看到唯一解,且是难以做的图形题,可以考虑转化为方程
https://www.lanqiao.cn/problems/17160/learning/?contest_id=179
卡特兰数问题 :h[n]=C[2n,n]−C [2n,n−1] (n=0,1,2,…) 组合数C不解释了; C是组合数
- 出栈顺序问题 假设有N个数字依次入栈:1,2,3,…,n,试问有多少种出栈顺序?这里为表述简便,下文用+1表示一个元素入栈,用-1表示一个元素出栈
- 问题描述:有n对()括号,试问可以组成多少种合法正确的括号序列?
树是无向边
Java日期
LocalDate d1 = LocalDate.parse(s,java.time.format.DateTimeFormatter.BASIC_ISO_DATE);
s = reader.readLine();
LocalDate d2 = LocalDate.parse(s,java.time.format.DateTimeFormatter.BASIC_ISO_DATE);
long diff = ChronoUnit.DAYS.between(d1, d2);
System.out.println(Math.abs(diff)+1);
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(System.out));
writer.flush() 才会写
StreamTokenizer reader = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
reader.nextToken();
n = (int) reader.nval;
取余数的小技巧
(x + n) % n 可以保证不会出现负数
先思考再做题,前几个题大概率时模拟题,所以别急着用算法
常用算法
next_permutation(a,a+n); 对数组的前n个数进行全排列,并存储在这个数组中
char a[n][n]
puts(a[i]) 可以直接输出一行,如果不是最后一行还会输出换行符
求 q^0 + q^1 + ..... + q^n
long long t = 1;
while(n--){
t = (t *q + 1) %mod;
}
整数划分https://ac.nowcoder.com/acm/problem/252724
accumulate 求和
快乐的模板:
#include <bits/stdc++.h>
#define ll long long
#define pii pair<int,int>
using namespace std;
void solve(){
return ;
}
int main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);
int T;
cin >> T;
while (T--) solve();
return 0;
}
```
## 小TIPS:
做题思路:
1. 从小数据,小范围推大范围
2. 划分,以及反证,如果要求全部满足一个性质,那么只要有部分不满足我们已经推出来的条件即可不满足所有性质
> 1. 数组和字符串比较字典序是可以直接用大于号小于号比较的
>
> 2. 字典序是指在ASCII码中出现的顺序所以 也就是 a b c 0 1 2 3 ABC 等z
>
> 3. vector <> 可以直接赋值
>
## 牛顿迭代法:
求平方根
例子: f(x)=m,可转化为 g(x)=f(x)-m=0;
迭代公式:_x_n+1 = _x_n − _g_ (_x_n)/ _g_ ′ (_x_n)
例题:[力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台](https://leetcode.cn/problems/sqrtx/submissions/431189596/)
```c++
//f (x) = x2 − a = 0
int mySqrt(int a) {
long x = a;
while (x * x > a) {
x = (x + a / x) / 2;
}
return x;
}
stl和一些内置函数
accumulate(num.begin(),num.end(),0); //第三个参数是初始化要返回的东西
排序
快速排序模板 根据数来分治
先找数字中的中位数,然后递归
注意: while中先递归的左边,那么最后递归的时候就要以j来为界限,递归的顺序无所谓
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int x = q[rand()% (r-l+1)+l]; // 随机取
int i = l - 1, j = r + 1;
while (i < j) {
do i++; while (
q[i] < x);
do j--; while (q[j] > x);
if (i < j) swap(q[i], q[j]); //如果i与j没有相遇,就交换一下
}
quick_sort(q, l, j); //递归处理左右两边
quick_sort(q, j + 1, r);
}
归并排序模板 分治 根据中间两个数为分界线
确定分界点, mid=(l+r)/2
递归排序 left,right
归并 合二为一
模板
void msort(int a[], int l, int r) {
if (l >= r) return;
//确定分界
int mid = l + r >> 1;
//递归
msort(a, l, mid); msort(a, mid + 1, r);
//归并
int k = 0, i = l, j = mid + 1;
while (i <=mid && j <= r) {//左右比较,小的放在辅助数组里,直到有一个指针到达边界
if (a[i] <= a[j]) tmp[k++] = a[i++];
else tmp[k++] = a[j++];
}
//这里继续把另一个没到边界的指针赋值给辅助数组
while (i <= mid) tmp[k++] = a[i++];
while (j <= r)tmp[k++] = a[j++];
//最后把辅助数组的元素还回去
for (int i = l, j = 0; i <= r; i++, j++) a[i] = tmp[j];
}
二分法 二分要保证有解
整数二分
一分为二,一边满足性质,一半不满足,可以来用来寻找性质的边界
两种模板:一种去检查满足的一半,另一种去检查不满足性质的的一半
考虑边界是否会包括进去
先写出 mid=r+l>>1
二分要检查的性质
画图考虑,直线图
思考mid是否会包含
考虑不存在条件时
l = mid + 1 时,输出的是 L , r = mid -1 时 输出的是r
注意死循环,男左女右,查找从右侧往左的时候mid 要 + 1,否则不+1
l + (r - l + 1 >> 1);
更好的二分模板
while(l<=r){
mid = (l + r) >> 1;
if(mid < r) r = mid - 1;
else mid = l + 1;
}
浮点数二分 不要处理边界
思路:通过mid来判断,答案落在缩小的区间内,只要近似值
bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-6; // eps 表示精度,取决于题目对精度的要求
while (r - l > eps)
{
double mid = (l + r) / 2;
if (check(mid)) r = mid;
else l = mid;
}
//或者直接不管精度,直接循环几百次
return l;
}
高精度
加法: 注意要把A设为位数更大的那一个,因为最后的位数取决于位数大的那一个,使用vector容器可以更方便的进行计算和进位和确定位数
逆序存数的每一位
从低位开始计算,之后计算进位
加完之后检查最后一位是否还有进位
返回数字
vector<int> add(vector<int> &A, vector<int> &B)
{
if (A.size() < B.size()) return add(B, A);
vector<int> C;
int t = 0;
for (int i = 0; i < A.size(); i ++ )
{
t += A[i];
if (i < B.size()) t += B[i];
C.push_back(t % 10);
t /= 10;
}
if (t) C.push_back(1);
return C;
}
减法
和加法基本一致,只要变进位为借位即可
// C = A - B, 满足A >= B, A >= 0, B >= 0
vector<int> sub(vector<int> &A, vector<int> &B)
{
vector<int> C;
for (int i = 0, t = 0; i < A.size(); i ++ )
{
t = A[i] - t;
if (i < B.size()) t -= B[i];
C.push_back((t + 10) % 10);
if (t < 0) t = 1;
else t = 0;
}
while (C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}
乘法
vector<int> mul(vector<int>&A,int b){
vector<int>C;
int t=0;
for(int i=0;i<A.size()||t;i++){//出现进位
if(i<A.size()) t+=A[i]*b;
C.push_back(t%10);
t/=10;
}
while(C.size()>1&&C.back()==0) C.pop_back();
//去除前导零
return C;
}
### 除法
vector<int> div(vector<int>&A,int b){
vector<int>C;
int t=0;
for(int i=0;i<A.size();i++){
t=t*10+A[i];
C.push_back(t/b);
t %= b;
}
//这里是清除前置零,不是后置零
reverse(C.begin(),C.end());
while(C.size()>1&&C.back()==0) C.pop_back();
return C;
}
前缀和和差分
构造差分可以用一个空数组,一直执行插入操作即可
前缀和一般初始化为0到n但是只用1到n
二维
S[i, j] = 第i行j列格子左上部分所有元素的和
以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为:
S[x2, y2] - S[x1 - 1, y2] - S[x2, y1 - 1] + S[x1 - 1, y1 - 1]
二维差分: 差分的前缀和就是原数组
给以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵中的所有元素加上c:
S[x1, y1] += c, S[x2 + 1, y1] -= c, S[x1, y2 + 1] -= c, S[x2 + 1, y2 + 1] += c//注意是x2+1,y2+1不是x2,y2
双指针
int x;
int * p1 = &x; // 指针可以被修改,值也可以被修改
const int * p2 = &x; // 指针可以被修改,值不可以被修改(const int)
int * const p3 = &x; // 指针不可以被修改(* const),值可以被修改
const int * const p4 = &x; // 指针不可以被修改,值也不可以被修改
for (int i = 0, j = 0; i < n; i ++ )
{
while (j < i && check(i, j)) j ++ ;
// 具体问题的逻辑
}
常见问题分类:
(1) 对于一个序列,用两个指针维护一段区间
(2) 对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作
Floyd判圈法 龟兔赛跑法 用于判断链表有无环和求出环的长度
两个指针fast slow 都从起始位置出发,fast 一次走2步,slow一次走1步,如果能相遇,则存在环
计算环的长度
让其中一个指针停在环的起点不动,另一个一步一步向前走并记录步数,再次相遇时步数即为环的长度。
寻找环的起点
其中一个指针在环的起点不动,另一个放到起点,两个指针同时一步一步移动,则两指针将会在循环节的起点相遇。
142. 环形链表 II - 力扣(Leetcode)
/**
位运算
思路:
n的第k位是什么? n>>k&1 右移k位与1与得到是0就是0,反之就是1
先把要判断的位置移到最左边
判断
lowbit
解释:cpp的负数使用的补码表示的所以,-x就等于 ~x+1 反码+1
用法:树状数组和求1的个数
import java.util.Scanner;
public class Main {
static int N = (int) 1e5 + 10;
static long[] tree = new long[N];
static int n ;
static int lowbit(int x) {
return x & (-x);
}
static void update(int i ,int x) {
for(int pos = i ; pos <= n; pos += lowbit(pos)) {
tree[pos] += x;
}
}
static long query(int x) {
long sum =0;
for(int pos = x; pos > 0; pos-=lowbit(pos)) {
sum +=tree[pos];
}
return sum;
}
static long ask(int a,int b) {
return query(b) - query(a-1);
}
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
int m =scan.nextInt();
for(int i = 1; i <= n; i ++) {
int x = scan.nextInt();
update(i,x);
}
while(m-- > 0) {
int k = scan.nextInt();
int a = scan.nextInt();
int b = scan.nextInt();
if(k == 0) {
System.out.println(ask(a,b));
} else {
update(a, b);
}
}
scan.close();
}
}
树状数组:对差分和前缀和的利用:
使用情况:
数组不变求区间和
多次修改某个区间,求区间和
将某个区间变为同一个数求区间和
多次修改区间,寻找定点值
模板:
说明:lowbit()奇妙用法…..
#define low
```bit(x) (-x)&x
///或者 int lowbit(int x) {return -x&x;}
int tree[length];//树状数组,长度和原数组相等
//区间修改
void update(int x,int val)
{
while(x){
tree[x]+=val;
x+=lowbit(x);
}
}
//区间求和
int sum(int l,int r){
int ans=0;
while(r){
ans+=tree[r];
r-=lowbit(r);
}
l--;//
while(l){
ans-=tree[l];
l-=lowbit(l);
}
return ans;
}
使用方式:
正常的顶点修改,区间求和直接用
区间修改,求单独一个数 P3368 【模板】树状数组 2 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
树状数组是保存的每一个下标为位置的前缀和
想要求指定位置的数值需要用到差分,差分的前缀和就是每一个位置的数据大小
修改时只需要修改 update(l,val),update(r+1,-val)
初始化时,要插入的是差分
#include <iostream>
#include <algorithm>
#define ll long long
#define lowbit(x) (x&(-x))
using namespace std;
const int mx = 10e5 + 5;
int t[mx], m, n;
int add(int x, int k) {
while (x <= n) {
t[x] += k;
x += lowbit(x);
}
}
int query(int x){
ll ans=0;
while(x){
ans+=t[x];
x-=lowbit(x);
}
return ans;
}
//用差分来的前缀和来表示每一位置上的数字,
//第一个数字之后,每次把差分加入,再求前缀和就能得到每一个位置上的数字是多少了
//修改时只需要修改x和y+1两个位置的差分,但是我们用的tree是前缀和,所以依然要用把和lowbit有关的都修改 了
int main() {
cin >> n >> m;
int cf=0;
for (int i = 1; i <= n; i++) {
int num;
scanf("%d", &num);
add(i,num-cf);
cf=num;
}
for (int i = 1; i <= m; i++) {
int ch, x, y,k;
scanf("%d", &ch);
if (ch == 1){
scanf("%d %d %d", &x, &y, &k);
add(x,k);
add(y+1,-k);
}
else {
int s;
scanf("%d", &s);
printf("%d\n", query(s));
}
}
return 0;
}
用指定数据替换某个数据,然后求和 307. 区域和检索 - 数组可修改 - 力扣(Leetcode)
更换数据也是用到了差分,新的数据-原数据==要更新的val
然后更新之后,原数组指定位置也要更新,方便下次修改同一位置
其他正常食用即可
class NumArray {
int []t;
int n;
int []nums;
int lowbit(int x){return x&(-x);}
public NumArray(int[] nums) {
this.nums=nums;
n=nums.length;
t=new int[n+1];
int i=1;
for (int num:nums
) {
add(i++,num);
}
}
void add(int index,int val){
while(index<=n){
t[index]+=val;
index+=lowbit(index);
}
}
public void update(int index, int val) {
add(index+1,val-nums[index]);
nums[index]=val;
}
public int sumRange(int left, int right) {
int ans=0;
right++;
while(right>0){
ans+=t[right];
right-=lowbit(right);
}
while(left>0){
ans-=t[left];
left-=lowbit(left);
}
return ans;
}
}
/**
* Your NumArray object will be instantiated and called as such:
* NumArray obj = new NumArray(nums);
* obj.update(index,val);
* int param_2 = obj.sumRange(left,right);
*/
求1的个数
#include <algorithm>
#include <vector>
#include <iostream>
#define lowbit(x) (-x)&x
using namespace std;
int main(){
int n,ans=0;
cin>>n;
while(n){
ans++;
n-=lowbit(n);
}
cout<<ans<<endl;
return 0;
}
离散化
unique 返回的是下下标
vector<int> alls; // 存储所有待离散化的值
sort(alls.begin(), alls.end()); // 将所有值排序
alls.erase(unique(alls.begin(), alls.end()), alls.end()); // 去掉重复元素
//配合erase 即可把放在后面的重复元素删除
/*
该函数的作用是“去除”容器或者数组中相邻元素的重复出现的元素
(1) 这里的去除并非真正意义的erase,而是将重复的元素放到容器的末尾,返回值是去重之后的尾地址。
(2) unique针对的是相邻元素,所以对于顺序顺序错乱的数组成员,或者容器成员,需要先进行排序,可以调用std::sort()函数
// 二分求出x对应的离散化的值*/
int find(int x) // 找到第一个大于等于x的位置
{
int l = 0, r = alls.size() - 1;
while (l < r)
{
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r + 1; // 映射到1, 2, ...n
}
区间和并
每次维护一个右端点
// 将所有存在交集的区间合并
void merge(vector<PII> &segs)
{
vector<PII> res;
sort(segs.begin(), segs.end());//根据first进行排序,默认的就是这样的不需要进行自定义
int st = -2e9, ed = -2e9;
for (auto seg : segs)
if (ed < seg.first)
{
//当起点的值大于右端点的时候,一段区间结束,可以继续下一段区间了
if (st != -2e9) res.push_back({st, ed});
st = seg.first, ed = seg.second;
} g
else ed = max(ed, seg.second);//如果左没大于右端点,那么右端点每次更新完为最大值
if (st != -2e9) res.push_back({st, ed});
segs = res;
}
数组模拟链表
单链表
int head,e[N],ne[N],idx;
void init(){
head=-1;
idx=0;
}
//头插
//head 也是指针,e[idx] 新节点
void add_head(int x){
e[idx]=x;//插入数据
ne[idx]=head;//idx 当前的位置的指针指向head指向的位置 -1
head=idx;//head 指针指向idx
idx++;
}
//插入任意位置
void insert_linkedlist(int k,int x){
e[idx]=x;//建立新节点
ne[idx]=ne[k];//新节点指向k的下一个节点
ne[k]=ne[idx]; //k指向idx这个结点
idx++;
}
void delete_linkedlist(int k){
ne[k]=ne[ne[k]];
}
int main(){
int k,x,m;
char op;
cin>>m;
init();
while(m--){
cin>>op;
if(op=='h'){
cin>>x;
add_head(x);
}
else if(op=='d'){
cin>>k;
delete_linkedlist(k-1);
}
else {
cin>>k>>x;
insert_linkedlist(k-1,x);
}
}
for(int i=head;i!=-1;i=ne[i]){cout<<e[i]<<' ';}
return 0;
}
双链表
// e[]表示节点的值,l[]表示节点的左指针,r[]表示节点的右指针,idx表示当前用到了哪个节点
int e[N], l[N], r[N], idx;
// 初始化
void init()
{
//0是左端点,1是右端点
r[0] = 1, l[1] = 0;
idx = 2;
}
// 在节点a的右边插入一个数x
void insert(int a, int x)
{
e[idx] = x;
l[idx] = a, r[idx] = r[a];
l[r[a]] = idx, r[a] = idx ++ ;
}
// 删除节点a
void remove(int a)
{
l[r[a]] = l[a];
r[l[a]] = r[a];
}
栈
// tt表示栈顶
int stk[N], tt = 0;
// 向栈顶插入一个数
stk[ ++ tt] = x;
// 从栈顶弹出一个数
tt -- ;
// 栈顶的值
stk[tt];
// 判断栈是否为空,如果 tt > 0,则表示不为空
if (tt > 0)
{
}
单调栈
注意这个题目要的是结果的下标不是具体的数据
用栈暴力模拟一遍,然后再考虑哪些元素没有用处,就可以排除
P5788 【模板】单调栈 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
#include<iostream>
#include <cstdio>
#define ll long long
using namespace std;
const ll N=3*1000000+1;
ll stk[N],a[N],ans[N];
int tt=0;
int main(){
int n;
cin>>n;
for(int i=1;i<=n;i++){
scanf("%lld",&a[i]);
}
for(int i=n;i>0;i--){
while(tt!=0&&a[i]>=a[stk[tt]]) tt--;
ans[i]= tt==0?0:stk[tt];
stk[++tt]=i;
}
for(int i=1;i<=n;i++)printf("%lld ",ans[i]);
return 0;
}
队列
// hh 表示队头,tt表示队尾
int q[N], hh = 0, tt = -1;
// 向队尾插入一个数
q[ ++ tt] = x;
// 从队头弹出一个数
hh ++ ;
// 队头的值
q[hh];
// 判断队列是否为空,如果 hh <= tt,则表示不为空
if (hh <= tt)
{
}
单调队列 (好东西)
几个点:
初始化时,hh=0,tt=-1 使得队列为空
比较的是队尾元素与当前元素
注意队列长度为0时不要输出
常见模型:找出滑动窗口中的最大值/最小值
int hh = 0, tt = -1;
for (int i = 0; i < n; i ++ )
{
while (hh <= tt && check_out(q[hh])) hh ++ ; // 判断队头是否滑出窗口
while (hh <= tt && check(q[tt], i)) tt -- ;
q[ ++ tt] = i;
}
例题
P1886 滑动窗口 /【模板】单调队列 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
#include<iostream>
#include <cstdio>
#define ll long long
using namespace std;
const int N=1000000+2;
int n,k,a[N],q[N],ans,hh,tt;
int main(){
cin>>n>>k;
for(int i=0;i<n;i++){
scanf("%d",&a[i]);
}
//队列存的是下标
//最小值
hh=0;tt=-1;//目的是让队列初始化为空
for(int i=0;i<n;i++){
//判断队列是否为空
if(hh<=tt&&i-k+1>q[hh]) hh++;
//目的是把最小的元素放在队头
while(hh<=tt&&a[q[tt]]>=a[i]) tt--;//从队尾删除,因为经过我们的处理,已经是严格单调递增的了,所以如果第一个都大于这个元素的话,那么后面几个都大于,所以要删除
q[++tt]=i;
if(i>=k-1)
printf("%d ",a[q[hh]]);
}
cout<<endl;
//最大值
hh=0;tt=-1;
for(int i=0;i<n;i++){
//判断队列是否为空
if(hh<=tt&&i-k+1>q[hh]) hh++;
//目的是把最大的元素放在队头
while(hh<=tt&&a[q[tt]]<=a[i]) tt--;
q[++tt]=i;
if(i>=k-1)
printf("%d ",a[q[hh]]);
}
return 0;
}
KMP
对称的 ,以j这个点为中点的前后缀是相同的,所以可以直接变成next[ j ]

s从1开始,p从0开始
// s[]是长文本,p[]是模式串,n是s的长度,m是p的长度
求模式串的Next数组:ne[1]=0 ,一开始就错了肯定从零开始
for (int i = 2, j = 0; i <= m; i ++ )
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++ ;
ne[i] = j;
}
// 匹配
for (int i = 1, j = 0; i <= n; i ++ )
{
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++ ;
if (j == m)
{
j = ne[j];
// 匹配成功后的逻辑
}
}
例题
P3375 【模板】KMP字符串匹配 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
#include <iostream>
#include <cstring>
#define N 1000010
using namespace std;
char s[N],p[N];
int ls,lp,ne[N];
int main(){
cin>>s+1>>p+1;
ls=strlen(s+1);
lp=strlen(p+1);
for(int i=2,j=0;i<=lp;i++){
while(j&&p[i]!=p[j+1]) j=ne[j];
if(p[j+1]==p[i]) j++;
ne[i]=j;
}
for(int i=1,j=0;i<=ls;i++){
while(j&&s[i]!=p[j+1]) j=ne[j];
if(s[i]==p[j+1]) j++;
if(j==lp){
cout<<i-lp+1<<endl;
j=ne[j];
}
}
for(int i=1;i<=lp;i++){
cout<<ne[i]<<" ";
}
return 0;
}
Trie树 高效存储和查找字符串
集合的数据结构
将字符串分解为一个一个单独的字符然后存储,然后查询这个字符串是否出现过,
出现过几次
更全面 的映射
int getnum(char x){
if(x>='A'&&x<='Z')
return x-'A';
else if(x>='a'&&x<='z')
return x -'a'+26;
else
return x-'0'+52;
}
#include<iostream>
#include <algorithm>
#include <cstdio>
using namespace std;
const int N=100010;
int son[N][26],cnt[N],idx;//子子节点的个数,只包含26个 小写字母 cnt是以这个字母为结尾的单词出现了福哦少个
//idx 当前用到哪了
//插入操作
char str[N];
void insert(char str[]){
int p=0;//当前的结点
for(int i=0;str[i];i++){
int u=str[i]-'a';//将26个小写字母映射为数字
if(!son[p][u]) son[p][u]=++idx;
p=son[p][u];
}
cnt[p]++;
}
int query(char str[]){
int p=0;
for(int i=0;str[i];i++){
int u=str[i]-'a';
if(!son[p][u]) return 0;
p=son[p][u];
}
return cnt[p];
}
int main(){
int n;
cin>>n;
while(n--){
char op[2];
cin>>op>>str;
if(op[0]=='i') insert(str);
else cout<<query(str)<<endl;
}
return 0;
}
P8306 【模板】字典树 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
#include<iostream>
#include <algorithm>
#include <cstdio>
#include <cstring>
using namespace std;
const int N=3000005;
int son[N][65],cnt[N],idx;//子子节点的个数,只包含26个 小写字母 cnt是以这个字母位借位的单词出现了福哦少个
//idx 当前用到哪了
//插入操作
int n,m,t;
char str[N];
int hashs(char x){
if(x>='A'&&x<='Z')
return x-'A';
else if(x>='a'&&x<='z')
return x-'a'+26;
else
return x-'0'+52;
}
void insert(char str[]){
int p=0;//当前的结点
int l=strlen(str);
for(int i=0;i<l;i++){
int u=hashs(str[i]);//将26个小写字母映射为数字
if(!son[p][u]) son[p][u]=++idx;
p=son[p][u];
cnt[p]++;
}
}
int query(char str[]){
int p=0;//当前的结点
int l=strlen(str);
for(int i=0;i<l;i++){
int u =hashs(str[i]);
if(!son[p][u]) return 0;
p=son[p][u];
}
return cnt[p];
}
int main(){
cin>>t;
while(t--){
for(int i=0;i<=idx;i++){
for(int j=0;j<=122;j++){
son[i][j]=0;
}
}
for(int i=0;i<=idx;i++)
cnt[i]=0;
idx=0;
scanf("%d%d",&n,&m);
while(n--){
scanf("%s",str);
insert(str);
}
while(m--){
scanf("%s",str);
printf("%d\n",query(str));
}
}
return 0;
}
并查集
用法:
某些点或者数据是否处于一个连通块中
将两个集合合并
询问两个元素是否在一个集合中
基本原理:每个集合用一个树来表示,树根的编号就是整个集合的编号,
每一个结点表示他的父节点p[x] 表示x的父节点
判断树根: if(p[x]==x)
如何集合的编号: while(p[x]!=x) x=p[x];
如何合并两个集合直接让其中一个的根节点的父节点为另一个集合的根节点就行
如何优化,查询一次后,将将所经过的路径的父节点全都修改为根节点
#include<iostream>
#include <algorithm>
#include <cstdio>
#include <cstring>
using namespace std;
const int N=10010;
int p[N];
//初始每个点都是一个单独的集合
void init(int n){
for(int i=1;i<=n;i++){
p[i]=i;
}
}
int find(int x){
if(p[x]!=x) p[x]=find(p[x]);
return p[x];
}
int main(){
int n,m;
cin>>n>>m;
init(n);
char op[2];
while(m--){
int a,b;
cin>>op>>a>>b;
//合并两个集合,路径压缩
if(op[0]=='i') p[find(a)]=find(b);//让a的父节点等于b的父节点,即可合并
else {
//查询
if(find(a)==find(b)) cout<<"yes"<<endl;
else cout<<"no"<<endl;
}
}
return 0;
}
P3367 【模板】并查集 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
维护点的数量:
#include<iostream>
#include <algorithm>
#include <cstdio>
#include <cstring>
using namespace std;
const int N=10010;
int p[N],sizes[N];//每个集合中点的数量
//初始每个点都是一个单独的集合
void init(int n){
for(int i=1;i<=n;i++){
p[i]=i;
sizes[i]=1;
}
}
int find(int x){
if(p[x]!=x) p[x]=find(p[x]);
return p[x];
}
int main(){
int n,m;
cin>>n>>m;
init(n);
int op;
while(m--){
int a,b;
cin>>op;
//合并两个集合,路径压缩
if(op==1){
cin>>a>>b;
if(find(a)==find(b)) continue;
sizes[find(b)]+=sizes[find(a)];
p[find(a)]=find(b);//让a的父节点等于b的父节点,即可合并
}
else if(op==2){
//查询
cin>>a>>b;
if(find(a)==find(b)) cout<<"Y"<<endl;
else cout<<"N"<<endl;
}
else {
//询问某个集合中点的数量
cin>>n;
cout<<sizes[find(a)]<<endl;
}
}
return 0;
}
堆 只能保证堆顶是最值,保证不了左右两边的大小关系
操作:down 和up 把元素向下或向上走,使用的是一维数组,x的左儿子2x,右儿子2x+1
size 表示数组的最后一个位置
插入一个元素: heap[++size]=x up(size)
求最小值 heap[1]
删除最小值 数组尾部好删除,所以用最后一个元素覆盖数组的头,然后执行down,
再删除尾部,head[k]=heap[size];size–; down(k)||up(k)
修改 heap[k]=k; down(k)||up(k);
// h[N]存储堆中的值, h[1]是堆顶,x的左儿子是2x, 右儿子是2x + 1
// ph[k]存储第k个插入的点在堆中的位置
// hp[k]存储堆中下标是k的点是第几个插入的
int h[N], ph[N], hp[N], size;
// 交换两个点,及其映射关系
void heap_swap(int a, int b)
{
swap(ph[hp[a]],ph[hp[b]]);
swap(hp[a], hp[b]);
swap(h[a], h[b]);
}
void down(int u)
{
int t = u;
//查找到三个结点中的最小值
if (u * 2 <= size && h[u * 2] < h[t]) t = u * 2;
if (u * 2 + 1 <= size && h[u * 2 + 1] < h[t]) t = u * 2 + 1;
if (u != t)
{
heap_swap(u, t);
down(t);
}
}
void up(int u)
{
while (u / 2 && h[u] < h[u / 2])//父节点存在且当前结点小于父节点
{
heap_swap(u, u / 2);
u >>= 1;//下一个父节点
}
}
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
P3378 【模板】堆 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
#include <bits/stdc++.h>
using namespace std;
const int N=1000001;
int h[N],s;
void down(int u){
int t=u;
if(u*2<=s&&h[u*2]<h[t]) t=u*2;
if(u*2+1<=s&&h[u*2+1]<h[t]) t=u*2+1;
if(u!=t){
swap(h[u],h[t]);
down(t);
}
}
void up(int u){
while(u/2&&h[u]<h[u/2]){
swap(h[u],h[u/2]);
u>>=1;
}
}
int main(){
int n,op;
cin>>n;
for(int i=n/2;i;i--){
down(i);
}
while(n--){
scanf("%d",&op);
if(op==1) {
int x;
scanf("%d",&x);
h[++s]=x;
up(s);
}
else if(op==2){
printf("%d\n",h[1]);
}
else {
//最后一个换到第一个
swap(h[1],h[s]);
s--;//删除最后一个
down(1);
}
}
}
HashTable
删除的话打个标记
(1) 拉链法
int h[N], e[N], ne[N], idx;
// 向哈希表中插入一个数
void insert(int x)
{
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx ++ ;
}
// 在哈希表中查询某个数是否存在
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
开放寻址法,遇到冲突的话直接往后找没用的节点
数组要开比原来数据范围大2~3倍
//只要开一个h数组就可以了,不需要e和ne了,找一个不在数据范围内的数据来表示当前位置为空
(2) 开放寻址法
int h[N];
const int null =xxx;
// 如果x在哈希表中,返回x的下标;如果x不在哈希表中,返回x应该插入的位置
int find(int x)
{
int t = (x % N + N) % N;
while (h[t] != null && h[t] != x)
{
t ++ ;
if (t == N) t = 0;
}
return t;
}
字符串哈希
快速判断两个字符串是否相等
核心思想:将字符串看成P进制数,P的经验值是131或13331,取这两个值的冲突概率低
小技巧:取模的数用2^64,这样直接用unsigned long long存储,溢出的结果就是取模的结果
typedef unsigned long long ULL;
ULL h[N], p[N]; // h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;//P存储的是每一位的基数值
}
// 计算子串 str[l ~ r] 的哈希值
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
STL常用
vector, 变长数组,倍增的思想 优化思路:减少申请空间的次数
size() 返回元素个数
empty() 返回是否为空
clear() 清空
front()/back()
push_back()/pop_back()
begin()/end()
[]
支持比较运算,按字典序
vector<int> a(1,2),b(3,4);
printf(a<b) == 0
pair<int, int>
first, 第一个元素
second, 第二个元素
支持比较运算,以first为第一关键字,以second为第二关键字(字典序)
string,字符串
size()/length() 返回字符串长度
empty()
clear()
substr(起始下标,(子串长度)) 返回子串
c_str() 返回字符串所在字符数组的起始地址
queue, 队列
size()
empty()
push() 向队尾插入一个元素
front() 返回队头元素
back() 返回队尾元素
pop() 弹出队头元素
priority_queue, 优先队列,默认是大根堆
size()
empty()
push() 插入一个元素
top() 返回堆顶元素
pop() 弹出堆顶元素
定义成小根堆的方式:priority_queue<int, vector<int>, greater<int>> q;
stack, 栈
size()
empty()
push() 向栈顶插入一个元素
top() 返回栈顶元素
pop() 弹出栈顶元素
deque, 双端队列
size()
empty()
clear()
front()/back()
push_back()/pop_back()
push_front()/pop_front()
begin()/end()
[]
set, map, multiset, multimap, 基于平衡二叉树(红黑树),动态维护有序序列
size()
empty()
clear()
begin()/end()
++, -- 返回前驱和后继,时间复杂度 O(logn)
set/multiset
insert() 插入一个数
find() 查找一个数
count() 返回某一个数的个数
erase()
(1) 输入是一个数x,删除所有x O(k + logn)
(2) 输入一个迭代器,删除这个迭代器
lower_bound()/upper_bound()
lower_bound(x) 返回大于等于x的最小的数的迭代器
upper_bound(x) 返回大于x的最小的数的迭代器
map/multimap
insert() 插入的数是一个pair
erase() 输入的参数是pair或者迭代器
find()
[] 注意multimap不支持此操作。 时间复杂度是 O(logn)
lower_bound()/upper_bound()
unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表
和上面类似,增删改查的时间复杂度是 O(1)
不支持 lower_bound()/upper_bound(), 迭代器的++,--
bitset, 圧位 省空间
bitset<10000> s; //< >里面是个数, 可以用来替代bool 数组
//以下操作都支持
~, &, |, ^
>>, <<
==, !=
[]
count() 返回有多少个1
any() 判断是否至少有一个1
none() 判断是否全为0
set() 把所有位置成1
set(k, v) 将第k位变成v
reset() 把所有位变成0
flip() 等价于~
flip(k) 把第k位取反
图论背思路
BFS和DFS
还原现场很重要
static boolean dfs(int start,int num) {
if(num == n) return true;
for (int i = 0 ; i < n; i ++) {
if(node.get(i).charAt(0) - 'a' == start && st[i] == 0) {
st[i] = 1;
ans.add(i);
if(dfs(node.get(i).charAt(node.get(i).length() - 1)-'a',num+1)) return true;
st[i] = 0;
ans.remove(ans.size() - 1);
}
}
return false;
}
DFS 回溯的时候记得回复现场
邻接矩阵: p[ a] [ b ] a -> b 适合稠密图
邻接表: 稀疏图
和哈希表思路一样
// 对于每个点k,开一个单链表,存储k所有可以走到的点。h[k]存储这个单链表的头结点
int h[N], e[N], ne[N], idx; //e是终点end
// 添加一条边a->b
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
// 初始化
idx = 0;
memset(h, -1, sizeof h);
//遍历图
for(int i = h[t] ; i != -1 ; i = ne[i] )
## 另一种使用结构体的邻接表存法
int idx=0,n;
int h[N] , dis[N] , vis[N];
struct Edge{
int ne,to,dis;
}ed[N];
//添加, 从 1 开始
void add(int a,int b ,int c){
ed[++idx].ne = h[a];
ed[idx].to = b;
ed[idx].dis = c;
h[a] = idx;
}
//遍历图
for(int i = h[t] ; i ; i = ed[i].ne)
BFS 可用于解决权值相等的最短路径问题
拓扑排序
必须是又向无环
排完后,所有的起点都在终点之前
统计每一个节点的入度和出度
每一次将入读相同的点放入queue
枚举队头的出边,删掉 出边,这条边的终点的入度-1
如果某个点的入度为0 放入队列
bool topsort()
{
int hh = 0, tt = -1;
// d[i] 存储点i的入度
for (int i = 1; i <= n; i ++ )
if (!d[i])
q[ ++ tt] = i;//把每个入度为0的点加入队列
while (hh <= tt)
{
int t = q[hh ++ ];//取出队头
//从队头开始找路径
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (-- d[j] == 0)
q[ ++ tt] = j;
}
}
// 如果所有点都入队了,说明存在拓扑序列;否则不存在拓扑序列。
return tt == n - 1;
}
最短路问题:
_分层最短路_,适用于乘车路线和免费次数。
飞机路线
单源最短路 一个点./.到其他所有点的最短路
所有边的权都是正数
- 朴素Dijkstra O(n^2) n为点的数量 稠密图 边很多 外部迭代n-1 次
int g[N][N]; // 存储每条边 权值
int dist[N]; // 存储1号点到每个点的最短距离
bool st[N]; // 存储每个点的最短路是否已经确定
// 求1号点到n号点的最短路,如果不存在则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 0; i < n - 1; i ++ )//迭代n-1 次,因为上来选中了一个点
{
int t = -1; // 在还未确定最短路的点中,寻找距离最小的点
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
// 用t更新其他点的距离
for (int j = 1; j <= n; j ++ )
dist[j] = min(dist[j], dist[t] + g[t][j]);
st[t] = true;
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
- 堆优化版的 O(mlogn) 稀疏图
typedef pair<int, int> PII;
int n; // 点的数量
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N]; // 存储所有点到1号点的距离
bool st[N]; // 存储每个点的最短距离是否已确定
// 求1号点到n号点的最短距离,如果不存在,则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;
heap.push({0, 1}); // first存储距离,second存储节点编号
while (heap.size())
{
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;
if (st[ver]) continue;
st[ver] = true;
for (int i = h[ver]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > distance + w[i])
{
dist[j] = distance + w[i];
heap.push({dist[j], j});
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
存在负权边
Bellman -Ford O(nm) 奇妙的存图方式 无负权回路 经过路径有次数限制的话只能用这个了,外面限制的是经过i的点的个数,然后每次遍历边即可。
int n, m; // n表示点数,m表示边数
int dist[N]; // dist[x]存储1到x的最短路距离
struct Edge // 边,a表示出点,b表示入点,w表示边的权重
{
int a, b, w;
}edges[M];
// 求1到n的最短路距离,如果无法从1走到n,则返回-1。
int bellman_ford()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
//不需要进行收录顶点
// 如果第n次迭代仍然会松弛三角不等式,就说明存在一条长度是n+1的最短路径,由抽屉原理,路径中至少存在两个相同的点,说明图中存在负权回路。
for (int i = 0; i < n; i ++ )//这个n是指的是最多不经过 多少次经过同一条边
{
for (int j = 0; j < m; j ++ )
{
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
if (dist[b] > dist[a] + w)
dist[b] = dist[a] + w;
}
}
if (dist[n] > 0x3f3f3f3f / 2) return -1;
return dist[n];
}
SPFA 一般: O(m) 最坏O(nm) 不存在负权环才能使用 99%都没有负环比较好用
优化思路:只有更新过点才对后面的点更新有影响
要从 1 开始存比较好 ,e 是end 也就是一条边的终点
int n; // 总点数
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N]; // 存储每个点到1号点的最短距离
bool st[N]; // 存储每个点是否在队列中
// 求x号点到n号点的最短路距离,如果从1号点无法走到n号点则返回-1
int spfa(int x)
{
memset(dist, 0x3f, sizeof dist);//初始化要根据题目来
dist[x] = 0;
/*或者
for(int i = 1 ; i <= n ; i ++){
dis[i] = INT_MAX;
}*/
queue<int> q;
q.push(x);
while (q.size())//不为空,即为还有更新的点
{
auto t = q.front();
q.pop();
st[t] = false;//这里不要忘记
//遍历所以能到达的顶点,进行更新
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
if (!st[j]) // 如果队列中已存在j,则不需要将j重复插入
{
q.push(j);//这里是j
st[j] = true;//这里是j
}
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
//初始化和存图
void add(int a, int b , int c){
w[idx] = c;
ne[idx] = h[a];
en[idx] = b;
h[a] = idx++;
}
void init(){
idx = 1;
memset(h , -1 ,sizeof h);
}
模板题:
P3371 【模板】单源最短路径(弱化版) - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
==判断有无负环 用cnt 来记录当前最短路的边数
例题: 负环路
int n; // 总点数
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N], cnt[N]; // dist[x]存储1号点到x的最短距离,cnt[x]存储1到x的最短路中经过的点数
bool st[N]; // 存储每个点是否在队列中
// 如果存在负环,则返回true,否则返回false。
bool spfa()
{
// 不需要初始化dist数组
// 原理:如果某条最短路径上有n个点(除了自己),那么加上自己之后一共有n+1个点,由抽屉原理一定有两个点相同,所以存在环。
queue<int> q;
for (int i = 1; i <= n; i ++ )
{
q.push(i);
st[i] = true;
}
while (q.size())
{
auto t = q.front();
q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
cnt[j] = cnt[t] + 1;
if (cnt[j] >= n) return true; // 如果从1号点到x的最短路中包含至少n个点(不包括自己),则说明存在环
if (!st[j])
{
q.push(j);
st[j] = true;
}
}
}
}
return false;
}
多源汇最短路 起点终点都不确定
Floyd O(n^3)
初始化:
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
if (i == j) d[i][j] = 0;
else d[i][j] = INF;
// 算法结束后,d[a][b]表示a到b的最短距离
void floyd()
{
for (int k = 1; k <= n; k ++ )
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);// i经过k 点到达j
}
最小生成树
普利姆算法 Prim 思路和Dijsktra算法相似 外部迭代 n 次,因为没有提前选中一个点
迭代n次因为没有提前选中一个点 枚举所有点
朴素Prim算法 稠密图 每次找到未收录的距离最近的点,收录并进行更新其他点到集合的距离
找这个点是否与集合内部相连
某个点到这个集合的距离为某个点到这个集合当中的点的距离最短的边
int n; // n表示点数
int g[N][N]; // 邻接矩阵,存储所有边
int dist[N]; // 存储其他点到当前最小生成树的距离
bool st[N]; // 存储每个点是否已经在生成树中
// 如果图不连通,则返回INF(值是0x3f3f3f3f), 否则返回最小生成树的树边权重之和
int prim()
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
for (int i = 0; i < n; i ++ )
{
int t = -1;
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
if (i && dist[t] == INF) return INF;
if (i) res += dist[t];
st[t] = true;
for (int j = 1; j <= n; j ++ ) dist[j] = min(dist[j], g[t][j]);
//不是相加
}
return res;
}
堆优化版的Prim 稀疏图 不常用
克鲁斯卡尔算法 Kruskal 先对边进行排序 稀疏图 可以用并查集 枚举所有边
java版本:
package bronya;
import java.io.*;
import java.math.BigInteger;
import java.util.*;
class Edge {
int a , b , w;
public Edge(int a , int b , int w) {
this.a = a;
this.b = b;
this.w = w;
}
}
public class Main{
static int N = (int) ((int) 2 * 1e5 + 10);
static int n , m ;
static int[] p = new int[N];
static Edge[] ed = new Edge[N];
static long ans = 0;
static int find(int x) {
if(x != p[x]) p[x] = find(p[x]);
return p[x];
}
static boolean check() {
for(int i = 1; i <= n ; i ++) {
p[i] = i;
}
Arrays.sort(ed,0,m,(e1,e2)->e1.w - e2.w);
int cnt = 0;
for(int i = 0 ; i < m ; i ++) {
int a = ed[i].a;
int b = ed[i].b;
int w = ed[i].w;
a = find(a);
b = find(b);
if(a != b) {
p[a] = b;
ans += w;
cnt ++;
}
}
if(cnt < n - 1) return false;
else return true;
}
public static void main(String[] args) throws IOException {
BufferedReader re = new BufferedReader(new InputStreamReader(System.in));
String[] s = re.readLine().split(" ");
n = Integer.parseInt(s[0]);
m = Integer.parseInt(s[1]);
for(int i = 0 ; i < m ; i ++) {
s = re.readLine().split(" ");
int a = Integer.parseInt(s[0]);
int b = Integer.parseInt(s[1]);
int w = Integer.parseInt(s[2]);
ed[i] = new Edge(a, b, w);
}
boolean f = check();
if(f) System.out.println(ans);
else System.out.println("orz");
}
}
P3366 【模板】最小生成树 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
所有边按权重从小到大排序
枚举每条边a,b权重c if a,b不连通, 将这条边加入集合中
int n, m; // n是点数,m是边数
int p[N]; // 并查集的父节点数组
struct Edge // 存储边
{
int a, b, w;
bool operator< (const Edge &W)const // 重载了 <
{
return w < W.w;
}
}edges[M];
int find(int x) // 并查集核心操作
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m);
for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集
int res = 0, cnt = 0;
for (int i = 0; i < m; i ++ )
{
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);
if (a != b) // 如果两个连通块不连通,则将这两个连通块合并
{
p[a] = b;
res += w;
cnt ++ ;
}
}
if (cnt < n - 1) return INF;
return res;
}
二分图 当且仅当图中没有奇数环
染色法 O(n+m) 判断是否是二分图
int n; // n表示点数
int h[N], e[M], ne[M], idx; // 邻接表存储图
int color[N]; // 表示每个点的颜色,-1表示未染色,0表示白色,1表示黑色
// 参数:u表示当前节点,c表示当前点的颜色
bool dfs(int u, int c)
{
color[u] = c;
for (int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if (color[j] == -1)//未染色
{
if (!dfs(j, !c)) return false;//比如两种颜色, 0,1表示,那么这里就可以用 3- c,也就是用另一种颜色去染色
}
else if (color[j] == c) return false;
}
return true;
}
bool check()
{
memset(color, -1, sizeof color);
bool flag = true;
//枚举所有点,去染色
for (int i = 1; i <= n; i ++ )
if (color[i] == -1)
if (!dfs(i, 0))
{
flag = false;
break;
}
return flag;
}
匈牙利算法 O(mn) 实际运行时间一般小于这个值 稠密图不适合用邻接表,推荐使用临界矩阵
int n1, n2; // n1表示第一个集合中的点数,n2表示第二个集合中的点数
int h[N], e[M], ne[M], idx; // 邻接表存储所有边,匈牙利算法中只会用到从第一个集合指向第二个集合的边,所以这里只用存一个方向的边
int match[N]; // 存储第二个集合中的每个点当前匹配的第一个集合中的点是哪个
bool st[N]; // 表示第二个集合中的每个点是否已经被遍历过
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true;
if (match[j] == 0 || find(match[j]))//第二个集合的点未匹配,或者是可以为已经 匹配的第一个集合中的点找到别的集合二中的点
{
match[j] = x;
return true;
}
}
}
return false;
}
// 求最大匹配数,依次枚举第一个集合中的每个点能否匹配第二个集合中的点
int res = 0;
for (int i = 1; i <= n1; i ++ )
{
memset(st, false, sizeof st);
if (find(i)) res ++ ;
}
例题:P3386 【模板】二分图最大匹配 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
邻接表的写法(稠密图会超时)
#include <bits/stdc++.h>
using namespace std;
const int N = 505;
int n1,n2,ed;//需要两个集合
int h[N] , ne[N] , e[N] , idx;
int match[N] ;
bool vis[N];
void init(){
memset(h,-1,sizeof h);
idx = 0;
}
void add(int a, int b){
e[idx] = b ;
ne[idx] = h[a];
h[a] = idx++;
}
bool find(int x){
for (int i = h[x] ; i != -1 ; i =ne[i]){
int j = e[i];
if(!vis[j]){
vis[j] = true;
if(match[j] == 0 || find(match[j])){
//如果终边的点未匹配,或者是可以为以匹配的起点找到另一个终点
match[j] = x;
return true;
}
}
}
return false;
}
int main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n1 >> n2 >>ed;
init();
int u ,v;
for (int i = 1 ; i <= ed ; i++){
cin >> u >> v;
if(v <= n2){
add(u , v);
}
}
int ans = 0;
for (int i = 1 ; i <= n1 ; i++){
memset(vis, false ,sizeof vis);
if(find(i)) ans++;
}
cout << ans <<endl ;
return 0;
}
邻接矩阵的写法:
#include <bits/stdc++.h>
using namespace std;
const int N = 505;
int n1,n2,ed;//需要两个集合
bool a[N][N];
int match[N];
bool vis[N];
bool find(int x){
//枚举终边
for (int i = 1 ; i <= n2 ; i ++){
if(!vis[i] && a[x][i]){
vis[i] = true;
if(match[i] == 0 || find(match[i])){
//如果终边的点未匹配,或者是可以为以匹配的起点找到另一个终点
match[i] = x;
return true;
}
}
}
return false;
}
int main(){
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n1 >> n2 >>ed;
int u ,v;
for (int i = 1 ; i <= ed ; i++){
cin >> u >> v;
if(v <= n2){
a[u][v] = 1;
}
}
int ans = 0;
for (int i = 1 ; i <= n1 ; i++){
ans+=find(i); // 这里不一样哦
memset(vis, false ,sizeof vis);
}
cout << ans <<endl ;
return 0;
}
数学知识
[!NOTE]
当看见 0 的个数时考虑将结果分成 2 , 5 的个数,并且,末尾的0的个数一定是由5的个数决定的
E-Kevin喜欢零(困难版本)_牛客小白月赛73 (nowcoder.com)
#include <bits/stdc++.h>
void solve() {#include <bits/stdc++.h>
void solve() {
int n, k;
std::cin >> n >> k;
int64_t ans = 0;
std::unordered_map<int, std::vector<int>> tp, fp;
//tp 记录5的个数,fp记录2的个数
//两个是互补的
tp[0].push_back(0);
fp[0].push_back(0);
for (int i = 0, t = 0, f = 0; i < n; i++) {
int x;
std::cin >> x;
for (; x && x % 2 == 0; x /= 2, t++) {
}
for (; x && x % 5 == 0; x /= 5, f++) {
}
ans += std::max(
//需要 2^k * 5^k 即可满足 10^k 所以是动态规划
//每次计算出当前数据含有的2 和 5 的数量 和仍然需要 k - 当前数量 这一行的去更新
//因为同一个状态有可能对应多个数据, 所以只要找到第一个满足能凑出另一个2或者5的即可
//map不能使用upper_bound 但是 内部的vector 是可以使用的
std::upper_bound(tp[t - k].begin(), tp[t - k].end(), f - k) - tp[t - k].begin(),
std::upper_bound(fp[f - k].begin(), fp[f - k].end(), t - k) - fp[f - k].begin()
);
tp[t].push_back(f);
fp[f].push_back(t);
}
std::cout << ans << "\n";
}
int main() {
std::ios::sync_with_stdio(false);
std::cin.tie(nullptr);
int t;
std::cin >> t;
while (t--) {
solve();
}
return 0;
}
int n, k;
std::cin >> n >> k;
int64_t ans = 0;
std::unordered_map<int, std::vector<int>> tp, fp;
//tp 记录5的个数,fp记录2的个数
//两个是互补的
tp[0].push_back(0);
fp[0].push_back(0);
for (int i = 0, t = 0, f = 0; i < n; i++) {
int x;
std::cin >> x;
for (; x && x % 2 == 0; x /= 2, t++) {
}
for (; x && x % 5 == 0; x /= 5, f++) {
}
ans += std::max(
//需要 2^k * 5^k 即可满足 10^k 所以是动态规划
//每次计算出当前数据含有的2 和 5 的数量 和仍然需要 k - 当前数量 这一行的去更新
//因为同一个状态有可能对应多个数据, 所以只要找到第一个满足能凑出另一个2或者5的即可
std::upper_bound(tp[t - k].begin(), tp[t - k].end(), f - k) - tp[t - k].begin(),
std::upper_bound(fp[f - k].begin(), fp[f - k].end(), t - k) - fp[f - k].begin()
);
tp[t].push_back(f);
fp[f].push_back(t);
}
std::cout << ans << "\n";
}
int main() {
std::ios::sync_with_stdio(false);
std::cin.tie(nullptr);
int t;
std::cin >> t;
while (t--) {
solve();
}
return 0;
}
数论
质数
void divide(int x)
{
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
int s = 0;
while (x % i == 0) x /= i, s ++ ;
cout << i << ' ' << s << endl;
}
if (x > 1) cout << x << ' ' << 1 << endl;
cout << endl;
}
```
# 埃氏筛法: 枚举所有数据,然后把每个数的倍数筛去,留下的就是质数 **思想比较好** 思想太好了
``` cpp
void get_primes(int n){
for(int i=2;i<=n;i++){
if(st[i]) continue;
primes[cnt++]=i;
for(int j=i+i;j<=n;j+=i){
st[j]=true;
}
}
}
线性筛法: 如果质数,把这个数加入集合中 最常用
int primes[N], cnt;
bool st[N];
void get_primes(int n)
{
for (int i = 2; i <= n; i ++ )
{
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ )
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
约数
vector<int> get(int n){
vector<int> ans;
for(int i=1;i<=n/i;i++){
if(n%i==0){
ans.push_back(i);
if(i!=n/i) ans.push_back(n/i);
}
}
sort(ans.begin(),ans.end());
return ans;
}
- 约数个数,约数之和
如果 N = p1^c1 * p2^c2 * ... *pk^ck
约数个数: (c1 + 1) * (c2 + 1) * ... * (ck + 1)
约数之和: (p1^0 + p1^1 + ... + p1^c1) * ... * (pk^0 + pk^1 + ... + pk^ck
#include <bits/stdc++.h>
using namespace std;
typedef unsigned long long ULL;
const int mod = 1e9 + 7;
int main() {
int n ;
cin >> n;
unordered_map<int,int> primes;
while(n--) {
int x;
scanf ("%d", &x);
for (int i = 2 ; i <= x / i ; i ++ ) {
while(x % i == 0) {
primes[i] ++;
x /= i;
}
}
if (x > 1) primes[x]++;
}
ULL cnts = 1,res = 1;
for (auto [prime,cnt]:primes) {
cnts = (cnts * (cnt + 1)) % mod;
ULL t = 1;
while(cnt--){
t = (t *prime + 1) %mod;
}
res = res * t % mod;
}
cout << cnts << " " << res;
return 0;
}
欧几里得算法,辗转相除法,求最大公约数
- GCD(a,b) = =GCD(a.amodb)
int gcd(int a, int b)
{
return b ? gcd(b, a % b) : a;
}
```
- LCM 最小公倍数 将两个数相乘再除以最大公因数即可得到最小公倍数
```cpp
int lcm(int a,int b){
return a*b/gcd(a,b);
}
- 求ax+by=gcd(a,b)
int xGCD(int a, int b, int &x, int &y) {
if (!b) {
x = 1, y = 0;
return a;
}
int x1, y10, gcd = xGCD(b, a % b, x1, y1);
x = y1, y = x1 - (a / b) * y1;
return gcd;
}
```
### 欧拉函数:小于x的整数中与x互质的数的个数]
求出单个数的欧拉函数
f(n) = `n *(1 - 1 / p1) * (1 - 1 / p2a) ......`
```cpp
int phi(int x){
int res=x;
for(int i=2;i<=x/i;i++){
if(x%i==0){
res=res/i*(i-1);
while(x%i==0) x/=i;
}
}
if(x>1) res=res/x*(x-1);
return res;
}
筛法:求出1-n每个数的欧拉函数,在线性筛法的模板中加上三行
int primes[N], cnt;
int euler[N];
bool st[N];
void get_eulers(int n)
{
euler[1] = 1;
for (int i = 2; i <= n; i ++ )
{
if (!st[i])
{
primes[cnt ++ ] = i;
euler[i] = i - 1;
}
for (int j = 0; primes[j] <= n / i; j ++ )
{
int t = primes[j] * i;
st[t] = true;
if (i % primes[j] == 0)
{
euler[t] = euler[i] * primes[j];
break;
}
euler[t] = euler[i] * (primes[j] - 1);
}
}
}
欧拉定理
a ^f(n) % n = 1
a和n互质
快速幂:
把指数转为2进制就可以看出来有哪些含有了
预处理时每一个结果都是前一个的平方再mod
求 m^k mod p,时间复杂度 O(logk)。
int qmi(int m, int k, int p)
{
int res = 1 % p, t = m;
while (k)
{
if (k&1) res = res * t % p;
t = t * t % p;
k >>= 1;
}
return res;
}
```
### 快速幂求逆元
```cpp
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
int quick_mi(int a,int b,int p) {
int res = 1 % p;
while(b) {
if(b&1) res = (LL) res*a %p;
b >>= 1;
a = (LL) a * a % p;
}
return res;
}
int main() {
int n;
scanf ("%d", &n);
while(n--) {
int a,p;
scanf("%d%d",&a,&p);
if(a % p) printf("%d\n",quick_mi(a,p-2,p));
else puts("impossible");
}
}
扩展欧几里得算法(不会)
int exgcd(int a, int b, int &x, int &y)
{
if (!b)
{
x = 1; y = 0;
return a;
}
int d = exgcd(b, a % b, y, x);
y -= (a/b) * x;
return d;
}
```
#### 高斯消元求解方程组的解
```cpp
#include <bits/stdc++.h>
using namespace std;
const int N=100;
int n;
const double eps=1e-6;
double a[N][N];
int gauss()
{
int c, r;
for (c = 0, r = 0; c < n; c ++ )
{
int t = r;
for (int i = r; i < n; i ++ )
if (fabs(a[i][c]) > fabs(a[t][c]))
t = i;
if (fabs(a[t][c]) < eps) continue;
for (int i = c; i <= n; i ++ ) swap(a[t][i], a[r][i]);
for (int i = n; i >= c; i -- ) a[r][i] /= a[r][c];
for (int i = r + 1; i < n; i ++ )
if (fabs(a[i][c]) > eps)
for (int j = n; j >= c; j -- )
a[i][j] -= a[r][j] * a[i][c];
r ++ ;
}
if (r < n)
{
for (int i = r; i < n; i ++ )
if (fabs(a[i][n]) > eps)
return 2;
return 1;
}
for (int i = n - 1; i >= 0; i -- )
for (int j = i + 1; j < n; j ++ )
a[i][n] -= a[i][j] * a[j][n];
return 0;
}
int main(){
cin>>n;
for(int i=0;i<n;i++)
for(int j=0;j<n+1;j++){
cin>>a[i][j];
}
int t=gauss();
if(t==0){
for(int i=0;i<n;i++){
printf("%.2lf ",a[i][n]);
}
}
else if(t==2) cout<<"无解"<<endl;
else cout<<"有无数组解"<<endl;
return 0;
}
递推求组合数,dp法 适合询问次数>10w
for (int i = 0; i < N; i ++ )
for (int j = 0; j <= i; j ++ )
if (!j) c[i][j] = 1;
else c[i][j] = (c[i - 1][j] + c[i - 1][j - 1]) % mod;
通过预处理逆元的方式求组合数 询问1w
首先预处理出所有阶乘取模的余数fact[N],以及所有阶乘取模的逆元infact[N]
如果取模的数是质数,可以用费马小定理求逆元
int qmi(int a, int k, int p)
{
int res = 1;
while (k)
{
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
fact[0] = infact[0] = 1;
for (int i = 1; i < N; i ++ )
{
fact[i] = (LL)fact[i - 1] * i % mod;
infact[i] = (LL)infact[i - 1] * qmi(i, mod - 2, mod) % mod;
}
```
### Lucas定理求组合数 20次询问以下

{
int res = 1 % p;
while (k)
{
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
int C(int a, int b, int p)
{
if (a < b) return 0;
LL x = 1, y = 1;
for (int i = a, j = 1; j <= b; i --, j ++ )
{
x = (LL)x * i % p;
y = (LL) y * j % p;
}
return x * (LL)qmi(y, p - 2, p) % p;
}
int lucas(LL a, LL b, int p)
{
if (a < p && b < p) return C(a, b, p);
return (LL)C(a % p, b % p, p) * lucas(a / p, b / p, p) % p;
}

逆元:
可以在快速幂中求出
也就是a的p-2次方的
在模为素数p的情况下,有费马小定理 a^(p-1)=1(mod p) 那么a^(p-2)=a^-1(mod p) 也就是说a的逆元为a^(p-2)
分解质因数法求组合数
当我们需要求出组合数的真实值,而非对某个数的余数时,分解质因数的方式比较好用:
1. 筛法求出范围内的所有质数
2. 通过 C(a, b) = a! / b! / (a - b)! 这个公式求出每个质因子的次数。 n! 中p的次数是 n / p + n / p^2 + n / p^3 + ...
3. 用高精度乘法将所有质因子相乘
int primes[N], cnt;
int sum[N];
bool st[N];
void get_primes(int n)
• {
• for (int i = 2; i <= n; i ++ )
• {
• if (!st[i]) primes[cnt ++ ] = i;
• for (int j = 0; primes[j] <= n / i; j ++ )
• {
• st[primes[j] * i] = true;
• if (i % primes[j] == 0) break;
• }
• }
• }
•
• int get(int n, int p)
• {
• int res = 0;
• while (n)
• {
• res += n / p;
• n /= p;
• }
• return res;
• }
•
• vector<int> mul(vector<int> a, int b)
• {
• vector<int> c;
• int t = 0;
• for (int i = 0; i < a.size(); i ++ )
• {
• t += a[i] * b;
• c.push_back(t % 10);
• t /= 10;
• }
•
• while (t)
• {
• c.push_back(t % 10);
• t /= 10;
• }
•
• return c;
• }
•
get_primes(a);
for (int i = 0; i < cnt; i ++ )
{
int p = primes[i];
sum[i] = get(a, p) - get(b, p) - get(a - b, p);
}
vector<int> res;
res.push_back(1);
for (int i = 0; i < cnt; i ++ )
for (int j = 0; j < sum[i]; j ++ )
res = mul(res, primes[i]);
动态规划DP
思路:
状态表示:需要几维的动态规划
集合 所有选法
所有选法
条件
属性 最大值?最小值?……
状态计算:怎么得到结果
01背包 每个物品只能用一次
一维优化;
进行压缩,因为每次更新i是时只用到了i-1 这个位置的数据,所以可以使用滚动数组,实现每次i-1到i的更新;
所以编成 f[N] 表示j的背包容量下的最大值;
j=0的结果都为0 所以可以跳过;i=0的结果也都为0,同时,如果当前的背包容量不足以把当前物品装入也不需要进行更新了,所以小于当前背包容量的就不要考虑了;
不能更新也就是f[i][j]=f[i-1][j] 所以可以直接去掉,变为 f[j]=f[j]
for(int i=1;i<=n;i++){
for(int j=m;j>=v[i];j--)
f[j]=max(f[j],f[j-v[i]+w[i]]);
}
多状态dp
示例:
魔法背包
修路
魔法阵
存在多个状态,其中每一个状态内的转移是正常转移的,而状态之间是需要满足条件进行转移的。
完全背包 每件物品有无限个
01背包:从f[i-1]转过来 f[i,h]=max(f[i-1,j],f[i-1,j-v]+w[i]) //优化后:f[j]=max(f[j],f[v-v[i]]+w[i])
完全背包:从f[i]转移 f[i,j]=max(f[i-1,j],f[i,j-v[i]]+w[i])
每次更新:k是每个物品可以有多少个,i是前i个物品,j是当前背包容量
f[i][j]=max(f[i][j],f[i-j][j-v[i]*k]+w[i]*k
优化思路:

for (int i = 1; i <= n ; i++) {
for (int j = 1 ; j <= m ; j ++) {
f[i][j] = f[i-1][j];
if (j >= v[i]) f[i][j] = max(f[i][j],f[i][j - v[i]]+w[i]);
}
}
一维优化:删去一维
for(int i=1;i<=n;i++)
for(int j=v[i],j<=m;j++)
f[j]=max(f[j],f[j-v[i]]+w[i]);
01和完全背包区别:
背包容量的遍历不同
01:
for(int j=m;j>=v[i];j–)//m为最大背包容量
f[j]=max(f[j],f[j-v[i]+w[i]]);
完全:
for(int j=v[i],j<=m;j++)
f[j]=max(f[j],f[j-v[i]]+w[i]);
多重背包问题 优化
每个物品有个数限制,但不是无限
状态表示:f[ i ] [ j ]
状态计算:
f[i][j]=max(f[i-1][j-v[i]*k]+w[i]*k) k有范围
优化:将数量打包,比如打包成1个物品一起,2个物品一起……
之后用01背包做即可
#include <bits/stdc++.h>
using namespace std;
const int N = 1001;
int f[N],v[N],w[N];
int main(){
int n,m,cnt=0;
cin>>n>>m;
for(int i=1;i<=n;i++){
int a,b,s;
cin>>a>>b>>s;
int k=1;
while(k<=s){
cnt++;
v[cnt]=a*k;
w[cnt]=b*k;
s-=k;
k*=2;
}
if(s>0){
cnt++;
v[cnt]=a*s;
w[cnt]=b*s;
}
}
for(int i=1;i<=cnt;i++){
for(int j=m;j>=v[i];j--)
f[j]=max(f[j],f[j-v[i]]+w[i]);
}
return 0;
}
分组背包问题
线性DP
递归方程有线性关系,具有求的先后顺序
具体有各种子序列
建议看leetcode101 里面的比较好
数位统计DP
给出两个数字 a, b
统计a到b 中每一位 的0~9的出现次数
思路:分情况讨论 + 前缀和思想

include <iostream>
# include <cmath>
using namespace std;
int dgt(int n)
{
int res = 0;
while (n) ++ res, n /= 10;
return res;
}
int cnt(int n, int i)
{
int res = 0, d = dgt(n);
for (int j = 1; j <= d; j ++)
{
int p = pow(10, j - 1), l = n / p / 10, r = n % p, dj = n / p % 10;
if (i) res += l * p;
if (!i && l) res += (l - 1) * p;
if ( (dj > i) && (i || l) ) res += p;
if ( (dj == i) && (i || l) ) res += r + 1;
}
return res;
}
int main()
{
int a, b;
while (cin >> a >> b , a)
{
if (a > b) swap(a, b);
for (int i = 0; i <= 9; ++ i) cout << cnt(b, i) - cnt(a - 1, i) << ' ';
cout << endl;
}
return 0;
}
数位DP(重要)
DP时间复杂度:状态个数*转移个数
相当于往空里填数字
知识点1:mask集合
集合和数字的替换,使用二进制转化集合来实现某些数字不选择
例: 10011 从高到低依次代表者 4 3 2 1 0 这几个数字选不选,1表示选择,那么,
集合mask >> d & 1 d为这个数字,进行这样的运算就可以判断mask 对应的d数字这个位置上是1还是0
同理 mask|(1<<d) 将1移位到mask上 代表d这个数字的位置,进行或运算,即可将d加入集合中
模板:
将问题转化为填数字受限问题:
递归中的变量:
i 当前下标 当 i == 最大长度时,根据是否满足条件返回 0 或 1
mask 集合 代表着一种状态的记录,比如某位填了哪些数字,或者截止到上一位已经积累的某个要求满足条件的数据是多少,这个一般是变化的
is_limit 前一个位置是否收到原来的数字的限制:123 第一个填1 了后面一定受限,同时如果前面受限了,那么后面所有的都受限
is_num 前一个位置是否填数字,如果前一个没填数字,那么这一位无法填0了,如果填了可以填任意数字,当0对题目没影响时,可以不用这个东西
模板公式:
求出最大长度和memo,记忆数组,并初始化为-1 memo数组的一维是长度,二维是能包含所有枚举的最大长度,具体问题具体分析
递归函数
结束递归条件i == m 返回是否满足 满足为1 满足为0
记忆化剪枝:当is_limit 和 is_num 只有一个为真时,后面的数字也是可以任意填的,所以可以剪枝
!is_limit && is_num && memo[i][mask] != -1 return memo[i][mask]
设出res = 0 即为我们要求的答案
(可能不存在这种情况)这一位不填数字:res = (i+1 , mask不改变, false , false)
求出这一位数字可以填写的上下界:根据is_limit来求 up = is_limit ? s[i] - '0' : 9
枚举这一位数字,进行递归 (条件判断不一定需要)
for (int d = 初始 ; d <= up ; d++) if(当前这个数字没使用) 把这个数字加入mask
循环内:res = (i+1 , mask 的改变 , is_limit && d == up , is_num的变化)
当is_limit 和 is_num 只有一个为真时将答案加入memo中 if(!is_limit && is_num) memo[i][mask] = res
返回res
例题:
- 1012. 至少有 1 位重复的数字 - 力扣(Leetcode)
class Solution {
public:
int numDupDigitsAtMostN(int n) {
auto s =to_string(n);
int m = s.length(),memo[m][1 << 10];
memset(memo, -1 ,sizeof memo);
function<int(int,int,bool,bool)> f = [&] (int i ,int mask, bool is_limit , bool is_num) -> int {
if (i == m)
return is_num;
if (!is_limit && is_num &&memo[i][mask] != -1) return memo[i][mask];
int res = 0;
if (!is_num){
res = f(i + 1 , mask , false , false);
}
int up = is_limit ? s[i] - '0' : 9;
for (int d = 1 - is_num ; d <= up ; ++d)
if ((mask >> d & 1) == 0)
res += f(i + 1, mask | (1 << d), is_limit && d == up, true);
if (!is_limit && is_num)
memo[i][mask] = res;
return res;
};
return n - f(0 , 0 , true , false);
}
};
2. [6396. 统计整数数目 - 力扣(Leetcode)](https:
class Solution {
public:
const int mod = 1e9 + 7;
int cmp(string s , int min_sum , int max_sum){
int n = s.length() , memo[n][min(9*n,max_sum) + 1];
memset(memo , -1 , sizeof memo);
function <int(int ,int ,bool)> f = [&] (int i , int sum , bool is_limit) -> int {
if (sum > max_sum) return 0;
if (i == n) return sum >= min_sum;
if (!is_limit && memo[i][sum] != -1) return memo[i][sum];
int res = 0 ;
int up = is_limit ? s[i] - '0' : 9;
for (int d = 0 ; d <= up ; d++){
res = (res + f(i + 1 , sum + d , is_limit && d == up)) % mod;
}
if (!is_limit) memo[i][sum] = res ;
return res ;
};
return f(0 , 0 ,true);
}
int count(string num1, string num2, int min_sum, int max_sum) {
int ans = cmp(num2 , min_sum ,max_sum) - cmp(num1 , min_sum ,max_sum);
int sum = 0;
for (auto c : num1) sum += c - '0';
ans += min_sum <= sum && sum <= max_sum ;
return ans % mod;
}
};
状压DP 状态压缩+动态规划 利用二进制把状态记录成二进制数
291 91
树形DP 各层选择取最大值
将状态分为当前节点选择和不选择
285. 没有上司的舞会 - AcWing题库
#include <bits/stdc++.h>
using namespace std;
const int N = 6010;
int happy[N];
int n;
int e[N] , ne[N] , idx ,h[N] , dp[N][N];
bool fa[N];
void init(){
idx = 1;
memset(h, -1 , sizeof h);
}
void add(int a, int b){
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
void dfs(int u){
dp[u][1] = happy[u];
for(int i = h[u] ; i != -1 ; i = ne[i]){
int j = e[i];
dfs(j);
dp[u][0] += max(dp[j][0] , dp[j][1]);
dp[u][1] += dp[j][0];
}
}
int main(){
scanf("%d" ,&n);
for(int i = 1 ; i <= n ; i++){
scanf("%d",&happy[i]);
}
init();
for(int i = 0 ; i < n-1 ; i++){
int a , b ;
scanf("%d%d",&a,&b);
fa[a] =true;
add(b,a);
}
int root = 1;
while(fa[root]) root++;
dfs(root);
printf("%d",max(dp[root][0],dp[root][1]));
return 0;
}
状态机:
通过表示出状态的转换方式即可自动得到答案
DP行/列问题
6456. 矩阵中严格递增的单元格数 - 力扣(Leetcode)
例题:股票买卖问题
含有冷却时间需要用四个状态,正常两个即可,具体问题具体分析
714. 买卖股票的最佳时机含手续费 - 力扣(Leetcode)
309. 最佳买卖股票时机含冷冻期 - 力扣(Leetcode)
通过stoi 和隔板法实现枚举每一个数字的任意子子串
stoi substr to_string 的妙用
6441. 求一个整数的惩罚数 - 力扣(LeetCode)
子列和/字串问题:
求任意子列的乘积最大 6393. 一个小组的最大实力值 - 力扣(Leetcode)
一个字符串匹配另一个字典求最大匹配长度问题:6394. 字符串中的额外字符 - 力扣(Leetcode)
反转01得到相等字符串问题:6455. 使所有字符相等的最小成本 - 力扣(Leetcode)
暴力枚举法
使用于组合的数量少,但是需要找到最合适的组合的题目
例题
3*3