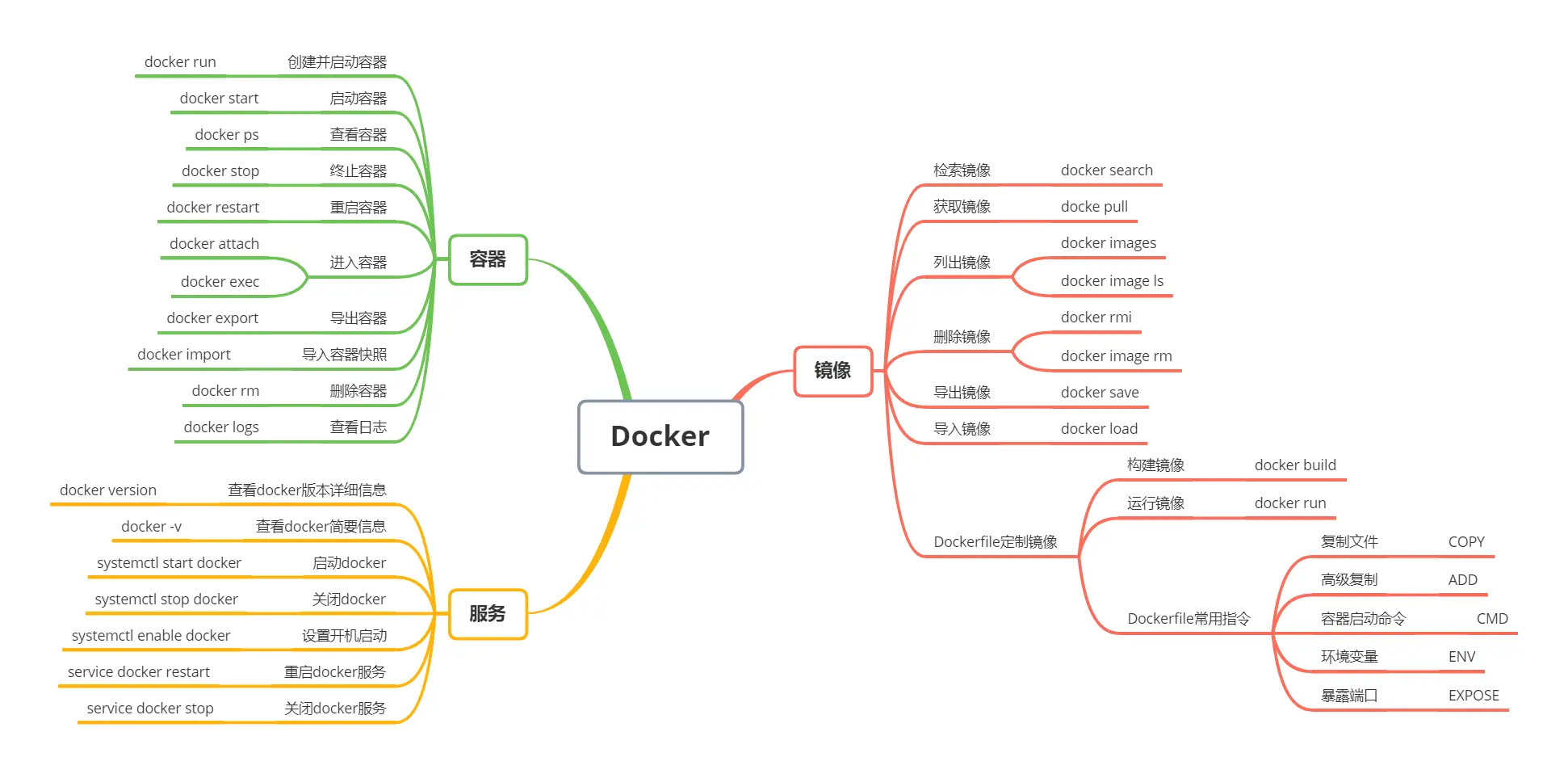
数据库
数据库同步问题:
Mysql面试指南
60 道 MySQL 精选面试题👍 | 二哥的Java进阶之路 (javabetter.cn)
InnoDB为什么是默认的引擎
- 是mysql中唯一支持事务的引擎
- 锁机制:使用行级锁,而不是表级锁
- 支持外键约束
- 具有崩溃恢复
索引为什么使用B+树
- 支出快速查找:B+树高度相对较低,查找效率高
- 有序性:节点的键值是有序排列的
- 支持高效插入和删除操作:叶子节点之间使用双向链表链接,可以快读定位到要插入和删除的位置
- 适应硬盘存储:B+树节点被控制在硬盘大小的范围内
- 支持数据点有序存储和范围查找
如何进行回滚的
- 使用Undo Log进行回滚,
- 混滚时,按照事务的执行的逆序进行回滚。
- Undo Log记录了事务对数据库的修改操作
慢查询如何考虑优化

数据库中的CAP
C:Consistency强一致性,系统在执行某项操作之后,仍然能够保持一致。更新操作执行成功,所有的用户都应该读到最新的值
A:Availabliy可用性,每个操作总是能够在一定时间内返回结果。结果可以是成功或者失败
P:分区容错性,出现网络分区时,系统能够正常运行。
怎么对plan进行优化
- 谓词下推:查询时,竟遭过滤掉不需要的数据
SELECT * FROM orders WHERE order_date > '2023-01-01'; - 索引下推:使用索引来加速查询,尤其是在索引覆盖查询中
- 表达式优化:简化和重写表达式来提高效率
- 最左匹配优化选择索引:使用索引的最左前缀原则来优化查询
- 避免SELECT *
- 使用适当的JOIN类型
- 使用索引覆盖:创建包含所有查询列的索引避免回表
介绍一下MySQL的索引
MySQL的索引是一种数据结构,可以帮助MySQL快速搞笑的查询,更新数据库中的数据。
B+树的特征,为什么 MySQL 要使用 B+树
特点:
- 只有叶子节点会存放实际的数据,包括索引+记录,非叶子节只存放索引
- 所有索引都在叶子节点中出现,叶子节点之间构成一个有序链表
- 非叶子节点的索引也会同时存在叶子节点中,并且是叶子节点中索引中的最大值或者最小值
- 非叶子节点有多少个子节点,就有多少个索引
看看几个隔离级别和解决办法
GBKh和UTF-8不是一种编码方式
mysql中使用的utf-8是utf8mb3 使用13个字节来表示一个字符4
而utf-8使用1
MVCC (Multi-Version Concurrency Control ,多版本并发控制)MVCC (Multi-Version Concurrency Control ,多版本并发控制)指的就是在使用 READ COMMITTD 、 REPEATABLE READ 这两种隔离级别的事务在执行普通的 SEELCT 操作时访问记录的版本链的过程,这样子可以使不同事务的 读-写 、 写-读 操作并发执行,从而提升系统性能。
- sql语句的执行过程:mysql8.0 client发送sql语句->sql解析->执行优化和执行计划生成->执行->返回结果
- 隔离等级:

- MySQL默认是可重复读,可以解决幻读。然后串行化是基于锁实现的,可重复读和读已提交都是基于MVCC实现的,可重复读在当前读的情况下需要加锁才能保证不会出现幻读,所以仅仅使用MVCC不能解决幻读
- 日志:
- 种类:错误日志,查询日志,慢查询日志,Binary Log, 中继日志,事务日志
- undo log 有两种
- insert undo log 执行insert 操作产生的undo log isnert只对事务本身可见,其他事务不可见,所以事务提交之后可以直接删除
- update undo log 提供MVCC机制,提交时放入undo log 链表,等待purge线程进行最后的删除
- purge:会定期检查 undo log 和数据行,找出那些已经不再需要的,然后将它们从磁盘上删除,从而回收磁盘空间。
- 慢查询日志:记录执行时间查过指定阈值的所有SQL查询,
- Binlog: 主要记录了数据库的修改操作,事务信息和一些特殊事件:服务器的启动和停止,主从复制状态变更事件等
- redo log 如何保证事务的持久性?
- 事务执行时,首先记录在redo log而不是直接修改数据文件,redo log 保存在内存中的log buffer,然后被异步刷新到磁盘中的redo log file中
- 事务提交时,相关的数据还没有没刷新到磁盘中,只要保证redo log 被刷新到磁盘中,即使系统在事务提交后崩溃了,也可以在系统重启之后通过redo log 里恢复数据,
- 为什么要先写入redo log ,因为redo log 时顺序写入的,而写数据需要涉及随机I/O,能够提高数据库的性能
- 页表修改之后为什么不直接刷盘?因为刷新到磁盘中非常耗时,所以使用预写式日志的技术,先写入redolog,之后异步刷新内存中的redolog到磁盘中,之后写入数据到内存中的数据页中,之后写入binlog,内存中的数据页会在适当实际刷新到磁盘中。
- binlog和redolog的区别:
- 用途上:binlog用于主从复制和数据恢复,复制时会把主服务器上的binlog发给从服务器,然后从服务器根据binlog中的记录来更新;而redo log 用于保证事务的持久性
- 格式:binlog:可以是语句格式或者行格式,语句记录SQL执行的语句,行格式记录每一行的数据变化。redo log以物理格式记录数据页的修改,记录的是某个数据页的某个位置,将某个数据修改为了什么
- 写入时机:binlog 事务提交时,redo log 事务执行过程中就开始写入,事务提交时确保已经将redo log 写入磁盘中
- 清理方式:binlog 需手动清理或者设置过期时间清理; redo log 当数据页的修改刷新到磁盘中之后,redo log 即可被覆盖重新使用
- undo log 如何保证事务的原子性:事务开始执行时,udno log 中会记录修改前的数据,如果事务体骄傲成功,undo log 即可以被清理,如果失败就会使用undo log 回滚事务。
- MVCC(乐观锁)如何实现:每个数据行中都有两个隐藏列:一个用于记录改行创建时的事务ID,一个记录删除该行的事务ID,当事务开始时,他会根据当前所有活跃的事务产生Read View ,其中记录了:
- 创建这个Read View时下个即将被分配的事务ID m_low_limit_id
- 活跃列表中最小的事务ID m_up_limit_id
- Read View创建时,其他未提交的活跃事务ID列表 m_ids
- 创建该Read View 的事务ID m_creator_trx_id
之后对数据行进行读取时,检查该行的创建事务ID和删除事务ID
- 如果创建ID大于m_low_limit_id,说明是在当前事务之后创建的,不可见
- 如果删除ID小于m_up_limit_id,说明在当前事务开始前就已经被删除了,不可见
- 如果创建事务ID小于m_low_limit_id但删除ID大于m_up_limit_id,需要与m_ids列表中比对,如果存在于m_ids列表中,则不可见
- 外键:
- 不建议使用外键,外键应该在应用层中保证,而不是在数据库上使用外键,因为外键对分库分表无法生效,同时需要维护外键,当我们做一些涉及外键的CUD操作时,需要触发相关的操作去检查,保证数据的一致性和正确性,从而消耗额外资源,
- 集群:
- redo log 和 undo log都是由InnoDB引擎实现的
- bin log 是由mysql级别的日志
- redo和bin 的区别:Redo log是记录了数据的修改,大小到一定程度,新的日志会覆盖,先写redo再写bin,目的是为了保证事务的持久性
- Binlog是记录了执行了什么sql语句,不会覆盖旧日志,用于实现mysql的主从复制
- redolog的优势:顺序写,预写入,磁盘同步过程中可以一次同步多个事务的Redo log:先把修改写入redolog,再修改内存中的数据,事务提交时再入bin log,之后再将数据写入磁盘中
- 主从复制:
- master节点会不断将sql命令写入Binary Log,子节点使用I/O线程读入master节点中的Bin Log
- 字节点使用SQL线程执行Bin Log的语句
- 存储引擎的区别:MyISAM 和 InnoDB 的区别
- MySQL的存储引擎采用的是插件式架构,支持多种存储引擎,我们甚至可以为不同的数据库表设计不同的存储引擎,存储引擎是基于表而不是数据库的。
- InnodDB支持事务
- InnoDB支持行级锁定,MyISAM操作时直接锁定整个表
- InnoDB支持外键和级联删除/更新
- InnoBD存储数据更大
- 崩溃恢复更好
- InnoDB以聚簇的方式存储数据,MyISAM是将数据和索引分开存储
- InnoDB支持MVCC
- 事务:
- 并发事务带来了哪些问题:
- 脏读:一个事务读到了另一个事务修改后回滚的数据
- 丢失修改:两个事务同时修改一个数据,先提交的会丢失修改
- 不可重复读:执行相同的两个语句,结果不一样
- 幻读:多了记录或者是少了记录
- 3和4的区别:3是记录被修改,4是记录条数变化
- mysql中的隔离等级: 默认是可重复读,能够防止幻读 实现是通过 锁和MVCC(多版本控制并发控制) 实现的
- 读未提交:允许事务读取未提交的事务的修改,会出现脏读,幻读,不可重复读
- 读已提交:只能读到提交的事务的修改,避免脏读,但是还有幻读 (读数据时加上共享锁,读取后立刻释放)
- 可重复读:同一事务中,多次读取统一数据返回结果要一致 (事务结束才释放锁,同时使用MVCC来保证每个事务都看到一个一致的快照)
- 可串行化:强制事务串行执行,影响效率
- MVCC的原理:
- 这两个隐藏的列就是undo log日志

- 这俩就是隐藏列,trx_id当前修改之后的事务id,roll_pointer指向修改之前的信息

- MVCC实现原理:ReadView
- 主要内容:
- m_ids:生成ReadView时当前系统活跃的读写事务id列表
- min_trx_id:在生成ReadView时当前系统活跃的读写事务中最小的事务id,也就是min (m_ids)
- max_trx_id:表示生成ReadVeiw时系统应该分配给下下一个事务的id值
- creator_trx_id:表示生成该ReadView的事务id
- 原理:在访问某条记录时根据以下方式来判断:
- trx_id == creator_trx_id,表示是自己修改过的记录,可见
- trx_id < min_trx_id 可以被访问
- trx_id > max_trx_id,不可被访问
- trx_id > min && trx_id < max 需要判断:如果trx_id在m_ids中,表示仍然活跃,不可访问,不在表示已经被提交,可以访问了
- 如果某个版本对当前事务不可见,则顺着版本连找下一个版本的数据,直到最后,如果最后一个版本也不可见的话,意味着这条记录对这个事务完全不可见,查询结果不返回这个记录
- 读已提交每次读都会生成一个ReadView,而可重复读智慧在第一次执行查询语句时生成一个ReadView
- 主要内容:
- 并发事务带来了哪些问题:
- 索引常问:
- 覆盖索引:查询使用了索引,并且查询过程中已经找到了所有需要的列,不需要继续回表了
- 索引失效问题:
- 使用了!= < > LIKE ,函数操作或者表达式操作
- 联合索引中没有遵循最左前缀,跳过了中间的索引字段
- SQL语句:
- 常见函数:
- Concat()把多列拼接在一起
- RTrim() 去除多有空格
- AS给列起别名
- 存储过程:存储过程是一种在数据库中存储的预编译的SQL语句集合,可以通过调用它的名字来执行。存储过程可以接收参数,并且可以返回值,长哟个与进行批处理
USE test; CREATE PROCEDURE productpricing() BEGIN SELECT * FROM hello; END; 调用 CALL productpricing()
- 常见函数:
InooDB详解
- InooDB大小一般为16kb
- InooDB页表:

- File Header:

- Page Header:

- infimumu+supremum 最小记录和最大记录。不存放真是数据

- heap_no分别为0和1, record_type分为4种,0普通记录,1表示B+树非叶节点记录,2最小记录,3最大记录。
- next_record 由当前真实数据指向吓一跳记录的真实数据。吓一跳记录不是按照插入顺序的下一条,而是根据主键排序之后的下一条。infimum的下一条记录是用户记录中主键最小的,用户记录中主键最大的下一条指向supremum
- 为什么指向的是真是数据的开头?
- 因为向左读取为记录头信息,向右读取真实数据。 记录头信息刚好是逆序的!

- User Record :
- 由额外记录信息和实际信息组成
- 额外记录:
- 变长字段的真实数据的字节长度都放在记录的开头,逆序存放。不存放NULL的字节长度
- NULLL值列表,NULL值存储在这里,并且是逆序存储,如果存在NULL值就不会存在这个列表
- 记录头信息:

- delete_mask标记的记录不会理科删除,而是会放在垃圾列表中,等待覆盖。
- heap_no是根据主键的大小来确定的
- 真实信息:

- 如果未指定主键,会生成row_id隐藏列
- Page Directory :
- 将正常的所有记录划分为几个组,包括最大和最小记录,不包括已删除的记录,最小记录所在的分组只包括自己。
- 每组最后一个记录的头信息中的n_ownd来表示该组中记录数。
- 将每组的最后一条记录的地址偏移量拿出来放入PageDirectory中,偏移量被称为槽(slot)

- File Trailer: 用于检验一个页是否完整:
索引:
回表问题
当查询的数据在索引树中找不到时,就需要回到主键索引树种去获取。
覆盖索引:
查询时从索引列就能够获取了,就不需要回到主键树中查找了
- 前提
- 数据页链表中的前后保证前一个数据页中的主键的最大值大于后一个页表中主键的最小值,也就主键递增,每一个页表内,主键也递增
- 建立一个目录项:包括 key:页中主键最小值 page_no:页号。

- mysql中的实现:
- 使用用户记录的数据页来存储目录项,并且使用record_type = 1来标明,只包含key和page_no即可
- 使用双向列表来维护多个目录项
- 使用树的结构来重复建立索引,加快访问


- 真正的数据页都放在最底层的叶子节点
- 聚簇索引:1. 使用主键值大小进行记录和排序 2. 叶子节点是完整的用户记录。索引即数据,数据即索引
- 二级索引:1.使用非主键值来进行记录和排序 2. 叶子节点存储的是索引键和主键的值 3. 查询到叶子节点之后需要再查找一变主键的索引来找到真正的用户记录。 优点是节省空间。

- 联合索引:1.使用多个列的大小来进行排序。先按照一个列排序,列大小相同时,使用下一个列大小来排序。2. 对于这多个列只需要建立一个B+树即可,节省了空间3.实质上也是二级索引
- 对比:MyISAM
- 存储在一个文件中,按照插入顺序,有行号
- 索引放在另一个文件中,使用主键值+行号作为索引,所以全是二级索引,而且不能二分查找。
- SQL建立索引:每一个表会自动为主键或者unique建立一个聚簇索引,可使用语句指定建立其他列的索引

- 删除索引:ALTER TABLE index_demo DROP INDEX idx_c2_c3;
- 独立表空间:
- 区:表空间分为多个区,区包含多个页
指令执行过程
- select
- 使用连接器连接mysql server,期间通过三次握手 show processlist来查看多少个客户端连接了
- 查询缓存(8.0) 已抛弃
- 解析SQL :
- 词法分析,根据字符串识别关键词,分类字符串
- 语法分析,语法解析器会根据语法规则来判断是否符合MySQL语法秒如果没问题就会构出SQL语法树
- 执行SQL语句,
SELECT查询语句流程主要可以分为下面这三个阶段:- prepare 阶段,也就是预处理阶段;检查表和字段是否存在,将* 扩展为表上的列
- optimize 阶段,也就是优化阶段;优化器主要负责将 SQL 查询语句的执行方案确定下来,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。
- execute 阶段,也就是执行阶段;根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
- MySQL一行记录如何
- 每建立一个数据库都会咋/var.lib/mysql/下建立一个同名的文件夹
- 文件夹中有三个文件
- db.opt 用来存储数据库的默认字符集和字符检验规则
- tableNaem.frm 对应的表结构会保存在这个文件,主要包含表结构的定义
- tableName.ibd 表中的数据会保存在这个文件中
- 表空间文件的结构 :

- 段
- 索引段:存放 B + 树的非叶子节点的区的集合;
- 数据段:存放 B + 树的叶子节点的区的集合;
- 回滚段:存放的是回滚数据的区的集合,之前讲事务隔离 (opens new window)的时候就介绍到了 MVCC 利用了回滚段实现了多版本查询数据。
- 区 InnoDB 使用的是B+树 以页为单位来来分配空间时,链表中相邻的两个页的物理位置是不连续的,为了防止随机I/O,可以按照区来分配,一个区可以包含多个页,这样页在位置上就是相邻的了可以使用顺序I/O
- 页 读取数据以页为单位,当读取一行时,会将一页一同读取出来,放入内存中 默认页 16kb ,页是 InnoDB 存储引擎磁盘管理的最小单元,
- 行 记录按照行
- 行格式:COMPACT

- 变长字段长度列表,用于保存数据占用的大小, 在列表中采用逆序存放数据占用的实际字节,当一行中没有变长字段时,例如全int时,就不会存在变长字段列表了。
- NULL列表,数据中为NULL 的数据会放在NULL值列表中的。NULL值也是按照逆序存储的,使用二进制 0 1 来表示是否为NULL值,1 为是 当数据表的字段都定义成 NOT NULL 的时候,这时候表里的行格式就不会有 NULL 值列表了。
- 记录头信息
- delete_mask :标识此条数据是否被删除。从这里可以知道,我们执行 detele 删除记录的时候,并不会真正的删除记录,只是将这个记录的 delete_mask 标记为 1。
- next_record:下一条记录的位置。从这里可以知道,记录与记录之间是通过链表组织的。在前面我也提到了,指向的是下一条记录的「记录头信息」和「真实数据」之间的位置,这样的好处是向左读就是记录头信息,向右读就是真实数据,比较方便。
- record_type:表示当前记录的类型,0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录
- 真实数据部分
- row_id 未指定主键或者唯一约束列时,会有,占用6个字节
- trx_id事务id表示数据由哪个事务生成的,必需
- roll_pointer 记录上一个版本的指针,必需
- 行格式:COMPACT
- 一行数据的最大字节数 65535(不包含 TEXT、BLOBs 这种大对象类型),其实是包含「变长字段长度列表」和 「NULL 值列表」所占用的字节数的
- 如果一个数据页存不了一条记录,InnoDB 存储引擎会自动将溢出的数据存放到「溢出页」中。
Compact 行格式针对行溢出的处理是这样的:当发生行溢出时,在记录的真实数据处只会保存该列的一部分数据,而把剩余的数据放在「溢出页」中,然后真实数据处用 20 字节存储指向溢出页的地址,从而可以找到剩余数据所在的页。
Compressed 和 Dynamic 这两种格式采用完全的行溢出方式,记录的真实数据处不会存储该列的一部分数据,只存储 20 个字节的指针来指向溢出页。而实际的数据都存储在溢出页中。
索引分类:
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
MySql查询优化
- 单表
- 根据搜索条件,找出所有可能使用的索引
- 计算全表扫描的代价
- 计算使用不同索引执行查询的代价
- 对比各种执行方案的代价,找出成本最低的那一个
- 多表连接:
- 单次查询驱动表的成本
- 多次查询被驱动表的成本(具体查询多少次取决于对驱动表查询的结果集中有多少条记录)
- 连接查询成本占大头的其实是 驱动表扇出数 x 单次访问被驱动表的成本 ,所以我们的优化
- 重点其实是下边这两个部分:
- 尽量减少驱动表的扇出
- 对被驱动表的访问成本尽量低
Buffer Pool 缓冲池
脏页:缓冲池中的数据已经修改但是没有同步到磁盘中
基本概念
模式
- 模式: 逻辑模式,是开发者可见的模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
- 外模式:子模式,用户模式,用户可见
- 内模式: 存储模式,是物理存储模式
schema 和 database 区别
database 是一栋楼,schema(模式) 是一个个房间,但是在mysql中两种没有区别。
- 视图和表的区别:视图是表的子集,常用于将查询结果保存在视图中,方便再次调用
- 语法:’CREATE VIEW viewName AS 查询出来的表’
范式
- 1NF 保证原子性即可,不可再分割了
- 2NF 要有主键,且不存在部份依赖,也就是其他非主键的部分要治理来于主键即可
- 3NF 非主键之间不存在传递依赖,例如 学号, 姓名, 年龄, 学院名称, 学院电话,满足第二范式,因为后面几个属性都要和主键相关联,不能独立存在,但是通过 学号 -> 学生 -> 所在院 -> 院电话 ,所以存在传递依赖应修改为:学生:(学号, 姓名, 年龄, 所在学院);学院:(学院,学院名称, 电话)。
- BCNF 消除几个主键之间的传递依赖
ACID
Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
E-R模型
E-R模型是Entity-Relationship模型的缩写,是一种用于数据库设计的概念性数据模型。它用来描述现实世界中的数据之间的关系,以及这些数据的属性。E-R模型提供了一种图形化的方式来表示数据模型,使数据库设计师能够更容易地理解和规划数据库结构。
E-R模型包括以下几个核心概念:
实体(Entity):实体是现实世界中可以被识别的独立对象,例如人、物品、地点或概念。每个实体都有一些属性,用来描述这个实体的特征。
属性(Attribute):属性是描述实体的特征或属性,它们用来存储有关实体的信息。例如,对于一个”人”实体,属性可以包括姓名、年龄、性别等。
关系(Relationship):关系表示不同实体之间的联系或连接。关系可以是一对一、一对多或多对多的。例如,一个”雇员”实体可以与一个”部门”实体之间有一个”属于”关系,表示雇员属于某个部门。
主键(Primary Key):主键是一个属性或属性组合,用来唯一标识实体集中的每个实体。它确保了每个实体都具有唯一的标识。
外键(Foreign Key):外键是一个实体中的属性,它引用了另一个实体的主键,用于建立实体之间的关联。
通过使用E-R模型,数据库设计师可以更好地理解数据之间的关系,从而规划数据库的结构,包括表的设计、关系的建立和数据的存储。一旦E-R模型完成,它可以用作设计数据库架构的基础,进而创建物理数据库模式(如关系模型),以实际存储和管理数据。这有助于确保数据库能够有效地存储和检索信息,并满足应用程序的需求。
自联结,变量不会,补一补去
打开
mysql -u root -p数据类型
关系型数据库:建立在关系模型基础上,由多张相互链接的二维表组成的数据库
SQL语句
数值类型
TINYINT 1byte -128 - 127 0 - 255 /*后面加上unsigned 即可指定为无符号*/ SMALLINT 2 MEDIUMINT 3 INT 4 BIGINT 8 FLOAT 4 DOUBLE 8 DECIMAL 看精度和标度 125.25 精度为5 标度为2字符串类型
CHAR() 定长字符串 VARCHAR 根据内容计算字符串长度 TINYTEXT 短文本字符串日期类
DATE YYYY-MM-DD TIME HH:MM:SS YEAR YYYY DATETIME YYYY-MM-DD HH:MM:SS TIMESTAMP YYYY-MM-DD HH:MM:SS 时间戳常用函数
DATE_FORMAT()时间戳记或称为时间标记(英语:timestamp)是指字符串或编码信息用于辨识记录下来的时间日期。国际标准为ISO 8601。
时间戳记的范例如下:
- 2016-12-25T00:15:22Z
- 2005-10-30 10:45 UTC
- Sat Jul 23 02:16:57 2005
- 2016年12月25日 (日) 00:14 (UTC)
注释 # 或者 /**/
- DDL (Data Definition Language 数据定义语言)用于操作对象及对象本身,这种对象包括数据库,表对象,及视图对象,表头 ^c501f6
- DML (Data Manipulation Language 数据操控语言) 用于操作数据库对象对象中包含的数据
- DQL (Data Query Language 数据查询语言 )用于查询数据
- DCL (Data Control Language 数据控制语句) 用于操作数据库对象的权限
DDL (Data Definition Language 数据定义语言)用于操作对象及对象本身,这种对象包括数据库,表对象,及视图对象,表头
SHOW DATABASES 查询所有的数据库
SELECT DATABASE(); 查询当前所处数据库
CREATE DATABASE 创建
DROP DATABASE XXX 删除
USE xxx 使用数据库
SHOW TABLES 查询当前数据库的所有表
DESC 表名 查询表结构
SHOW CREATE TABLE 表明 查询指定表的建表语句
字段1 字段1类型 COMMENT 'XXX',/*注释*/
........
) COMMENTT 'XXX'/*注释可以省略*/
/*字符串类型是varchar(指定的字符长度)*/
/*修改表*/
ALTER TABLE tablename
1.ADD字段名 类型 comment xxx 添加表头
2.CHANGE 旧 新 类型 comment xxx 修改
3.DROP name
4.RENAME TO name 修改表名
DROP TABLE name 删除
TRUNCATE TABLE name 删除并重新创建同名表,数据依旧会删除DML (Data Manipulation Language 数据操控语言) 用于操作数据库对象对象中包含的数据
/*添加数据*/
INSERT INTO 表名(字段名) VALUES (数值) 给指定字段添加数据
INSERT INTO 表名 VALUES (数值) 给所有字段加上数据
INSERT INTO 表明(字段名) VALUES (数据) ,(数据)
INSERT INTO 表明 VALUE (数据),(数据)...
/*修改*/
UPDATE 表名 SET 字段名=值, .... WHERE 条件
DELETE 表名 (WHERE 条件) /*删除*/插入
语句:INSERT
前提:获得权限
用法:
插入完整的行;
插入行的一部分;
插入某些查询的结果。
语法:
INSERT INTO Customers
VALUES('1000000006',
'Toy Land',
'123 Any Street',
'New York',
'NY',
'11111',
'USA',
NULL,
NULL);更加安全的操作,将要插入的列也列出
INSERT INTO Customers(cust_id,
cust_name,
cust_address,
cust_city,
cust_state,
cust_zip,
cust_country,
cust_contact,
cust_email)
VALUES('1000000006',
'Toy Land',
'123 Any Street',
'New York',
'NY',
'11111',
'USA',
NULL,
NULL);插入列的一部分,语法和上面一样,只是不需要插入的列可以省略不写,列名不写,对应的数据也不写
插入检索出的数据
语法:
SELECT cust_id, cust_contact, cust_email, cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country FROM CustNew;它使用的是列的位置,因此 SELECT 中的第一列(不管
其列名)将用来填充表列中指定的第一列,第二列将用来填充表列中
指定的第二列,如此等等
INSERT SELECT 中 SELECT 语句可以包含 WHERE 子句,以过滤插入的数据。
INSERT 通常只插入一行。要插入多行,必须执行多个 INSERT 语句。
INSERT SELECT是个例外,它可以用一条INSERT插入多行,不管SELECT
语句返回多少行,都
从一个表复制到另一个表
CREATE TABLE CustCopy AS SELECT * FROM Customers;SELECT INTO 是试验新 SQL 语句前进行表复制的很好工具。先进行复
制,可在复制的数据上测试 SQL 代码,而不会影响实际的数据。
更新与删除
更新:UPDATE 注意要用WHERE 否则会出事
更新特定行
语法:
要更新的表;
列名和它们的新值;
确定要更新哪些行的过滤条件。
UPDATE Customers SET cust_email = 'kim@thetoystore.com' WHERE cust_id = '1000000005';UPDATE 语句以 WHERE 子句结束,它告诉 DBMS 更新哪一行。没有 WHERE
子句,DBMS 将会用这个电子邮件地址更新 Customers 表中的所有行,
这不是我们希望的。
更新特定列
UPDATE Customers SET cust_contact = 'Sam Roberts', cust_email = 'sam@toyland.com' WHERE cust_id = '1000000006';在更新多个列时,只需要使用一条 SET 命令,每个“列=值”对之间用
UPDATE 语句中可以使用子查询,使得能用 SELECT 语句检索出的数据
更新列数据
要删除某个列的值,可设置它为 NULL(假如表定义允许 NULL 值)
删除数据
DELETE 注意WHERE 缺少是会出事的
从表中删除特定的行
从表中删除所有行。
删除特定行
DELETE FROM Customers WHERE cust_id = '1000000006';DELETE 语句从表中删除行,甚至是删除表中所有行。但是,DELETE
不删除表本身
果想从表中删除所有行,不要使用 DELETE。可使用 TRUNCATE +TABLE +表名
语句,它完成相同的工作,而速度更快(因为不记录数据的变动)。
删除全部行
如果执行 DELETE 语句而不带 WHERE
子句,表的所有数据都将被删除
DQL (Data Query Language 数据查询语言 )用于查询数据
SELECT + 字段列表
FROM 表名列表
WHERE 条件列表
[[数据库#^aa4a30|GROUP BY 分组字段列表]]
HAVING 分组后条件列表
ORDER BY 排序
LIMIT 分页参数
[[数据库#^1cd456|AS 设置别名]]
WHRER 和 HAVING 的区别,WHERE 在分组之前起作用,HAVING在分组之后起作用
SELECT
SELECT 字段1,... FROM 表 或者 SELECT * FROM
SELECT DISTINCT 去重
SELECT 字段 AS 别名 ... FROM 设置字段的别名
条件
SELECT XXX FROM XXX WHERE +
> >= < <= = <>(不等于,相当于!=) BETWEEN ... AND ...
IN (...) 满足列表中的其一
LIKE 包含这个字符 模糊匹配
'%a' //以a结尾的数据
'a%' //以a开头的数据
'%a%' //含有a的数据
'_a_' //三位且中间字母是a的
'_a' //两位且结尾字母是a的
'a_' //两位且开头字母是a的
'___' //含有三个字符的
'[]' //类似正则表达式
'[^]' //不包含括号之内的单个字符聚合函数:将一列数据作为一个整体,进行纵向计算
SELECT +
count
max
min
avg 平均值
sum
+ 字段列表
+ FROM 表名分组查询 ^aa4a30
SELECT 字段名 FROM 表 WHERE GROUP BY 分组字段名 HAVING 分组之后的过滤条件排序查询
SELECT xx FROM 表名 ORDER BY 字段1 排序方式(ASC升序,DESC 降序)
,字段2 XXX 分页查询
SELECT xx FROM XXX LIMIT (起始索引,查询记录数)等于OFFSET n ROWS
FETCH NEXY M ROWS ONLY 跳过n行,并返回接下来的m行
DCL (Data Control Language 数据控制语句) 用于操作数据库对象的权限
SELECT * FORM user
CREATE USER '用户名'@'主机名' IDENTIFIED BY '/'/*使用%来指定任意主机都可以访问*/
ALTER USER '用户名' @ '主机名' IDENTIFIED WITH mysql_native_password BY '新密码' 修改密码
DROP USER '用户名' @ '主机名' 删除用户
/*权限控制*/
SHOW GRANT FOR '用户名'@'主机名'
GRANT 权限列表 ON 数据库名 表名 TO '用户名'@'主机名'
取消权限
REVOKE 权限列表 ON 数据库名 表名 FROM '用户名'@'主机名'函数 配合SELECT 使用
字符串函数
CONCAT (s1,s2...) 拼接
LOWER(str)
UPPER(str)
LPAD(str,n,pad) 左填充,用pad来填充原字符串,填充n次
RPAD 右填充
TRIM(str) 去掉首位的空格
SUBSTRING(str,start,len) 数值函数
CEIL() 向上取整
FLOOR() 向下取整
MOD(x,y) x % y
RAND() 0-1内的随机数
ROUND(x,y) 四舍五入保留y位小数日期函数
CURDATE() 返回当前日期
CURTIME()
NOW() 当前日期和时间
YEAR(date) 获取指定日期的年份
MONTH(date)
DAY(date)
DATE_ADD(date,interval expr type) 返回一个日期/时间加上时间间隔expr后的时间
DATEDIFF(date1,date2) 返回两个日期相差的天数
timestampdiff(间隔类型,前一个时间,后一个时间) 计算日期查
例如: timestampdiff(YEAR,hiredate,now()))流程函数
if (value,t,f) 如果value true 返回t 否则返回f
IFNULL(v1,v2) 如果v1不为空返回v1,否则返回v2
CASE WHEN (v1) THEN (res1)
WHEN (v2) THEN (res2)
....
ELSE default END
约束 作用域表中字段上的规则,用于限制存储在表中的数据
目的是未来保证数据库中数据的正确性和完整性有效性
分类
非空约束,字段不能为null 关键字: NOT NULL
唯一约束 字段不能重复 UNIQUE
主键约束 主键是一行数据的唯一表示,要求非空且唯一 PRIMARY KEY
默认约束 使用默认值 DEFAULT
检查约束 保证字段值满足某一个条件 CHECK
外键约束 来让两整表之间建立练习,保证数据的一致性 FOREIGN KEY
示例:
create table user
(
name varchar(10) not null unique comment '姓名不为空且不能重复',
age int check ( age > 0 && age <= 120) comment '年龄检查为0-120',
status char(1) default '1' comment '状态默认为1',
gender char(1) comment '性别'
) comment '用户表';
外键
1.建表时
CREATE TABLE (
....
....
CONSTRAINT 外键名称 FOREGIN KEY (外键字段名) REFERENCES 主表列名
)
2. ALTER TABLE 表 ADD CONSTRAINT 外键名(自定义) FOREIGN KEY (本表)字段名 REFERENCES 外表+(字段名)删除/更新
ALTER TABLE 表 ADD CONSTRAINT 外键名(自定义) FOREIGN KEY (本表)字段名 REFERENCES 外表+(字段名) ON UPDATE 更新时的操作 ON DELETE 删除时要执行的操作
操作有
NO ACTION 在父表中删除/更新时,首先检查,该记录是否有外键,如果有则不允许更新或者删除
RESTRICT 同 NO ACTION
CASCADE 可以删除/更新外键在子表中的记录
SET NULL 设置子表中的外键记录为NULL
SET DEFAULT 设置为一个默认值多表查询
多表关系:
一对多 多的一方建立外键指向一
多对多 建立第三张中间表,中间表至少包含两个外键,分别关联两方
一对一 任意一方加上外键并设置为UNIQUE
子查询:
查询嵌套,括号内的查询结果作为括号外的条件 例子:
SELECT cust_id
FROM Orders
WHERE order_num IN (SELECT order_num
FROM OrderItems
WHERE prod_id = 'RGAN01'); 或者
SELECT cust_name,
cust_state,
(SELECT COUNT(*)
FROM Orders
WHERE Orders.cust_id = Customers.cust_id) AS orders
FROM Customers
ORDER BY cust_name;标量子查询
子查询返回单个值
列子查询,返回结果是一列或者多行
常用操作符号
IN
NOT IN
ANY
SOME 和ANY相同
ALL 行子查询,返回一行或者是多列
= < > IN NOT IN 表子查询
返回多行多列
常用IN 来进行查询
联结表
- 内联结
比如
进行数据存储的时候,会指定一种联系方式
可以类比为散列表或者map
SELECT vend_name, prod_name, prod_price
FROM Vendors, Products
WHERE Vendors.vend_id = Products.vend_id;正式用法
SELECT vend_name, prod_name, prod_price
FROM Vendors INNER JOIN Products
ON Vendors.vend_id = Products.vend_id;on之后的式匹配规则,同时为了防止冲突,尽量用点来获取每个不同的库的数据
联结多个表
SELECT prod_name, vend_name, prod_price, quantity
FROM OrderItems, Products, Vendors
WHERE Products.vend_id = Vendors.vend_id
AND OrderItems.prod_id = Products.prod_id
AND order_num = 20007;2.自联结
联结中仍然可以使用内聚函数
例如
SELECT Customers.cust_id,
COUNT(Orders.order_num) AS num_ord
FROM Customers INNER JOIN Orders
ON Customers.cust_id = Orders.cust_id
GROUP BY Customers.cust_id;统一表内联结自己
SELECT c1.cust_id, c1.cust_name, c1.cust_contact
FROM Customers AS c1, Customers AS c2
WHERE c1.cust_name = c2.cust_name
AND c2.cust_contact = 'Jim Jones';3.自然联结
自然联结排除多次出现,使每一列只返回一次。
自然联结要求你只能选择那些唯一的列,一般通过对一个表使用通配符
(SELECT *),而对其他表的列使用明确的子集来完成。
要自己完成,系统不提供
事实上,我们迄今为止建立的每个内联结都是自然联结,很可能永远都
不会用到不是自然联结的内联结。
4.外联结
联结包含了那些在相关表中没有关联行的行。这种联结
称为外联结。
语法:
內联结:
SELECT Customers.cust_id, Orders.order_num
FROM Customers INNER JOIN Orders
ON Customers.cust_id = Orders.cust_id;外联结:
使用场景
对每个顾客下的订单进行计数,包括那些至今尚未下订单的顾客;
列出所有产品以及订购数量,包括没有人订购的产品;
计算平均销售规模,包括那些至今尚未下订单的顾客。
SELECT Customers.cust_id, Orders.order_num
FROM Customers LEFT OUTER JOIN Orders
ON Customers.cust_id = Orders.cust_id;在使用 OUTER
JOIN 语法时,必须使用 RIGHT 或 LEFT 关键字指定包括其所有行的表
(RIGHT 指出的是 OUTER JOIN 右边的表,而 LEFT 指出的是 OUTER JOIN
左边的表)。
也就是left 将要联结左侧的那个表全部选出
right 将右侧的那个表全选出
全外联结
Access、MariaDB、MySQL、Open Office Base 和 SQLite 不支持 FULL
还存在另一种外联结,就是全外联结(full outer join),它检索两个表中
的所有行并关联那些可以关联的行。与左外联结或右外联结包含一个表
的不关联的行不同,全外联结包含两个表的不关联的行。
联结使用条件
注意所使用的联结类型。一般我们使用内联结,但使用外联结也有效。
关于确切的联结语法,应该查看具体的文档,看相应的 DBMS 支持何种语法(大多数 DBMS 使用这两课中描述的某种语法)。
保证使用正确的联结条件(不管采用哪种语法),否则会返回不正确
的数据。
应该总是提供联结条件,否则会得出笛卡儿积。
在一个联结中可以包含多个表,甚至可以对每个联结采用不同的联结
类型。虽然这样做是合法的,一般也很有用,但应该在一起测试它们
前分别测试每个联结。这会使故障排除更为简单。
join区别
普通的join是笛卡尔积,即为两张表的排列组合

起别名
在使用时直接用AS +别名就可以用了 ^1cd456
只能每次用的时候起一次别名并且当时使用
下一个语句别名就不能用了,要重新起名字
UNION
语法:
适用于从多个不同的表中挑选不同的列
UNION 中的每个查询必须包含相同的列、表达式或聚集函数(不过,
各个列不需要以相同的次序列出)
UNION 从查询结果集中自动去除了重复的行;换句话说,它的行为与一
条 SELECT 语句中使用多个 WHERE 子句条件一样。
这是 UNION 的默认行为,如果愿意也可以改变它。事实上,如果想返回
所有的匹配行,可使用 UNION ALL 而不是 UNION
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All';排序
SELECT 语句的输出用 ORDER BY 子句排序。在用 UNION 组合查询时,只
能使用一条 ORDER BY 子句,它必须位于最后一条 SELECT 语句之后。对
于结果集,不存在用一种方式排序一部分,而又用另一种方式排序另一部分的情况,因此不允许使用多条 ORDER BY 子句
用它来排序所有 SELECT 语句返回的所有结果。
建表
CREATE TABLE A
(
prod_id CHAR(10) NOT NULL,
vend_id CHAR(10) NOT NULL,
prod_name CHAR(254) NOT NULL,
prod_price DECIMAL(8,2) NOT NULL,
prod_desc VARCHAR(1000) NULL
);要指定行列,并且后跟列的数据
类型
CREATE TABLE Orders
(
order_num INTEGER NOT NULL,
order_date DATETIME NOT NULL,
cust_id CHAR(10) NOT NULL
);不要把 NULL 值与空字符串相混淆。NULL 值是没有值,不是空字符串。
如果指定’’(两个单引号,其间没有字符),这在 NOT NULL 列中是允
许的。空字符串是一个有效的值,它不是无值。NULL 值用关键字 NULL
而不是空字符串
默认值在 CREATE TABLE 语句的列定义中用关键字 DEFAULT 指定
更新表定义,可以使用 ALTER TABLE 语句。
使用 ALTER TABLE 更改表结构,必须给出下面的信息:
在 ALTER TABLE 之后给出要更改的表名(该表必须存在,否则将
出错);
列出要做哪些更改
ALTER TABLE Vendors
ADD vend_phone CHAR(20);更改或删除列、增加约束或增加键,这些操作也使用类似的语法(注意,
下面的例子并非对所有 DBMS 都有效):
输入▼
ALTER TABLE Vendors
DROP COLUMN vend_phone;
使用 ALTER TABLE 要极为小心,应该在进行改动前做完整的备份(表
结构和数据的备份)。数据库表的更改不能撤销,如果增加了不需要的
列,也许无法删除它们。类似地,如果删除了不应该删除的列,可能
会丢失该列中的所有数据。
删除表(删除整个表而不是其内容)非常简单,使用 DROP TABLE 语句即可:
DELETE 只删除表的内容不删除表本身
重新命名
ALTER TABLE oldname RENAME TO newname;视图
视图为虚拟的表。它们包含的不是数据而是根据需要检索数据的查询。
视图提供了一种封装 SELECT 语句的层次,可用来简化数据处理,重新
格式化或保护基础数据。
用视图将联结集合起来,也就是一个子查询,相当于一个API
创建 视图用 CREATE VIEW 语句来创建。与 CREATE TABLE 一样,CREATE VIEW
删除 删除视图,可以使用 DROP 语句,其语法为 DROP VIEW viewname;。
覆盖(或更新)视图,必须先删除它,然后再重新创建。
用法:
建立视图
CREATE VIEW ProductCustomers AS
SELECT cust_name, cust_contact, prod_id
FROM Customers, Orders, OrderItems
WHERE Customers.cust_id = Orders.cust_id
AND OrderItems.order_num = Orders.order_num;这条语句创建一个名为 ProductCustomers 的视图,它联结三个表,返
回已订购了任意产品的所有顾客的列表。
使用视图
使用时,
SELECT cust_name, cust_contact
FROM ProductCustomers
WHERE prod_id = 'RGAN01';也可以用于统一格式
CREATE VIEW VendorLocations AS
SELECT RTRIM(vend_name) || ' (' || RTRIM(vend_country) || ')'
AS vend_title
FROM Vendors;之后可用
SELECT *
FROM VendorLocations;用于过滤也一样
CREATE VIEW CustomerEMailList AS
SELECT cust_id, cust_name, cust_email
FROM Customers
WHERE cust_email IS NOT NULL;之后
SELECT *
FROM CustomerEMailList;计算字段
CREATE VIEW OrderItemsExpanded AS
SELECT order_num,
prod_id,
quantity,
item_price,
quantity*item_price AS expanded_price
FROM OrderItems;之后
SELECT *
FROM OrderItemsExpanded
WHERE order_num = 20008;存储(不会)
可以创建存储过程。简单来说,存储过程就是为以后使用而保存的一条
或多条 SQL 语句。可将其视为批文件,虽然它们的作用不仅限于批处理
通过把处理封装在一个易用的单元中,可以简化复杂的操作(如前面
例子所述)。
由于不要求反复建立一系列处理步骤,因而保证了数据的一致性。如
果所有开发人员和应用程序都使用同一存储过程,则所使用的代码都
是相同的。
EXECUTE AddNewProduct( ‘JTS01’,
‘Stuffed Eiffel Tower’,
6.49,
‘Plush stuffed toy with the text La
➥Tour Eiffel in red white and blue’ );
管理事务处理(不会深入学习的时候再看)
使用事务处理(transaction processing),通过确保成批的 SQL 操作要么
完全执行,要么完全不执行,来维护数据库的完整性
事务(transaction)指一组 SQL 语句;
回退(rollback)指撤销指定 SQL 语句的过程;
提交(commit)指将未存储的 SQL 语句结果写入数据库表;
保留点(savepoint)指事务处理中设置的临时占位符(placeholder),
可以对它发布回退(与回退整个事务处理不同)。
事务处理用来管理 INSERT、UPDATE 和 DELETE 语句。不能回退 SELECT
语句(回退 SELECT 语句也没有必要),也不能回退 CREATE 或 DROP 操
作。事务处理中可以使用这些语句,但进行回退时,这些操作也不撤销。
游标
有时,需要在检索出来的行中前进或后退一行或多行,这就是游标的用
途所在。游标(cursor)是一个存储在 DBMS 服务器上的数据库查询,
它不是一条 SELECT 语句,而是被该语句检索出来的结果集。在存储了
游标之后,应用程序可以根据需要滚动或浏览其中的数据。
游标的选项和特性
能够标记游标为只读,使数据能读取,但不能更新和删除。
能控制可以执行的定向操作(向前、向后、第一、最后、绝对位置、
相对位置等)。
能标记某些列为可编辑的,某些列为不可编辑的。
规定范围,使游标对创建它的特定请求(如存储过程)或对所有请求
可访问。
指示 DBMS 对检索出的数据(而不是指出表中活动数据)进行复制,
使数据在游标打开和访问期间不变化。
游标使用
在使用游标前,必须声明(定义)它。这个过程实际上没有检索数据,
它只是定义要使用的 SELECT 语句和游标选项。
一旦声明,就必须打开游标以供使用。这个过程用前面定义的 SELECT
语句把数据实际检索出来。
对于填有数据的游标,根据需要取出(检索)各行。
在结束游标使用时,必须关闭游标,可能的话,释放游标(有赖于具
体的 DBMS)。
声明游标后,可根据需要频繁地打开和关闭游标。在游标打开时,可根
据需要频繁地执行取操作。
创建游标
使用 DECLARE 语句创建游标,这条语句在不同的 DBMS 中有所不同。
DECLARE 命名游标,并定义相应的 SELECT 语句,根据需要带 WHERE 和
其他子句。为了说明,我们创建一个游标来检索没有电子邮件地址的所
有顾客,作为应用程序的组成部分,帮助操作人员找出空缺的电子邮件
地址
语法
DECLARE CustCursor CURSOR
FOR
SELECT * FROM Customers
WHERE cust_email IS NULL使用游标
OPEN CURSOR CustCursor关闭游标
CLOSE CustCursor
DEALLOCATE CURSOR CustCursor约束(不会捏)
DBMS 通过在数据库表上施加约束来实施引用完整性。大多数约束是在
表定义中定义的,如第 17 课所述,用 CREATE TABLE 或 ALTER TABLE
语句。
主键
我们在第 1 课简单提过主键。主键是一种特殊的约束,用来保证一列(或
一组列)中的值是唯一的,而且永不改动。换句话说,表中的一列(或
多个列)的值唯一标识表中的每一行。这方便了直接或交互地处理表中
的行。没有主键,要安全地 UPDATE 或 DELETE 特定行而不影响其他行会
非常困难。
表中任意列只要满足以下条件,都可以用于主键。
任意两行的主键值都不相同。
每行都具有一个主键值(即列中不允许 NULL 值)。
包含主键值的列从不修改或更新。(大多数 DBMS 不允许这么做,但
如果你使用的 DBMS 允许这样做,好吧,千万别!)
主键值不能重用。如果从表中删除某一行,其主键值不分配给新行。
一种定义主键的方法是创建它,如下所示
CREATE TABLE Vendors
(
vend_id CHAR(10) NOT NULL PRIMARY KEY,
vend_name CHAR(50) NOT NULL,
vend_address CHAR(50) NULL,
vend_city CHAR(50) NULL,
vend_state CHAR(5) NULL,
vend_zip CHAR(10) NULL,
vend_country CHAR(50) NULL
);在此例子中,给表的 vend_id 列定义添加关键字 PRIMARY KEY,使其成
为主键。
ALTER TABLE Vendors
ADD CONSTRAINT PRIMARY KEY (vend_id);这里定义相同的列为主键,但使用的是 CONSTRAINT 语法。此语法也可
以用于 CREATE TABLE 和 ALTER TABLE 语句
外键
外键是表中的一列,其值必须列在另一表的主键中。外键是保证引用完
整性的极其重要部分。我们举个例子来理解外键
如第 6 课所述,除帮助保证引用完整性外,外键还有另一个重要作用。
在定义外键后,DBMS 不允许删除在另一个表中具有关联行的行。例
如,不能删除关联订单的顾客。删除该顾客的唯一方法是首先删除相
关的订单(这表示还要删除相关的订单项)。由于需要一系列的删除,
因而利用外键可以防止意外删除数据。
有的 DBMS 支持称为级联删除(cascading delete)的特性。如果启用,
该特性在从一个表中删除行时删除所有相关的数据。例如,如果启用
级联删除并且从 Customers 表中删除某个顾客,则任何关联的订单行
也会被自动删除。
CREATE TABLE Orders
(
order_num INTEGER NOT NULL PRIMARY KEY,
order_date DATETIME NOT NULL,
cust_id CHAR(10) NOT NULL REFERENCES
➥Customers(cust_id)
);索引
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (inex_col_name,... ) ; UNIQUE 代表的是一个唯一的索引,不可重复
SHOW INDEX FROM table_name ;
iDROP INDEX index_name ON table_name ;
触发器
> 触发器是特殊的存储过程,它在特定的数据库活动发生时自动执行。触发
>
> 器可以与特定表上的 INSERT、UPDATE 和 DELETE 操作(或组合)相关联。
>
> 与存储过程不一样(存储过程只是简单的存储 SQL 语句),触发器与单
>
> 个的表相关联。与 Orders 表上的 INSERT 操作相关联的触发器只在
>
> Orders 表中插入行时执行。类似地,Customers 表上的 INSERT 和
>
> UPDATE 操作的触发器只在表上出现这些操作时执行。
> 触发器内的代码具有以下数据的访问权:
>
> INSERT 操作中的所有新数据;
>
> UPDATE 操作中的所有新数据和旧数据;
>
> DELETE 操作中删除的数据。
>
> 根据所使用的 DBMS的不同,触发器可在特定操作执行之前或之后执行。
>
> 下面是触发器的一些常见用途。
>
> 保证数据一致。例如,在 INSERT 或 UPDATE 操作中将所有州名转换
>
> 为大写。
>
> 基于某个表的变动在其他表上执行活动。例如,每当更新或删除一行
>
> 时将审计跟踪记录写入某个日志表。
```mysql
CREATE TRIGGER customer_state
ON Customers
FOR INSERT, UPDATE
AS
UPDATE Customers
SET cust_state = Upper(cust_state)
WHERE Customers.cust_id = inserted.cust_id;case 来进行多条件判断 不要忘记END
CASE WHEN XXX条件 THEN 满足的结果 ELSE 不满足结果 END多行耦合
CASE WHEN XXX条件1 THEN Y1
WHEN XXX 条件2 THEN Y2
WHEN XXX 条件3 THEN Y3 ELSE Y4 END
事务
一组操作的集合,不可分割,这些操作要么同时成功,要么同时失败,mysql默认提交方式是自动提交的,所以要改为手动提交才行
方式1
select @@autocommit; 查看提交方式,返回为1则为自动提交,否则为手动提交
set @@autocommit = 0 ; 设置为手动提交
commit 提交
rollback 回滚
方式二
事务操作
start transaction 或者 begin 开启事务
commit 提交
rollback 回滚 事务特点
原子性 一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性 在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性 数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
持久性 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
并发事务问题
- 脏读 一个事务读到另一个事务还没有提交的数据
- 不可重复读,一个事务先后读取一条重复记录,但两次读取的数据不同,成为不可重复读
- 幻读 一个事务按照条件查询时,没有对应的数据行但是在插入数据时,这行数据已经存在了,出现了幻影
事务隔离级别
可以手动设置系统的隔离级别
引擎
CREATE TABLE 表名(
字段1 字段1类型 [ COMMENT 字段1注释 ] ,
......
字段n 字段n类型 [COMMENT 字段n注释 ]
) ENGINE = INNODB [ COMMENT 表注释 ] ;
show engines;InnoDB特点
支持事务,行级锁,外键约束
锁
全局锁:锁定数据库中的所有表。
表级锁:每次操作锁住整张表。
行级锁:每次操作锁住对应的行数据。
常用函数
1)、length():mysql里面的length()函数是一个用来获取字符串长度的内置函数。
2)、char_length():在mysql内置函数里面查看字符串长度的还有一个函数是char_length()。
3)、这两个函数的区别是:
a)、length(): 单位是字节,utf8编码下,一个汉字三个字节,一个数字或字母一个字节。gbk编码下,一个汉字两个字节,一个数字或字母一个字节。
b)、char_length():单位为字符,不管汉字还是数字或者是字母都算是一个字符。
正则表达式
^:表示一个字符串或行的开头
[a-z]:表示一个字符范围,匹配从 a 到 z 的任何字符。
[0-9]:表示一个字符范围,匹配从 0 到 9 的任何字符。
[a-zA-Z]:这个变量匹配从 a 到 z 或 A 到 Z 的任何字符。请注意,你可以在方括号内指定的字符范围的数量没有限制,您可以添加想要匹配的其他字符或范围。
[^a-z]:这个变量匹配不在 a 到 z 范围内的任何字符。请注意,字符 ^ 用来否定字符范围,它在方括号内的含义与它的方括号外表示开始的含义不同。
[a-z]*:表示一个字符范围,匹配从 a 到 z 的任何字符 0 次或多次。
[a-z]+:表示一个字符范围,匹配从 a 到 z 的任何字符 1 次或多次。
.:匹配任意一个字符。
\.:表示句点字符。请注意,反斜杠用于转义句点字符,因为句点字符在正则表达式中具有特殊含义。还要注意,在许多语言中,你需要转义反斜杠本身,因此需要使用\\.。
$:表示一个字符串或行的结尾。JDBC
//导包
import com.mysql.jdbc.Driver;
import javax.swing.plaf.nimbus.State;
import java.sql.*;
public class Name {
public static void main(String[] args) throws Exception {
//注册驱动程序
Class.forName("com.mysql.jdbc.Driver");
//获取连接
String url = "jdbc:mysql://localhost:3306/t";
String username = "root";
String password = "hutao1224";
Connection conn = DriverManager.getConnection(url,username,password);
//获取执行sql语句的对象
String sql = "insert into employees (name)value ('Amy');";
Statement stmt = conn.createStatement();
//执行sql语句
int count = stmt.executeUpdate(sql);
//处理结果
System.out.println(count);
//释放资源
stmt.close();
conn.close();
}
}防止sql注入使用
@Test
public void testPreparedStatement() throws Exception {
//2. 获取连接:如果连接的是本机mysql并且端口是默认的 3306 可以简化书写
String url = "jdbc:mysql:///db1?useSSL=false";
String username = "root";
String password = "1234";
Connection conn = DriverManager.getConnection(url, username, password);
// 接收用户输入 用户名和密码
String name = "zhangsan";
String pwd = "' or '1' = '1";
// 定义sql
String sql = "select * from tb_user where username = ? and password = ?";
// 获取pstmt对象
PreparedStatement pstmt = conn.prepareStatement(sql);
// 设置?的值
pstmt.setString(1,name);//?的位置和参数
pstmt.setString(2,pwd);
// 执行sql
ResultSet rs = pstmt.executeQuery();// 不需要传递sql语句了
// 判断登录是否成功
if(rs.next()){
System.out.println("登录成功~");
}else{
System.out.println("登录失败~");
}
//7. 释放资源
rs.close();
pstmt.close();
conn.close();
}变量的使用
占位符?只能用来取代sql语句中的常变量,而不能取代列名或者表名
select ? from ? where ? 前两个?不成立,只能用 "+variable+" 的方式Redis
面试常问
- 一致性哈希:整个哈希值的空间被视为一个环形,每个节点或数据都被映射到整个环上,当需要查找某个键时,会沿着环查找第一个匹配的节点。
- 数据结构:
- SkipList跳表,ZSet中如果保存到键值对数量<128 && 每个元素的长度小于64B就使用ziplist,否则则使用skiplist
- 数据按照升序排序存储
- 节点可能包含多个指针,指针跨度不同
- SortedSet是有序集合,底层存储的每个数据都包含element和score两个值,score是得分,element是字符串值,会根据element和score值排序,形成有序集合,基于SkipList实现的
- Redis如何判断KEY是否过期呢?
- 答:在Redis中会有两个Dict,也就是HashTable,其中一个记录KEY-VALUE键值对,另一个记录KEY和过期时间。要判断一个KEY是否过期,只需要到记录过期时间的Dict中根据KEY查询即可。
- SkipList跳表,ZSet中如果保存到键值对数量<128 && 每个元素的长度小于64B就使用ziplist,否则则使用skiplist
- 集群问题:
- Sentinel是哨兵:监控节点状态并自动实现故障转移

- 哨兵的作用:状态监控,故障转移,状态通知
- 主观下线是某一个sentinel节点发现某个节点没在规定时间内响应,客观下线是指的是有一半以上的sentinel都认为下线了才行
- 选举新的master:
- 选举规则:判断优先级,判断offset值,越高越优先,判断id,越小越优先
- 故障检测:sentinel检测主节点和从节点的在线情况,如果有半数以上的sentinel认为主节点故障,就会开始选举
- sentinel选举出一个leader节点,每个sentinel都有资格,sentinel确定master下线之后就会请求其他sentinel同意自己成为leader,票数大于一半的sentinel即可成为leader,如果没有选出,就重复直到选出
- 选举根据 数据复制的偏移量更大(数据最新),运行id更小(运行时间更长 ),节点的优先级进行选举
- 通知所有的从节点设置新的主节点,并且进行复制
- 通知客户端重新连接主节点
- 主从复制:
- 全量同步,当slave第一次连接到master或者slave断开太久了,repl_baklog(复制积压缓冲区)的offset已经被覆盖了,同步过程中收到的读写命令都会先执行然后记录在repl_baklog中,逐个发送给slave

- 从节点保存主节点信息,与主节点建立连接,主节点判断是否是第一次请求,是就与从节点同步版本信息
- 主节点fork一个子进程保存当前所有的数据,2.发送数据快照3.之后主节点每次执行其他的操作都会同步给从节点
**
Replication Id**:简称replid,是数据集的标记,replid一致则是同一数据集。每个master都有唯一的replid,slave则会继承master节点的replid**
offset**:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
- 增量同步:

- 根据offset来进行同步
- 具体的比较是通过
repl_baklog,记录Redis处理过的命令及offset,包括master当前的offset,和slave已经拷贝到的offset发送的是命令:
- 全量同步,当slave第一次连接到master或者slave断开太久了,repl_baklog(复制积压缓冲区)的offset已经被覆盖了,同步过程中收到的读写命令都会先执行然后记录在repl_baklog中,逐个发送给slave
- 防止脑裂问题:设置主节点最少需要的从节点数,小于这个数量主节点就会禁止写数据,设置主从复制和同步的最大延迟,如果时间超过这个延迟就会禁止写数据。同时可以用主观下线和客观下线,当出现网络分区时,有部分的节点仍然能够连接上主节点,于是就不会出现重新选举主节点。
- offset复制偏移量:主从各自维护自己的offset,子节点把自己的offset上报,master保存offset ,部分复制使用二者的偏移量来同步缺失的数据
- 分片集群:

- 每个master保存不同的数据,然后每个master都可以有多个slave节点,之后master之间通过ping来检测彼此之间的健康状态,客户端请求可以访问集群任意节点,最终都会被转发到数据所在的节点
- 故障转移:每个master转移到自己的slave即可
- 为什么插槽的数量是16384,16384是2的14次方,是一个平衡性、行呢个和兼容性之间取得折衷的结果
- 如何将同一类数据固定的保存在同一个Redis实例?
- Redis计算key的插槽值时会判断key中是否包含
{},如果有则基于{}内的字符计算插槽 - 所以只要用{key} 作为前缀即可把相同的类型的数据计算的插槽一定相同
- Redis计算key的插槽值时会判断key中是否包含
- 常见的缓存有几种:
- 旁路缓存:使用应用程序来保证缓存和数据库的一致性
- 先写DB然后直接删除cache
- 为何删除? 1.如果db频繁更改,导致cache中的数据很少被访问,删除可以节省服务端的资源 2. 更新cache更容易造成缓存不一致的现象
- 为何不能先删除cache? 因为 如果有两个请求同时访问,请求1先把cache中的数据删除了,请求二就会从db中读取数据,然后请求一再更改db,会导致请求2读到的是旧值
- 写cache的速度要比写db快很多,所以很少会造成不一致
- 从cache中读取数据,读不到再从db中读入并返回,然后放到cache中
- 缺点:
- 首次请求不在cache中:可以将热点数据提前放入
- 先写DB然后直接删除cache
- 读写穿透:以cache为主,让cache服务操作,不需要
- 写:先写cache,cache没有时直接写db,有的话先更新cache,之后更新db 同步更新
- 读:直接读cache,cache没有直接读db,然后放入cache.
- 异步缓存写入:也是由cache服务来处理,但是更新时,只更新cache,由异步处理来更新db
- 缺点:容易造成数据不一致
- 适合对数据一致性要求没那么 高的
- 旁路缓存:使用应用程序来保证缓存和数据库的一致性
- Redis单线程模型:Redis对于每一个客户端的连接都关联一个指令队列和响应队列
- 为何单线程性能还这么高?
- 使用纯内存访问,
- 单线程避免不必要的上下文切换和竞争
- IO多路复用,对于多个IO,Redis每次处理其中一个IO然后暂停对其他的IO事件。使用一个线程来监听多个socket某个socket可读时及逆行读写
- 实现:select(文件描述符有上限),poll这俩只会通知用户有有Socket就绪,不确定具体的是哪个,需要轮询来找
- epoll会通知用户的时候把哪个socket也直接写入用户空间
- 详细介绍一下为什么I/O复用
- Redis是纯内存的,所以性能取决于网络延迟,I/O多路复用实现了高效的网络请求
- 常见的IO有 阻塞,非阻塞,多路复用
- 非阻塞式IO,读到多少就都多少,写多少,不会等待满足字节要求
- 优点:避免了线程切换的消耗。
- 为何单线程性能还这么高?
- 主从复制: 主服务器执行写操作时,会将写操作同步给从服务器,从服务器只读,并执行主服务器同步过来的指令 缺点:主服务器宕机时必须手动恢复
- 哨兵模式: 监控主从服务器,提供主从节点故障转移的功能
- 切片集群:将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
- 脑裂问题: 由于网络问题,集群节点之间失去联系。主从数据不同步;重新平衡选举,产生两个主服务。等网络恢复,旧主节点会降级为从节点,再与新主节点进行同步复制的时候,由于会从节点会清空自己的缓冲区,所以导致之前客户端写入的数据丢失了。 解决: 当主节点发现从节点下线或者通信超时的总数量大于阈值时,那么禁止主节点进行写数据,直接把错误返回给客户端。
- Sentinel是哨兵:监控节点状态并自动实现故障转移
- 数据相关:
- 数据淘汰策略:
- 如何保证Redis中的数据是热点数据? 答案是可以使用LRU删除策略,每次删除数据时删除最近最少使用的键,同时也可以主动去更新热点数据
- 其余的各种内存淘汰机制:1.内存到达限制时返回错误,不删除,2.删除最近最少使用键,3.lru但是只删除设置了过期时间的键,4.随机删除一些 5. 随机删除一些设置了过期时间的键6. 对访问频率来进行删除

- 持久化:
- RDB:创建数据的快照,存的是实际的数据
- redis建立新的子进程,父进程继续处理请求,子进程负责将内存内容写到临时文件,os的实时复写copy-on-write会使得父进程和子进程共享一个物理页面,所以会为父进程要修改的页面创建副本,所以子进程内的数据就是fork时的快照。 子进程写完文件之后,使用临时文件代替原来的快照文件,之后子进程quit, 进行的是全量快照,会把整个数据全部保存
- AOF:
- 重写:AOF重写会调用一个子进程,由子进程去进行重写,会读取数据库中的键值对为每一个键值对生成一个或多个写命令,这些写命令足以恢复这个键值对的状态。然后把他们写入一个新的AOF文件中,同时Redis会维护一个AOF缓冲区,把重写期间进行的数据库写操作记录到缓冲区中,重写完毕之后会把新的AOF文件发给主进程,然后退出,主进程把缓冲区中的写命令写入其中并使用新的AOF文件替换旧的AOF文件
- RDB:创建数据的快照,存的是实际的数据
- 注意:实现原理是操作系统会为进程
- AOF:记录操作命令而不是副本。
- fork,子进程向临时文件中写入重建数据库状态的命令
- 父进程接收到请求后,把写命令写入到原来的aof文件中,然后缓存起来这些命令
- 子进程搞完之后,通知父进程,父进程把缓存起来的命令写入临时文件
- 使用临时文件替代老文件,注意不会读取老文件
- 混合持久化:两者结合,惰性删除:只有在访问这个键的时候才检查是否过期
- 读写分离问题:读占比较大时可以把一部分的流量摊到从节点,只对主节点进行写服务。
- AOF:记录操作命令而不是副本。
- 过期策略:惰性删除和定时删除,Redis使用了两种结合的方式:当某个key被访问时,会定期检查是否过期,如果过期就删除,同时会定期对一部分key进行检查,如果过期就删除
- 周期删除的模式:
- SLOW模式:通过定时任务定期抽样部分带有TTL的key,判断是否过期。如果过期key比例较高会多次抽象
- FAST模式:Redis每次处理NIO事件之前,都会抽样部分带有TTL的key,判断是否过程,因此频率较高。如果时间充足并且过期key比例过高,也会多次抽样。
- 周期删除的模式:
- 数据淘汰策略:
缓存问题
- 缓存问题:
- 缓存雪崩:大量缓存 在同一时间失效或者Redis宕机导致后面的请求都直接落到了db
- 修改key的TTL,设置随机TTL
- 将缓存失效时间打散,在失效时间基础上加一个随机值
- 设置缓存不过期
- 搭建Redis的集群,哨兵模式,集群模式
- 给业务限流,nginx和spring cloud gateway
- 使用多级缓存,Guava和Caffeine + Redis, 前面这俩是缓存在服务中的JVM中的,分布式项目中不能跨服务,但是请求速度是最快的,因为是本地的缓存
- 给缓存业务添加降级限流策略
- 修改key的TTL,设置随机TTL
- 缓存击穿:热点key过期,大量的请求直接给数据库压力
- 互斥锁方案,保证同一时间只能有一个业务线程请求业务缓存
- 不给热点数据设置过期时间,由异步更新缓存,或者在热点数据要过期的时候,提前通知前台线程更新缓存或者重新设置过期时间,保证高可用,数据不会是绝对一致的
- 缓存穿透:访问的数据不在缓存中,每次都直接查询数据库,给数据库很大压力 ,解决方案是使用布隆过滤器
- 非法请求的限制,当有大量恶意请求访问不存在的数据时,在API入口要判断请求参数是否合理
- 设置空值或者默认值
- 使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在:
- 布隆过滤器对一个数据用多个哈希函数来映射,当查询时,如果多个哈希函数的映射后任何一个索引都为0,则一定不存在,如果所有的映射后的位置都是1时,则可能存在集合中。使用的是位图

- 数据一致性
- 双写一致问题:
- 保证一致性
1. 写使用的延迟双删,删两次缓存,等数据库修改完之后再删除一次缓存,用于解决数据库主从一致性问题,与缓存同步为u管。
2. Cache Aside 旁路缓存策略
- 写策略:先更新数据库再删除缓存中的数据
- 读策略:如果命中了缓存,直接返回,否则从数据库中读入数据并写入缓存,返回给用户
3. Read/Write Through 读穿/写穿策略: 应用程序只与缓存交互,由缓存组件和数据库交互,
- 读为名周直接查数据库然后写入缓存
- 写未命中,缓存存在直接写缓存,然后由缓存组件去更新数据库。缓存不存在则直接更新数据库
4. Write Back(写回)策略- 使用读锁(共享锁)和写锁(排他锁)
- 允许短暂不一致:
- 使用消息队列,先修改数据库,数据库修改完之后向MQ发送消息,由cahe服务接受消息来对缓存进行更新
- 取决于mq的可靠性
- 保证一致性
- 双写一致问题:
- 缓存雪崩:大量缓存 在同一时间失效或者Redis宕机导致后面的请求都直接落到了db
- 延时队列: 把当前要做的事情推迟一段时间再做,如下单未付款取消
- 可以使用 Zset来纯理,Score属性来存储延迟执行的时间
- zadd score1 value1;
- 大key value的值很大
- 分布式问题:
- 分布式锁:setnx 实际使用应该使用 set key value nx ex time 因为这个可以直接在原子性指定时间
- Reddsion来续锁:使用lua脚本,来保证原子性
- 一个线程获得锁,然后在事务中调用了另一个事务,另一个事务也同样对相同的锁加锁,会发生什么?
- 如果是直接使用Redis,会阻塞,然后等锁过期后,被调用的函数可以执行,被调用的函数执行之后会释放锁,返回到第一个函数执行,第一个函数执行之后就会重复释放这个锁,无法保证原子性了。
- 如果使用Redssion,Redssion的RLock数据结构实现了可重入锁:
- key,status持有还是释放 ,UUID标识线程 , 持有时间(最长的存活时间)
- Redis中存的value字段为锁的次数
- 一个线程获得锁,然后在事务中调用了另一个事务,另一个事务也同样对相同的锁加锁,会发生什么?
{
"myLock": {
"status": "LOCKED",
"owner": "some-unique-uuid",
"hold_count": 2
}
} - 这个问题中就会直接判断出是同一个线程的调用,所以只会给锁的持有技术+1,不会阻塞
multi开始事务,discard取消事务redis的事务在出错时,只会回滚出错的命令
使用watch key 来对某一个key加上乐观锁
Redis 与 Memcached 区别:
- Redis支持的数据类型更丰富:Sting Hash List Set Zset, M只支持key-value数据类型
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中。
- Redis原生支持集群模式
- Redis支持发布订阅模型,LUa吉奥本,事务等
数据类型
- String 类型的应用场景:SDS,可以存任何类型,直接存在二进制buf数组里
- List 实现是:
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
Redis在执行命令的时候是单线程,但是也使用了多线程的来处理网络IO操作
- 不是,Redis会启动后台: 三个线程各自有自己的任务队列,
- 处理关闭文件
- 处理AOF刷盘
- 异步释放Redis内存,也就是lazyfree线程
- 主线程,负责执行命令
- 三个I/O线程来分担网络I/O压力
- 这些任务的操作都是很耗时的,如果把这些任务都放在主线程来处理,那么 Redis 主线程就很容易发生阻塞,这样就无法处理后续的请求了。
- 不是,Redis会启动后台: 三个线程各自有自己的任务队列,
过期删除和内存淘汰: Redis使用懒惰性删除和定期删除。 惰性删除时指不主动删除过期键,每次反问key时检查是否过期,如果过期,则删除。 优点是:减少对系统资源的使用,缺点是:不能及时释放内存
- 定期删除:每过一段时间,从数据库中取出一定数量的key来进行检查,删除其中的过期key,如果过期key超过一定比例,重复执行定期删除
- 当 Redis 运行在主从模式下时,从库不会进行过期扫描,从库对过期的处理是被动的。也就是即使从库中的 key 过期了,如果有客户端访问从库时,依然可以得到 key 对应的值,像未过期的键值对一样返回。
- 从库的过期键处理依靠主服务器控制,主库在 key 到期时,会在 AOF 文件里增加一条 del 指令,同步到所有的从库,从库通过执行这条 del 指令来删除过期的 key。REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库,非关系型数据库,
内存淘汰: 随机淘汰,LRU最近最少使用,根据最后一次访问的时间 , LFU最近最不常使用,根据访问次数来淘汰
Lua :Redis 在执行 Lua 脚本时,可以以原子性的方式执行
Lua脚本使用
- EVAL执行脚本
EVAL script numkeys key [key …] arg [arg …] - SCRIPT LOAD script.lua 把脚本加载到redis-serve中,返会一个 SHA1校验和,之后无论是哪个客户端都可以使用这个校验和来运行脚本。
- EVALSHA sha1校验和 numkeys key [key …] arg [arg …]
- SCRIPT EXISTS sha1来检验这个脚本是否还在
- SCRIPT FLUSH刷新所有已经保存的脚本
- redis-cli -a 密码 –eval lua脚本内容
- EVAL执行脚本
对于基本数据类型的操作
- string
- redis中的string可以包含任何数据,包括jpg和序列化的对象,因为string是byte [] 数组
- setrange key number string 从number开始的下标处替换string,从0开始
- mset 设置多个
- xxnx not exit 不存在的话在设置
- getrange key begin end
- incryby key 增量 修改数据
- append key 加
- strlen 获取长度
- hash: string类型的 field 和 value的映射表,占用内存更少,方便取整个对象
- hset/hsetnx key field1 value1
- hmget 获取多个fields
- hexists key field 测试field是否存在
- hlen key 有多少field
- hkeys key 获取所有的field
- hvals 获取所有的value
- hgetall == hvals + hkeys
- list 底层是链表,可当作queue使用,有序,可重复,key为链表的名字
- lpush 头部添加 rpush尾部添加,linsert key
- lset 重新设定指定位置的数据
- lrem key count value 从头开始删除count个和value一样值的数据, count > 0 从头开始,count < 0从尾部开始,count == 0 删除所有的
- ltrim 只保留给定范围的数据
- lpop/rpop
- rpoplpush key1 key2 将key1的尾部移除并加入key2的头部,原子操作
- lindex下标访问
- llen获取长度
- set
- 便于求集合的交并差,无序集合,不可重复
- sadd key value
- srem key value
- spop key 随机删除并返回一个元素
- sdiff 求交集 一个key1 多个key2 , key3,也就是在其他key中与其他key不同元素
- sdiffstore 将diff的结果保存到另一个key中
- sinter(store) 交集(存储)
- sunion(store) 并集
- smove 将key1 中的删除添加给第二个
- scard 统计元素个数
- sismember测试是否为key的元素
- srandmember随机返回不删除
- sorted sets
- 有序,不可重复,会关联一个double类型score来进行排序,是skip list 和 hash table的混合,score越小的越在前面
- zadd key score value
- zrem
- zincrby key score value 给这个元素的score添加
- zrank 按照从小到大排序返回某个member的排名
- zrerank反向排序
- zcount 返回给定区间score内的数量
- zcarf 返回元素数量
- zscore 返回score
- 常用指令:keys , del , expire,move转移把当前数据库中的数据转移到其他数据中,persist移除给定key的过期时间,randomkey随机返回一个key,rename,type
- ping,echo,select(0~15),dbsize返回当前数据库中所有的key数量,info获取服务器统计信息
- monitor实时转存收到的请求
- flushdb删除所选择的数据库的所有key
- fushall 删除所有数据库的所有key
- string
Redis 脚本命令
dockercompose快速搭建一主二从一哨兵的redis集群
version: '3'
services:
redis-master: # 主节点
image: redis:latest
command: redis-server --appendonly yes --requirepass bronya # 设置密码
volumes:
- ./data/master:/data
ports:
- "6379:6379"
networks:
- redis-network
redis-slave1:
image: redis:latest
command: redis-server --slaveof redis-master 6379 --appendonly yes --masterauth bronya
depends_on:
- redis-master
volumes:
- ./data/slave1:/data
networks:
- redis-network
redis-slave2:
image: redis:latest
command: redis-server --slaveof redis-master 6379 --appendonly yes --masterauth bronya
depends_on:
- redis-master
volumes:
- ./data/slave2:/data
networks:
- redis-network
redis-sentinel:
image: redis:latest
command: redis-sentinel /etc/redis/sentinel.conf
depends_on:
- redis-master
volumes:
- ./sentinel.conf:/etc/redis/sentinel.conf
networks:
- redis-network
networks:
redis-network:
driver: bridge下表列出了 redis 脚本常用命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | EVAL script numkeys key [key …] arg [arg …] 执行 Lua 脚本。 |
| 2 | EVALSHA sha1 numkeys key [key …] arg [arg …] 执行 Lua 脚本。 |
| 3 | SCRIPT EXISTS script [script …] 查看指定的脚本是否已经被保存在缓存当中。 |
| 4 | SCRIPT FLUSH 从脚本缓存中移除所有脚本。 |
| 5 | SCRIPT KILL 杀死当前正在运行的 Lua 脚本。 |
| 6 | SCRIPT LOAD script 将脚本 script 添加到脚本缓存中,但并不立即执行这个脚本。 |
- 选择数据库和登录
如果你想在Redis服务器启动时指定要使用的数据库和密码,可以通过命令行参数进行设置,例如:
redis-server --port 6379 --requirepass your_password --db 3
redis默认有0-15个数据库,直接选择即可
info 来获得服务器和数据库信息
MongoDB
是一种源代码可用的文档数据库,以序列化的 JSON 格式存储数据。MongoDB 将数据存储在外部存储器中,但在企业版中包含内存存储引擎。
常用于应对高并发、海量数据存储、数据库的高可扩展性
例如:社交场景保存用户信息,通过地理位置索引来实现附近的人
游戏场景存储用户信息,方便高效
日志
基本概念:
- 文档:数据存储的基本单位
- 索引:
- 单字段索引:索引建立的顺序无所谓,MongoDB会可以从头/尾开始遍历
- 复合索引:建立在多个字段之上的索引,顺序很重要
- 多键索引:如果一个字段是数组,对数组建立的索引就是多键索引,相当于会对数组的每个值都建立单字段索引,举例:给Tags建立索引,搜索时只需要tags数组即可筛选出带有tags的所有文档
- 哈希索引:按照数据的哈希值进行索引,用在哈希分片集群上
- 文本索引:不建议使用,性能低下
- 地理位置索引:
- 唯一索引:确保索引字段不会存储重复值
- TTL索引:提供一个过期机制,允许为每一个文档设置一个过期时间,当文档达到过期时间就会被删除,示例代码:` @Indexed(expireAfterSeconds = 60 * 60 * 24 * 30)private Date createdAt;
- TTL索引只能用于单字段
_id不支持TTL索引- 不能在上限集合(上限集合(Capped Collections)是一种特殊类型的集合,它有固定的大小。当集合达到其最大大小时,MongoDB会自动覆盖最旧的文档。)中删除文档
- 覆盖索引查询:
- 所有查询字段都要求是索引的一部分
- 结果中返回的所有字段都在同一个索引中
- 查询中没有字段为null
- 集合:集合是动态的,可以把不同类型的文档归为一个集合
- 盖子集合: 有上限的集合,用于日志,不支持crud,当超过上限时,会从最老的文档开始删除
db.createCollection("users.actions",{capped:true,size:16384,max:100})
- TTL集合: MongoDB也允许在特定的时间后废弃文档数据,有时候叫做生存时间time-to-live (TTL)集合这个功能实际上是通过一个特殊的索引实现的 创建TTL索引的方式如下:
db.reviews.createIndex({time_field:1},{expireAfterSeconds:3600})- time_field字段会定期检查时间戳,与当前时间比较,如果时间差大于设置的时间,文档会被自动删除,单位是s
- 盖子集合: 有上限的集合,用于日志,不支持crud,当超过上限时,会从最老的文档开始删除
- 文档->集合->数据库->MongoDB
- mongosh是一个js解释器,可以使用js标准库或者运行函数
- 使用js语法,db变量代表当前选用的数据库
- CRUD:
- 查询可以使用正则表达式
- 建立数据库直接use一个新的数据库即可
- 变量 = {…},之后db.集合.insertOne(变量)或者insertMany()
- db.集合.find()或者findOne()
- updateOne()
- db.集合.deleteOne/Many()
- db.dropDatabase()删除当前数据库
- db.collection.drop() 删除指定集合
- db.col.update({‘title’:’MongoDB 教程’},{$set:{‘title’:’MongoDB’}}) 对应的变量名({ “nMatched” : 1, “nUpserted” : 0, “nModified” : 1 },{multi:true}) 设置multi : true可以修改选定的所有文档
- 想显式创建集合:db.createCollection(xxx),通过size字段可以预分配空间的字节大小
- 创建索引:db.products.createIndex({slug: 1}, {unique: true})
- 1代表是升序,unique是指定索引的选项,指定了索引是唯一的,slug一般用于存储URL
- 聚合管道: 类似stream流和channel管道,可以执行一系列的handler,最后返回结果


Mybatis面试
- mybatis执行流程:
- 读取配置文件
- 构建会话工厂:会话工厂全局一个,生产sqlSession
- 创建会话:项目与数据库的会话,包含了执行sql语句的所有方法,每次操作一个会话,有多个
- Executor执行器
- 返回结果
- 延迟加载:懒加载,旨在需要使用数据的时候才进行实际的SQL查询
- 比如我们在关联查询中,我们会自动的把关联的用户数据也查询出来了,但是我们并不需要用户的信息,所以我们可以使用延迟加载,只有在我们使用用户信息的时候才会把结果查询出来
- 缓存:本地缓存
- 一级缓存:sqlsession ,实现方式是PerpertualCache,当Session进行flush或者close时会刷新缓存
- 二级缓存:mapper级别的