执行kubeadm 时报错,
MQ
面试常问:
生产者出现堆积如何解决
- 增加消费者
- 优化消费者的处理速度
- 使用优先队列,优先处理优先级高的消息
- 消息压缩:如果网络带宽是瓶颈
- 升级设备
- 消息过滤:生产者端发送真正需要处理的消息
- 调整生产者的速度
生产消费过程中如果服务出现异常,如何恢复
- 重试机制:
- 死信队列:将无法处理的消息放在一个特殊的队列中,由人工去处理或者特殊处理
- 备份和恢复:对于重要数据应该定期进行备份,当服务出现异常时,从备份中恢复数据。
- 服务降级
- 容错和冗余设计
AMQP协议
- AMQ Model组件:
- Producer
- Exchange 交换器,从Producer中收集消息并根据路由规则发送到对应的消息队列中
- Queue 消息队列,存储消息,直到消息被安全的投递到了消费者
- Binding 定义了 mq 和 exchange之间的关系,是路由表
- Consumer
RocketMQ
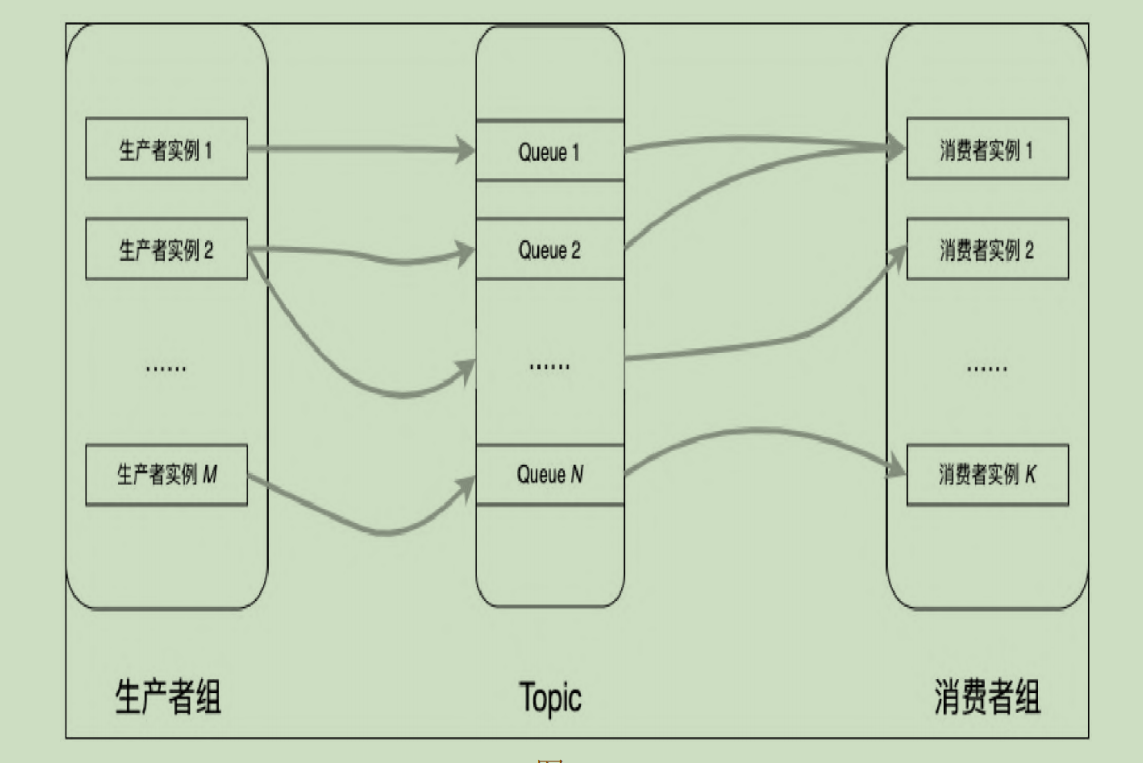
- 生产者组->发送消息的一方
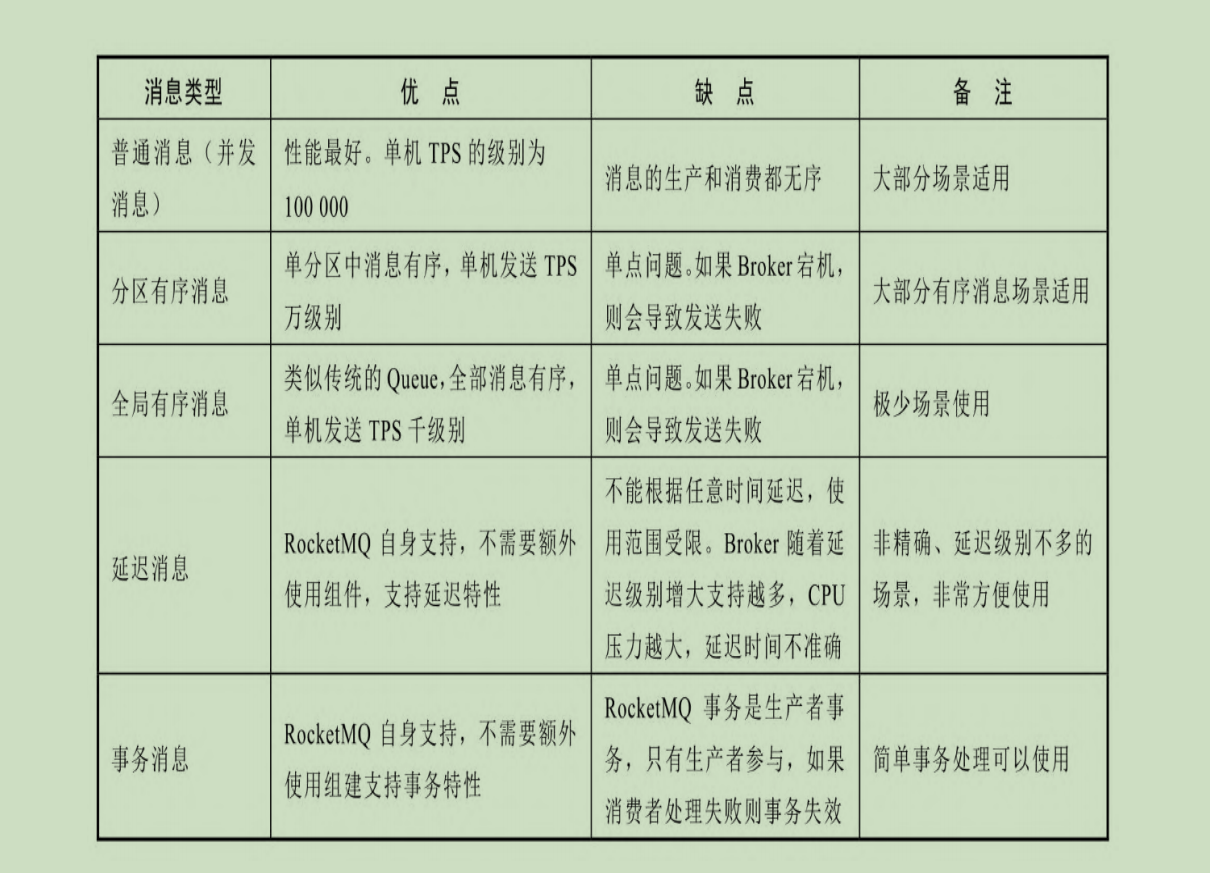
- 消息的类型:
- 普通消息:并发消息,并发消息没有顺序
- 分区有序消息:把一个Topic消息分为多个分区,保护和消费,分区内的消息就是队列,FIFO
- 全局有序:把一个Topic分区数设为1,所有的消息都支持FIFO
- 延迟消息:消息发送后,消费者不能立刻消费,需要等待
- 事务消息:涉及分布式事务,保证多个操作同时成功或者失败,消费者才能使用
- 消息保证机制:
- 客户端保证:重试机制和客户端容错(选择延迟较低的Broker来发送消息)
- Broker保证
- 消息发送流程:
- 业务层调用Client 发送API业务代码
- 消息处理层:Client获取消息对象后进行参数检查,准备和封装
- 通信层:基于Netty封装的RPC通信
- 消息的类型:
- Topic:
- 消费者组:
- 订阅关系:一个消费者组订阅一个Topic中的某一个Tag
- 消费模式:
- 集群消费模式:同一个组中的消费者实例负载均衡的消费Topic中的消息,消费进度保存在Broker端,即使应用崩溃,消费进度也不会出错
- 广播消费:所有消息广播分发,全部的消费者实例可以消费整个Topic中的所有消息,消费进度保存子啊客户端文件中,适用于通知其他服务刷新缓存
- 可靠消费保证:
- 重试-死信机制:正常Topic遭遇消费失败后->消息被保存在重试Topic中->多次间隔时间进行重新消费后仍然失败->进入死信Topic,经由人工处理,不会再被消费者消费
- Rebalance机制:重平衡, 用于在发生Broker掉线、Topic扩容和缩容、消费者扩容和缩容等变化时,自动感知并调整自身消费,以尽量减少甚至避免消息没有被消费。
- 消费方式:
- pull 用户主动pull消息,自主管理位点,由用户代码来进行管理
- push 自动pull消息,用户可直接使用,
- 消费过滤,Broker端可以根据tag进行消费过滤,只返回满足的tag,broker端使用Hash过滤,客户端再进行一次Tag字符串过滤, 因为Hash过来吧可以快速过滤大量数据,但是存在Hash碰撞
- Namesrv集群:一个无状态的元数据管理,Namesrv之于RocketMQ等价于Zookeeper之于Kafka。Topic路由注册和管理、Broker注册和发现的管理者
RabbitMQ
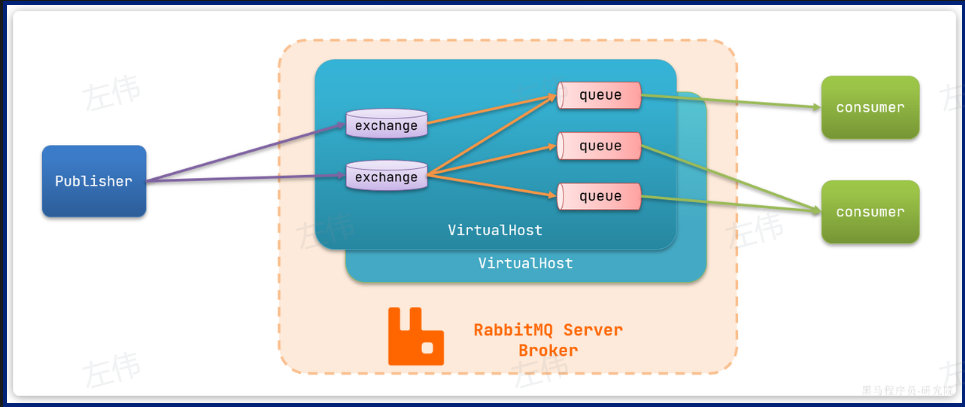
RabbitMQ主要架构
**
publisher**:生产者,也就是发送消息的一方**
consumer**:消费者,也就是消费消息的一方**
queue**:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理**
exchange**:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。不会持久化数据**
virtual host**:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue,也就是将exchange和queue进行分组
Spring中使用
使用Spring AMQP来实现
publisher
使用RabbitTemplate来发送消息
consumer
@Component
public class SpringRabbitListener {
// 利用RabbitListener来声明要监听的队列信息
// 将来一旦监听的队列中有了消息,就会推送给当前服务,调用当前方法,处理消息。
// 可以看到方法体中接收的就是消息体的内容
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueMessage(String msg) throws InterruptedException {
System.out.println("spring 消费者接收到消息:【" + msg + "】");
}
}交换机的类型:
Fanout
广播,将消息交给所有绑定到交换机的队列。我们最早在控制台使用的正是Fanout交换机
特点:
- 可以有多个队列
- 每个队列都要绑定到Exchange
- 生产者发送的消息只能发送到交换机
- 交换机把消息发送给绑定过的所有队列
- 订阅队列的消费者都能拿到消息
Direct
订阅,基于RoutingKey(路由key)发送给订阅了消息的队列
特点:
- 队列需要与交换机绑定,指定一个RountingKey
- 消息发送方发送时也需要指定RountingKey
- Exchange把消息发送给RountingKey对应的队列
Topic
通配符订阅,与Direct类似,只不过RoutingKey可以使用通配符
#:匹配一个或多个词*:匹配不多不少恰好1个词
举例:item.#:能够匹配item.spu.insert或者item.spuitem.*:只能匹配item.spu
与DIrect类似,但是可以使用通配符来进行队列绑定Headers:头匹配,基于MQ的消息头匹配,用的较少。
Netty
#todo
- 使用Netty替代springboot的tomcat作为服务器
- 使用Netty替代websocket来通信
- 更新一下一致性哈希算法,如何更高效,顺便加上解释
基本介绍和使用介绍
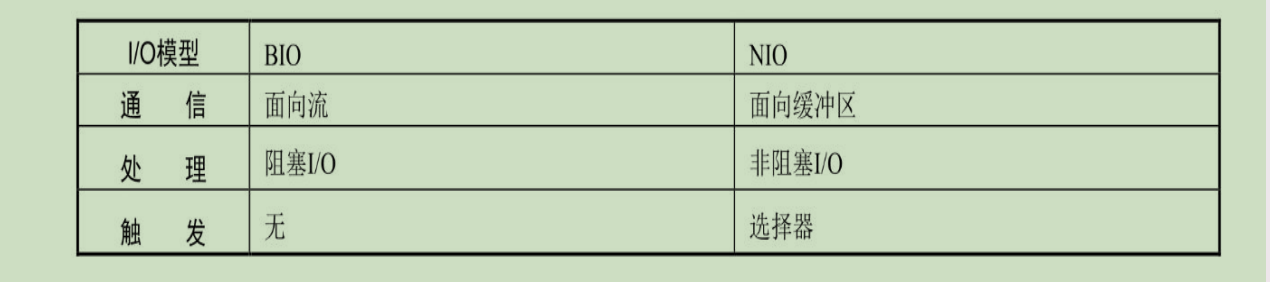
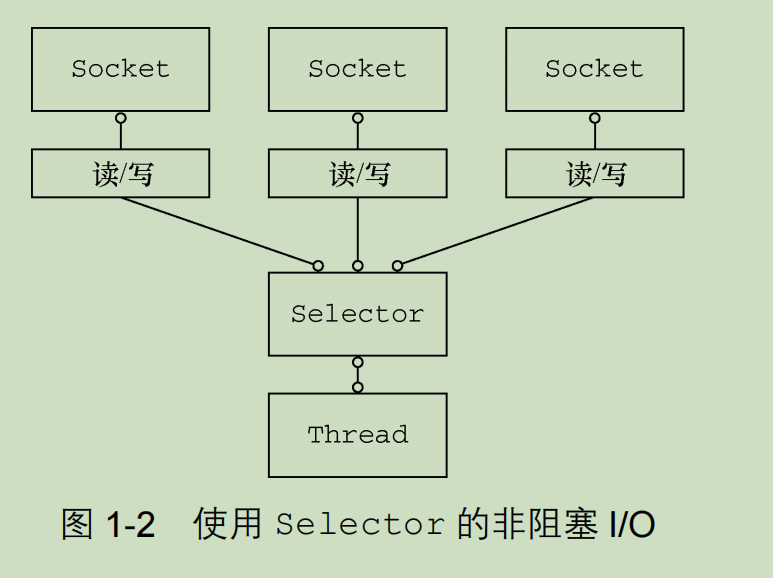
I/O模型:
- 阻塞I/O BIO:程序向内核发起I/O调用,发起调用的线程就一直等待内核返回结果。如果使用BIO实现异步,只能使用多线程模型,会导致增加线程切换的开销。
- 同步非阻塞IO NIO:应用程序通过轮询的方式获取请求结果。
- 多路复用I/O:多个进程的I/O可以注册到一个复用器上(Selector),如果Selector监听的所有的I/O内核缓冲区都没有可读数据,select调用会被阻塞,直到任意I/O在内核缓冲区中有刻度数据时,会立刻返回。并通知其他进程再次发起I/O,也就是使用一个线程监控多个IO操作。
- 信号驱动I/O:进程预先告知内核,向内核注册一个信号处理函数,之后进程返回不阻塞,进程通过信号处理函数继续调用I/O读取数据。IO操作就绪后,操作系统会发送信号通知应用程序。 通知何时可以开始一个I/O操作
- 异步I/O AIO:应用程序发起IO操作之后,立刻返回,操作系统在IO操作执行后,会通知应用程序,应用程序无需轮询IO状态。 通知I/O操作何时结束
- BIO和NIO的区别:
- AIO->异步I/O
Reactor 模型
是一种处理并发I/O操作的设计模式。核心思想是通过实践多路复用机制来管理多个I/O事件。
主要的组件:1. 事件多路分发器(负责监听多个I/O事件,将这些事件分发给相应的事件处理器)
2.事件处理器 3.事件分发器:将事件从多路分发器中分发到响应的处理器。
select、poll、epoll的区别
- select:将已连接的Socket都放在一个文件描述符集合中,然后调用select函数将文件描述集合拷贝到内核中,让内核来检查是否有网络事件发生,检查方式就是遍历文件描述符集合。
- poll:与select区别是,不再使用BitMap来存储文件描述符,突破了个数上限
- epoll:内核使用红黑树来关注待检测的Socket高效,使用事件驱动,内核维护了一个链表来记录就绪事件,只会将事件发生的Socket集合传递给应用程序吗,而不是轮询整个集合
如何解决对象创建和销毁问题
- 对象池服用技术
- 零拷贝技术:Netty在进行I/O读写时,直接使用DirectBuffer,从而直接避免了数据在堆内存和堆外内存之间的拷贝
零拷贝
数据从读取到内核缓冲区,然后直接由内核缓冲区发送到网络。而不是拷贝到用户缓冲区域再拷贝到内核缓冲区进行发送。
Netty零拷贝实现
- 使用堆外内存,避免JVM堆内存到堆外内存的数据拷贝
- CompositeByteBuf 类,可以组合多个 Buffer 对象合并成一个逻辑上的对象,避免通过传统内存拷贝的方式将几个 Buffer 合并成一个大的 Buffer。
- 通过 Unpooled.wrappedBuffer 可以将 byte 数组包装成 ByteBuf 对象,包装过程中不会产生内存拷贝。
- ByteBuf.slice ,slice 操作可以将一个 ByteBuf 对象切分成多个 ByteBuf 对象,切分过程中不会产生内存拷贝,底层共享一个 byte 数组的存储空间。
- Netty 使用 封装了transferTo() 方法 FileRegion,可以将文件缓冲区的数据直接传输到目标 Channel,避免内核缓冲区和用户态缓冲区之间的数据拷贝
Java中的IO模型
- BIO java.io是BIO
- NIO java.nio包是NIO的实现,实质上仍然是同步的,读写操作时非同步的,但是这些操作是由应用程序主动发起和处理的,所以仍然是同步的。
- AIO java.nio.channels是NIO的实现
按照定义来说,Netty是一个异步的、事件驱动的、用来做高性能高可靠性的网络应用的框架
Netty相比于Tomcat,不需要遵循Serlet规范,可以最大化的发挥NIO的特性。
如果需要面向TCP的网络应用开发,那么Netty才是最佳选择
三大组件
- Channel & Buffer
- Selector
- Bootstrap
逻辑架构
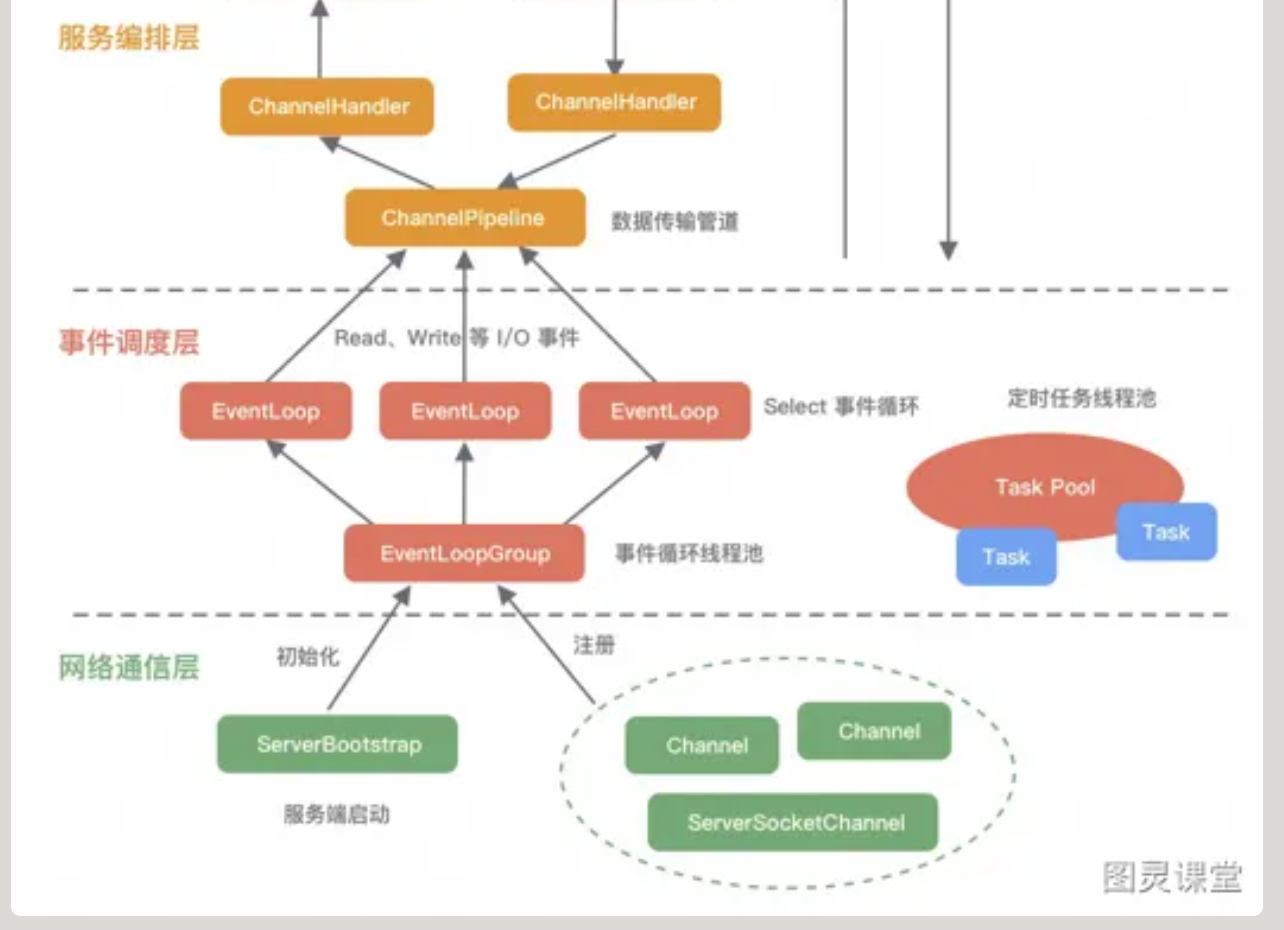
- 网络通信层:支持多种网络协议,当网络数据读取到内核缓冲区后,会触发各种网络事件,会分发给事件调度层进行处理。核心是
- BootStrap,负责Netty客户端的启动、初始化、服务器连接等过程
- ServerBootStrap:用于服务端绑定本地端端口,会绑定Boss和Worker两个EventLoopGroup
- Channle 通道,基于NIO更高层次的抽象吗
- 事件调度层:通过Reactor线程模型对各种事件进行聚合处理。通过Selector主循环线程继承u洞中时间,实际业务处理逻辑是交由服务编排曾中的Handler解决的。
- EventLoopGroup(核心):本质是一个线程池,主要负责接收I/O请求,并分配线程执行处理请求。通过创建不同的EventLoopGroup参数可以支持Reactor三种线程模型:
- 单线程模型:Group中只包含一个EventLoop,Boss和Worker使用同一个Group
- 多线程:多个EventLoop,B和W使用同一个
- 主从多线程:多个EventLoop,B和W使用不同的Group
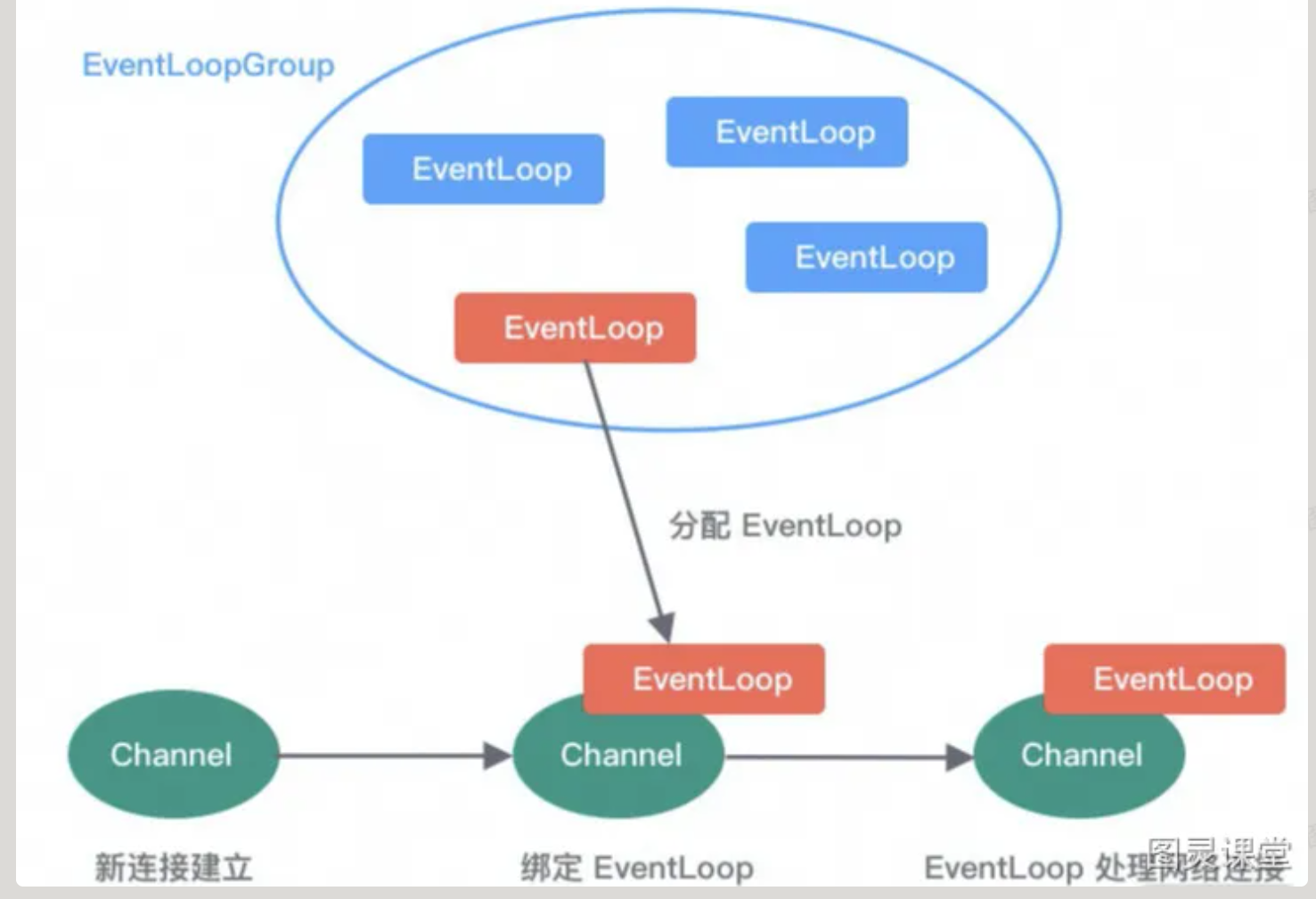
- EventLoop负责处理Channel生命周期中所有的I/O事件,一个EventLoopGroup包含一个或者多个EventLoop,一个EventLoop同一时间只会绑定一个Channel,Channel生命周期内可以和多个EventLoop进行多次绑定和解绑
- EventLoopGroup(核心):本质是一个线程池,主要负责接收I/O请求,并分配线程执行处理请求。通过创建不同的EventLoopGroup参数可以支持Reactor三种线程模型:
- 服务编排层:负责组装各种服务,是核心处理链。
- ChannelPipeline核心编排组件,负责组装各种ChannelHandler,I/O读写触发时,会依次调用Handler进行拦截和处理。
- ChannelHandler完成具体的树decode和encode工作和处理公国。
- ChannelHandlerContext:用于保存上下文,通过HandlerContext可以知道Pipeline和Handler的关联关系,包含Handler生命周期的所有事件。
Bootstrap
Netty客户端的启动
ServerBootStrap
服务端启动,会绑定Boss和 Worker两个EventLoopGroup
Boss线程会不断接受新的连接,然后将连接分给Worker去处理
Channel
常用的Channel实现类
- NioServerSocketChannel 异步 TCP 服务端。
- NioSocketChannel 异步 TCP 客户端。
- OioServerSocketChannel 同步 TCP 服务端。
- OioSocketChannel 同步 TCP 客户端。
- NioDatagramChannel 异步 UDP 连接。
- OioDatagramChannel 同步 UDP 连接。
Channel与事件
- channelRegistered:Channel创建后被注册后被注册
- channelUnregistered:Channel创建后未注册或者从EventLoop取消注册
- channelActive:Channel处于就绪状态,可以被读写
- channelInactive:处于非就绪状态
- channelRead:Channel可以从远端读取数据
- channelReadComplete:Channel读取数据完成
其他
- ChannelFuture
- 其 addListener()方法会注册一个ChannelFutureListener来等待通知
- ChannelHandler:事件处理的具体逻辑
- 生存周期:handlerAddedChannelHandler被添加到ChannelPipeline中时被调用,handlerRemoved被被移除,exceptionCaught处理过程中在ChannelPipeline中有错误产生时。
- ChannelInboundHandler->处理入站数据及状态变化。
- 方法:

- SimpleChannelInboundHandler会自动释放资源
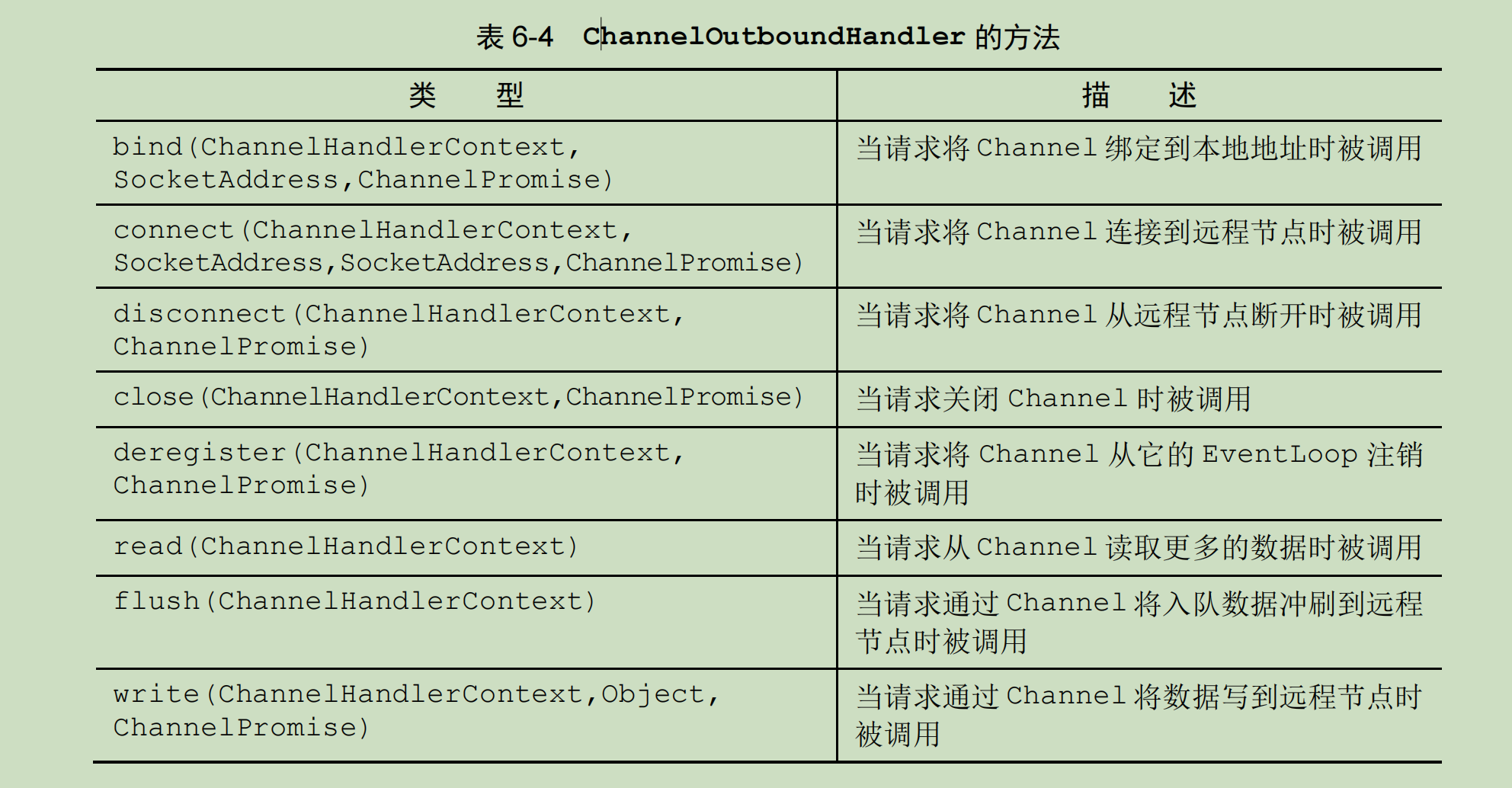
- 方法:
- ChannelPipeline
- 每建立一个新的Channel都会分配一个ChannelPipeline,不可修改
- 提供了 ChannelHandler 链的容器,channel被创建时会被分配到ChannelPipeline中,ChannelHandler会被安装到其中
- 流程: ChannelInitializer的实现被注册进ServerBootstrapy中
- 调用initChannel()方法, ChannelInitializer会在ChannelPipeline中安装一组自定义的ChannelHandler
- ChannelInitializer将自己从 ChannelPipeline中移除
.childHandler(new ChannelInitializer<SocketChannel>() { //添加一个EchoServerHandle到子Channel的ChannelPipeline //ChannelInitializer是一个特殊的处理程序,用于帮助用户配置新的Channel @Override protected void initChannel(SocketChannel socketChannel) throws Exception { //EchoServerHandle被标注为@Shareable,所以我们可以总是使用同样的实例 //@Shareable表示一个ChannelHandler可以被多个Channel安全地共享 //在哪标注的呢?在EchoServerHandle类上 socketChannel.pipeline().addLast(serverHandle); }
- ChannerlHandlerContext接口
- 用于管理关联的ChannelHandler和同一个pipeline中其他的Handler
- 二者的联系和区别:
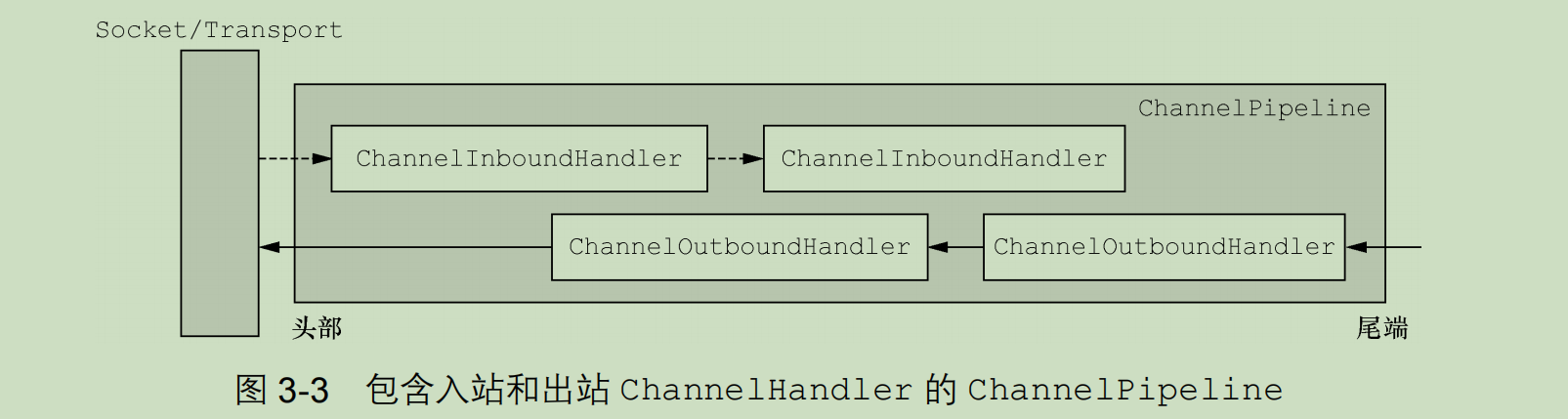
通过使用作为参数传递到每个方法的 ChannelHandlerContext,事件可以被传递给当前ChannelHandler 链中的下一个 ChannelHandler。- ChannelInboundHandler
- SimpleChannelInboundHandler< T > T是要处理消息的Java类型,适用于只需要解码消息并处理逻辑
- channelRead0(ChannelHandlerContext,T)
- BootStrap 引导类,用于为应用程序的网络层配置提供了容器
- Bootstrap 用于客户端 ,可以直接.connect来连接服务器,
- ServerBootstrap 用于客户端,需要.connect(new InetSocketAddress) 才能等待客户端的连接
- Channel接口:
- 方法:

- Channel的生命周期:ChannelUnregistered已创建但是没有注册到EventLoop中;已注册ChannelRegistered;ChannelActive处于活跃状态,已经连接到远程节点, ChannelInactive 没有连接到远程给节点。
- 内置的传输
- NIO 非阻塞->基于选择器
- Epoll -> 基于JNI驱动的,速度更快,完全非阻塞的
- 使用:EpollEventLoopGroup 和EpollServerSocketChannel.class
- OIO ->阻塞流
- Local->在VM内部通过管道进行本地传输
- Embedded 测试ChannelHandler使用
- NIO 非阻塞->基于选择器
- ByteBuf
- 使用两个索引:readIndex和writerIndex,开始时,两个都位于开头。也就是队列
- ByteBufHolder接口用来存储各种属性值。
- Netty提供了两种ByteBufAllocator的实现:PooledByteBufAllocator和UnpooledByteBufAllocator。前者池化了ByteBuf的实例以提高性能并最大限度地减少内存碎片。后者不池化。
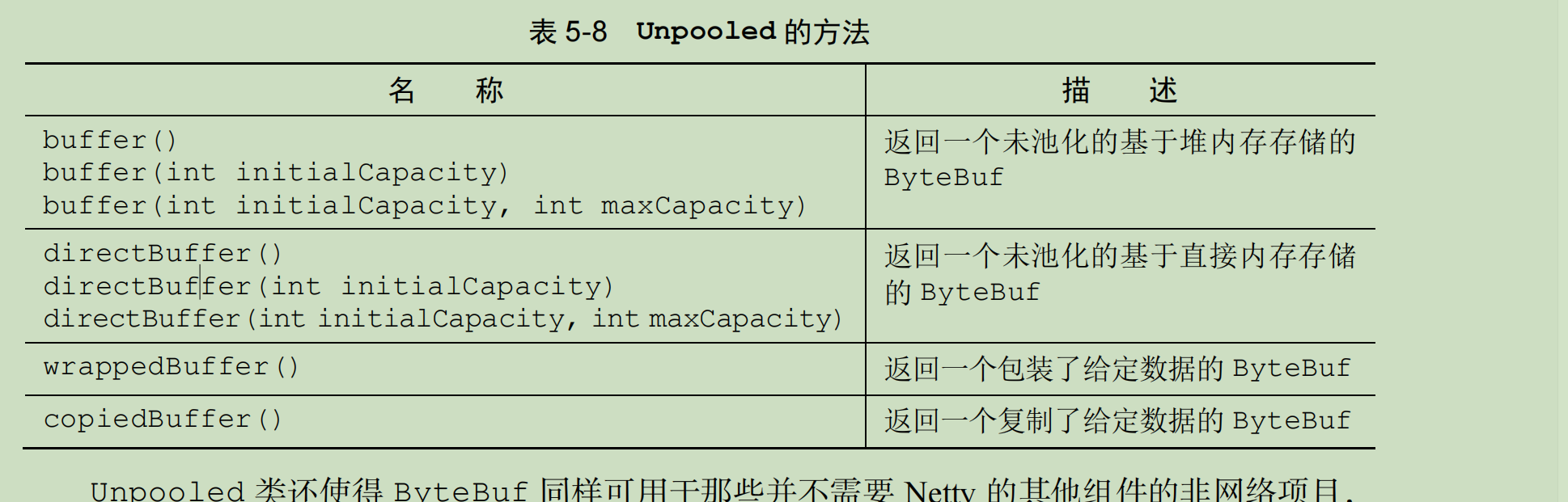
- Unpooled缓冲区:静态工具类来创建未池化的ByteBuf实例
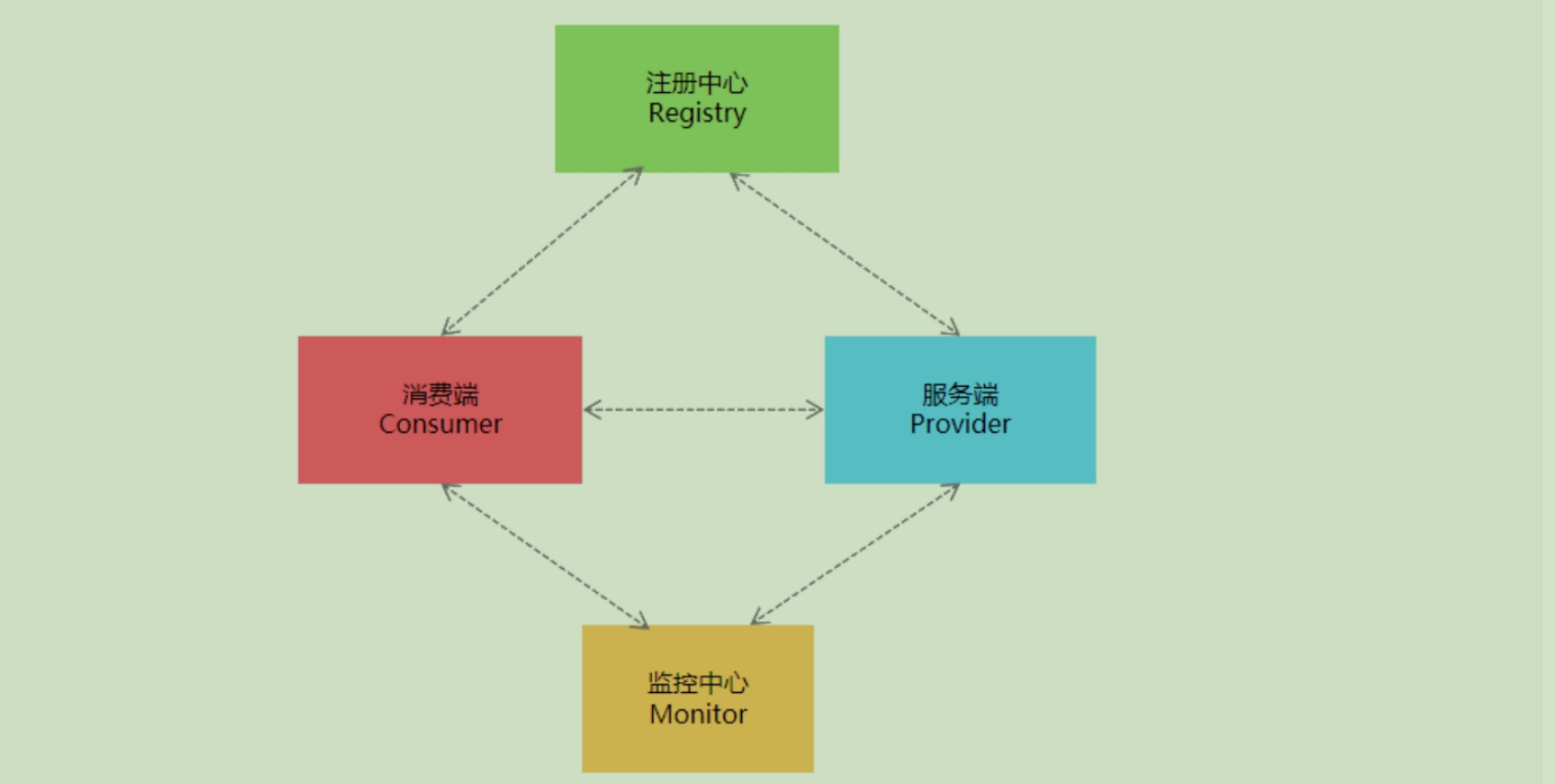
- RPC框架的调用流程
- 解码器:ByteToMessageDecoder 编码器:MessageToByteEncoder实际上这两个实现了Handler
- 协议的支持,自己去看数,Netty实战
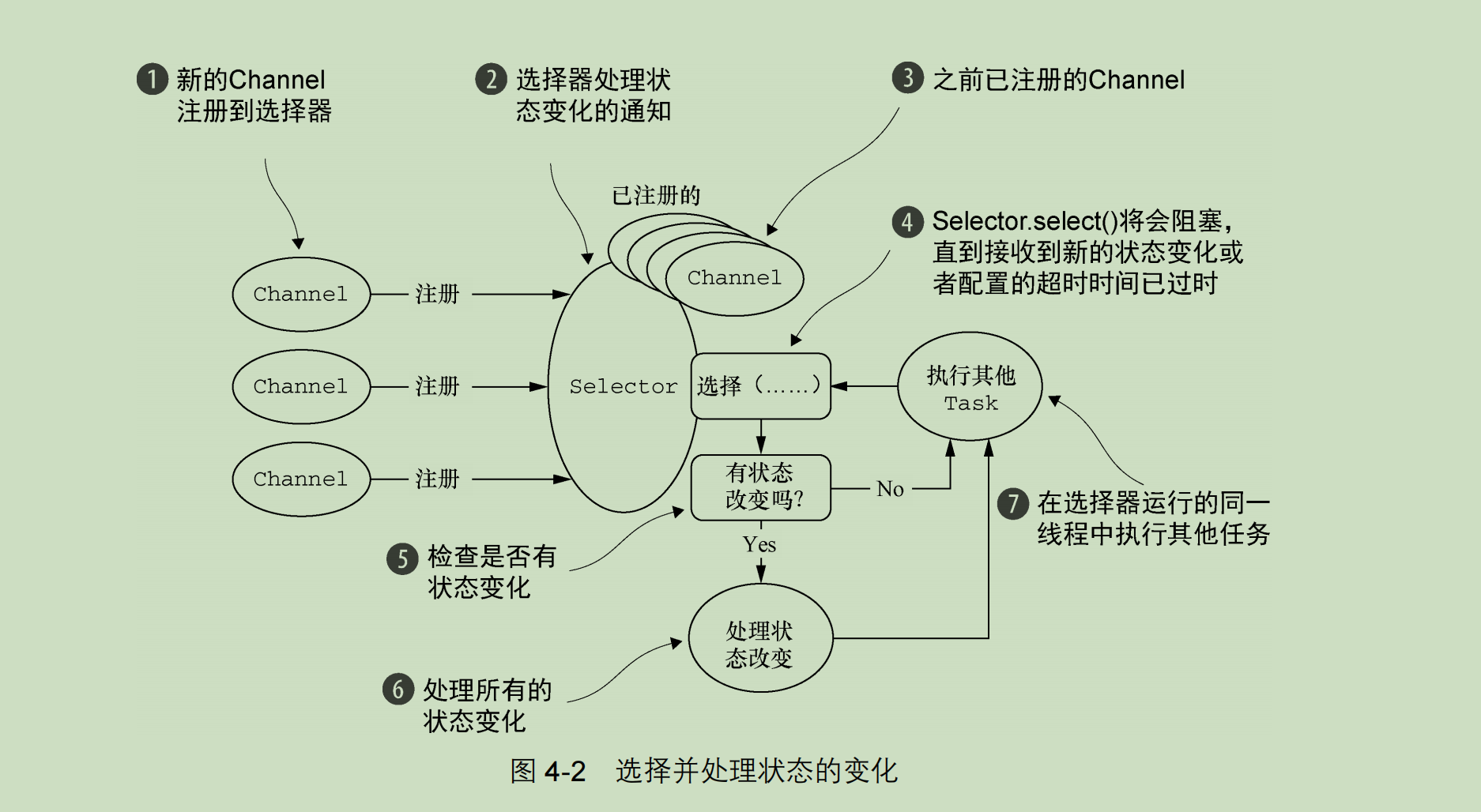
EventLoopGroup 事件调度层
- 如何使用自定义线程池,如何确定线程池的参数
EventLoopGroup是一个线程池,负责接受I/O请求并分配线程执行处理请求。
- EventLoopGroup包含多个EventLoop
- EventLoop用于处理Channel生命周期内的所有I/O事件
- EventLoop同一时间只会与一个线程绑定,每个EventLoop处理多个Channel
- Channel在生命周期内可以对EventLoop进行多次绑定和解绑
服务编排层
- ChannelPipeline
负责组装各种ChannelHandler,内部通过双向链表将不同的ChannelHandler链接起来,依次调用,对Channel中的数据进行拦截和处理。
ChannelPipeline是线程安全的,因为一个新的Channel都会绑定一个新的ChannelPipeline,一个ChannelPipeline关联一个EventLoop,然后一个EventLoop绑定一个线程
- ChannelHandler & ChannelHandlerContext

ChannelHandlerContext用于保存ChannelHanler的上下文,可以实现ChannelHandler之间的交互。
同时包含了ChannelHandler生命周期的所有事件。
使用方式:
#todo
- 如何做,搜搜
如果ChannelHandler有一些通用的逻辑需要实现,那么就可以放在这里。
Selector
Netty实现的一些有特色
FastThreadLocal
使用Object数组替代Entry数据,Object[0]存储的是一个Set<FastThreadLocal<?>>集合,1以后都是存value的数据,而不是使用键值对的方式实现。
set方法:
- 找到index位置,设置新的value
- 将FastThreadLocal对象保存到待清理的Set中
优点: - 高效查找:可以直接通过数组下标获取,而且扩容不需要进行rehash
- 安全性更高:ThreadLocal有可能会造成内存泄漏,只能等待线程销毁,但是的线程池下只能主动检测,而FastThreadLocal则封装了FastThreadLocalRunnable,任务执行完成之后一定会执行
FastThreadLocal.removeAll(),从而将Set中所有的对象都销毁。
#todo
- 以下内容是新开的文章《深入浅出Netty:原理与源码解读》记得新开一篇文章
- 看看能不能写个爬虫把这个文章爬下来,或者自己复制下来
曹工杂谈:Spring boot应用,自己动手用Netty替换底层Tomcat容器 - 三国梦回 - 博客园 (cnblogs.com)
00 学好 Netty,是你修炼 Java 内功的必经之路 (lianglianglee.com)
深入和源码解读
线程模型
单线程模型
所有的I/O操作都由一个线程完成,会造成积压
多线程模型
业务逻辑交给多个线程进行处理
主从多线程模型
MainReactor负责处理客户端的连接,SubReactor分配线程池中的线程处理连接生命周期内的所有的I/O模型
Netty内部的逻辑流程

mybatis
面试常问:
- 延迟加载提高加载效率:
Mybatis的缓存
- 一级缓存:也即是本地缓存,是SqlSession级别的,读个sql语句之间不会共享缓存,使用@Transactional来生效,也就是说在一次事务中多次查询会使用到一级缓存
- 默认开启,可以在配置中关闭
- 当我们执行查询操作时,MyBatis会先去一级缓存中查找是否有之前查询过的数据。如果有,直接返回缓存中的数据;如果没有,去数据库查询数据,并将查询结果放入一级缓存中。
- 当我们执行更新操作(包括insert、update、delete)时,MyBatis会清空一级缓存。这是为了保证缓存中的数据和数据库中的数据是一致的。
- 当SqlSession结束或关闭时,一级缓存也就清空了。
- 二级缓存:
- 在mapper.xml上方加上
<Cache></Cache>即可 - 根据mapper.xml中命名空间来区分,是mapper级别的,只用当执行同一个mapper中的增改删语句时才会失效,增删改频繁时二级缓存基本失效,并且,微服务中多台服务中只有被调用的那一台的二级缓存才会删除,其余的不删除,造成不一致。
- 在mapper.xml上方加上
- 默认开启,可以在配置中关闭
- Springboot Cache,会缓存方法的返回值,但是同样也只能在一个节点生效,并且,@Cacheable不会主动刷新缓存,但是@CachePut会强制刷新缓存,并把新的缓存放入
- 共享的缓存!Redis 可以在配置文件中将springboot的缓存类型设置为Redis
#{} 和 ${} 的区别是什么?
#{}是Propeties文件中的变量占位符,会被原样替换${}是sql的参数占位符,Mybatis会把他替换成?后续通过反射进行替换数据
xml 映射文件中,除了常见的 select、insert、update、delete 标签之外,还有哪些标签?
resultMap 定义查询结果的映射规则
<resultMap id="userResultMap" type="User">
<id property="id" column="user_id" />
<result property="username" column="user_name" />
<result property="password" column="user_password" />
<result property="email" column="user_email" />
<result property="bio" column="user_bio" />
</resultMap>sql:定义可复用的SQL代码段
<sql id="userColumns"> ${alias}.id, ${alias}.username, ${alias}.password, ${alias}.email, ${alias}.bio </sql>
<select id="selectUsers" resultMap="userResultMap" >
select
<include refid="userColumns"><property name="alias" value="user"/></include>
from some_table user
</select>parameterType 定义SQL语句的输入参数类型
<insert id="insertUser" parameterType="User">
insert into users (username, password, email, bio)
values (#{username}, #{password}, #{email}, #{bio})
</insert>resultType:定义 SQL 语句的输出结果类型。
<select id="selectUsernames" resultType="string">
select username from users
</select>association:定义一对一的关联关系。
<resultMap id="userResultMap" type="User">
<!-- ... -->
<association property="address" javaType="Address">
<id property="id" column="address_id" />
<result property="street" column="address_street" />
<result property="city" column="address_city" />
<result property="state" column="address_state" />
<result property="zip" column="address_zip" />
<result property="country" column="address_country" />
</association>
</resultMap>collection:定义一对多的关联关系。
<resultMap id="userResultMap" type="User">
<!-- ... -->
<collection property="posts" ofType="Post">
<id property="id" column="post_id" />
<result property="subject" column="post_subject" />
<result property="body" column="post_body" />
</collection>
</resultMap>dynamic 标签如 if、choose、when、otherwise、trim、where、set:用于构建动态 SQL。
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG WHERE state = 'ACTIVE'
<if test="title != null">
AND title like #{title}
</if>
</select>- 执行过程
- java程序加载config文件,创建SqlSessionFactory对象,之后通过SqlSessionFactory创建SqlSession对象,之后通过SqlSession对象执行映射配置文件中定义的SQL语句,最后通过SqlSession对象提交事务,关闭SqlSession对象

Dao接口(Mapper接口)的原理
Dao中的方法,参数不同时,可以重载吗
Mapper中的方法可以 重载,使用的是全限定名 + 方法名 拼接的字符串作为key去匹配。 但是xml文件中的id只能指定一个,也即是重载的所有方法都是用一个sql语句,而这个sql语句我们可以使用动态sql来实现
<select id="getAllStu" resultType="com.pojo.Student">
select * from student
<where>
<if test="id != null">
id = #{id}
</if>
</where>
</select>
Dao接口的原理:
MyBatis运行时会使用JDK动态代理来为Dao生成代理proxy对象,代理对象会拦截接口方法,转而执行MappedStatement中的sql
MyBatis的分页
nihao
原理
答:**(1)** MyBatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页;**(2)** 可以在 sql 内直接书写带有物理分页的参数来完成物理分页功能,**(3)** 也可以使用分页插件来完成物理分页。
分页插件的原理
- 插件设置一个ThreadLocal变量来存储分页参数
- 当执行查询时,MyBatis会调用所有注册的拦截器。
- PageHelper 首先会保存原始的查询SQL,然后生成一个新的SQL,这个新的SQL在原始的SQL基础上添加了LIMIT和OFFSET
- PageHelper 将新的SQL替换成原始的SQL然后执行
- 最后PageHelper会清除ThreadLocal中变量,避免内存泄漏
MyBatis动态sql是什么的,有哪些,原理
常用的动态sql标签
<if></if><where></where>(trim,set)<choose></choose>(when, otherwise)<foreach></foreach><bind/>
执行原理
OGNL (Object-Graph Navigation Language)表达式,通过他可以在XML配置文件中引用Java对象和方法,在动态SQL中,常常使用其进行判断条件
- 常见的OGNL语法:
person.name #访问对象的属性 person.getName() # 调用对象的方法 persons.{name} # 获取persons对象的name属性 person.age > 18 ? 'adult' : 'child' # 条件表达式 person.agge + 1 # 算术表达式 person.age > 18 && person.gender == 'male' # 逻辑表达式
MyBatis如何将sql执行结果封装为目标对象并返回
- 使用
<resultMap>标签去映射列表名和对象属性名之间的映射关系 - 使用sql列别名方式,将列名书写为对象属性名,例如:T_NAME AS NAME 对应的属性名是name,会忽略大小写
当映射关系建立之后,MyBatis会通过反射创建对象,然后给对象的属性一一赋值
MyBatis延迟加载的原理 待写
MyBatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的是1v1,collection是1v多
Executor执行器
- SimpleExecutor 每执行一次 update或select,就开启一个Statement对象,用完立刻关闭Statement对象
- ReuseExecutor 执行update/select 以sql为key查找Statement对象,不存在就创建,使用后放在Map中,供下一次使用
- BatchExecutor 执行update 时,将所有的sql都添加到批处理中,之后统一执行,缓存多个Statement对象,每个Statement对象都是等待sql添加之后,等待逐一执行
深入解读
基础支持层
- 解析器模块
- DOM解析将xml的标签组织成一颗DOM树,将整个xml文档加载进内存
- SAX基于时间模型的xml解析方式。加载一部分到内存中,并且当程序处理过程中满足条件时,会结束解析,不必解析剩余的xml内容。但是不支持层次关系和父子关系的保存
- XPathParser:MyBatis提供的XPathParser类封装了XPath、Document、EntityResolver
MyBatis Plus
一些插件
自定义填充字段
@Component
public class MyBatisPlusDateHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
this.setFieldValByName("createTime", LocalDateTime.now(), metaObject);
this.setFieldValByName("updateTime", LocalDateTime.now(), metaObject);
}
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName("updateTime", LocalDateTime.now(), metaObject);
}
}
分页插件
@Configuration(value = "dataBaseConfigurationByAdmin")
public class DataBaseConfiguration {
/**
* 分页插件
*/
@Bean
@ConditionalOnMissingBean
public MybatisPlusInterceptor mybatisPlusInterceptorByAdmin() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}使用时,只需要在自己定义的方法上加上一个Page类型的变量就可以进行分页查询了
Page<User> page = new Page<>(1, 10); // 第1页,每页10条记录
List<User> users = userService.selectUsers(page);SpringSecurity和其他的认证相关
Security
RBAC模型: Role-Based Access Control 基于角色的权限控制访问控制,角色关联权限,角色又关联用户的授权方式
一个用户可以有多个角色,每一个角色又可以分配多个权限
AuthenticationProvider是AuthenticationManager的一个组成部分,它负责处理特定类型的Authentication对象。AuthenticationManager可能会有多个AuthenticationProvider,每个AuthenticationProvider都会尝试验证传入的Authentication对象。
使用流程:
- controller
- 配置拦截器/Filter,继承OncePerRequestFilter,验证token
- 配置security,在这里可以指定自定义的provider
@Configuration @EnableWebSecurity public class WebSecurityConfig { @Bean public AuthenticationManager authenticationManager(AuthenticationConfiguration authConfig) throws Exception { return authConfig.getAuthenticationManager(); } //我们自定义的拦截器 @Bean public JwtAuthenticationTokenFilter jwtAuthenticationTokenFilter() { return new JwtAuthenticationTokenFilter(); } @Bean public SecurityFilterChain filterChain(HttpSecurity httpSecurity) throws Exception { //基于token,所以不需要csrf防护 httpSecurity.csrf().disable() //基于token,所以不需要session .sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS) .and() .authorizeRequests() //登录注册不需要认证 .antMatchers("/user/login", "/user/register").permitAll() //除上面的所有请求全部需要鉴权认证 .anyRequest() .authenticated(); //禁用缓存 httpSecurity.headers().cacheControl(); //将我们的JWT filter添加到UsernamePasswordAuthenticationFilter前面,因为这个Filter是authentication开始的filter,我们要早于它 httpSecurity.addFilterBefore(jwtAuthenticationTokenFilter(), UsernamePasswordAuthenticationFilter.class); return httpSecurity.build(); } }
认证相关的概念和原理
Cookie被禁用了Session还能使用吗
可以使用,可以把SessionID放在请求路径中,同时可以对SessionID进行加密
为什么Cookie无法防止CSRF攻击,而Token可以
CSRF(Cross Site Request Forgery) 跨站请求伪造,Token存在localStorage浏览器本地缓存,然后每次发送请求携带这个即可。而Cookie是可以被别的获取的
XSS 跨站脚本攻击(Cross Site Scripting)
JWT
格式
xxxxx.yyyyy.zzzz
HEADER
描述JWT的元数据,定义了生成签名的算法以及Token的类型
- typ(Type) :令牌类型,也就是JWT
- alg(Algorithm) :签名算法
PAYLOAD
存放实际要传输的数据,包含Claims(声明,包含JWT的相关信息)
- 注册声明:预定义的一些声明
- 公有声明:JWT签发方可以自定义的声明
- 私有声明:签发方因为项目中需要而自定义的声明
SIGNATURE (签名)
通过Payload和Header和Secret是哟个Header中指定的签名算法
用于防止JWT被篡改
这个签名的生成需要用到:
- Header + Payload。
- 存放在服务端的密钥(一定不要泄露出去)。
- 签名算法。
基本概念
SSO 单点登录
OAuth 2.0
权限设计
RBAC
基于角色的权限控制
ABAC
基于属性的控制访问
TVM
6.S081
OS
系统调用跳到内核与标准的函数调用跳到另一个函数相比,区别是什么?
Kernel的代码总是有特殊的权限。当机器启动Kernel时,Kernel会有特殊的权限能直接访问各种各样的硬件,例如磁盘。而普通的用户程序是没有办法直接访问这些硬件的。所以,当你执行一个普通的函数调用时,你所调用的函数并没有对于硬件的特殊权限。然而,如果你触发系统调用到内核中,内核中的具体实现会具有这些特殊的权限,这样就能修改敏感的和被保护的硬件资源,比如访问硬件磁盘。我们之后会介绍更多有关的细节。
Kernel
内核使用CPU提供的硬件保护机制来确保每个在用户空间执行的进程只能访问它自己的内存。内核程序的执行拥有操控硬件的权限,它需要实现这些保护;而用户程序执行时没有这些特权。当用户程序调用系统调用时,硬件会提升权限级别,并开始执行内核中预先安排好的函数。
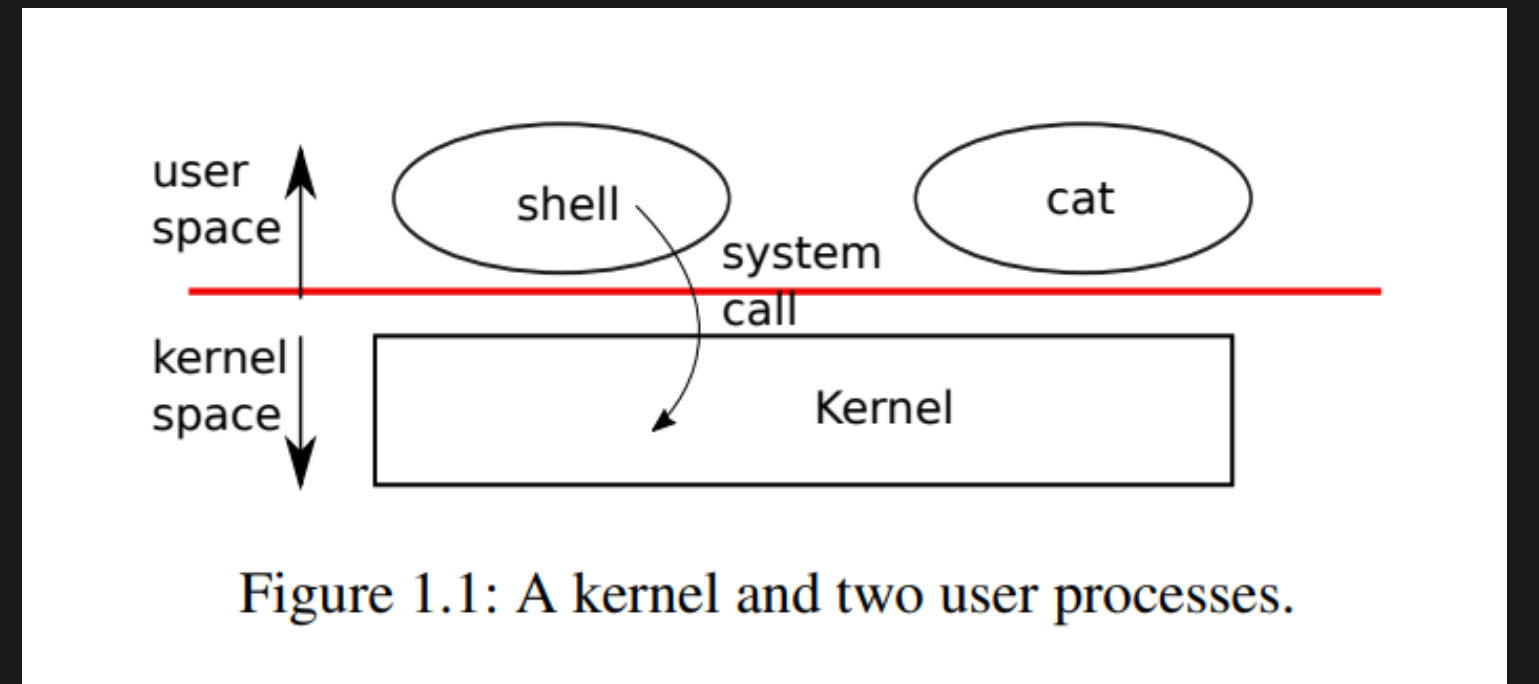
xv6提供的系统调用
看文档Shell 是一个普通的进程,是一个用户程序,用户使用Shell来与系统调用进行交互
进程
- 进程由 用户空间内存(指令、数据和堆栈)和对内核私有的每个进程状态组成
- Xv6 采用分时进程,等待执行中的进程集合切换可用的CPU,当进程没有执行时,xv6会保存他的CPU寄存器,并在下一次运行时恢复,使用进程id或PID标示进程、
I/O
- 文件描述符是一个小整数(small integer),表示进程可以读取或写入的由内核管理的对象
- 进程从文件描述符0读取(标准输入),将输出写入文件描述符1(标准输出),并将错误消息写入文件描述符2(标准错误)。
- 管道:作为一对文件描述符公开给进程的小型内核缓冲区,一个用于读取,一个用于写入。将数据写入管道的一端使得这些数据可以从管道的另一端读取。管道为进程提供了一种通信方式。
首先,管道会自动清理自己;在文件重定向时,shell使用完
/tmp/xyz后必须小心删除其次,管道可以任意传递长的数据流,而文件重定向需要磁盘上足够的空闲空间来存储所有的数据。
第三,管道允许并行执行管道阶段,而文件方法要求第一个程序在第二个程序启动之前完成。
第四,如果实现进程间通讯,管道的阻塞式读写比文件的非阻塞语义更高效。
操作系统架构
操作系统必须满足三个要求:多路复用、隔离和交互。
- 隔离:禁止应用程序直接访问敏感的硬件资源,将资源抽象成服务。提供系统调用
- 用户想要执行内核函数必须由用户模式过渡到管理模式
- 整个操作系统都驻留在内核中,这样所有系统调用的实现都以管理模式运行。这种组织被称为宏内核(monolithic kernel)。
- 缺点是操作系统不同部分之间的接口通常很复杂(正如我们将在本文的其余部分中看到的),因此操作系统开发人员很容易犯错误。在宏内核中,一个错误就可能是致命的,因为管理模式中的错误经常会导致内核失败。如果内核失败,计算机停止工作,因此所有应用程序也会失败。计算机必须重启才能再次使用。
- 微内核
- 操作系统设计者可以最大限度地减少在管理模式下运行的操作系统代码量,并在用户模式下执行大部分操作系统。这种内核组织被称为微内核(microkernel)
- 文件系统作为用户级进程运行。作为进程运行的操作系统服务被称为服务器。为了允许应用程序与文件服务器交互,内核提供了允许从一个用户态进程向另一个用户态进程发送消息的进程间通信机制。
- 进程
- 进程抽象给程序提供了一种错觉,即它有自己的专用机器。进程为程序提供了一个看起来像是私有内存系统或地址空间的东西,其他进程不能读取或写入。
- 启动过程: 初始化自己并运行一个存储在只读内存中的引导加载程序。引导加载程序将xv6内核加载到内存中。然后,在机器模式下,中央处理器从
_entry(kernel/entry.S:6)开始运行xv6。Xv6启动时页式硬件(paging hardware)处于禁用模式:也就是说虚拟地址将直接映射到物理地址。
页表
页表是操作系统为每个进程提供私有地址空间和内存的机制。页表决定了内存地址的含义,以及物理内存的哪些部分可以访问。
Lab
lab1
推荐使用2021版的官方教程,2020的我打开不了
不建议在root用户下进行
sleep (easy)
实现xv6的UNIX程序sleep:您的sleep应该暂停到用户指定的计时数。一个滴答(tick)是由xv6内核定义的时间概念,即来自定时器芯片的两个中断之间的时间。您的解决方案应该在文件user/sleep.c中
思路:先查看系统调用的代码
- 引入头文件,即
kernel/types.h声明类型的头文件和user/user.h声明系统调用函数和ulib.c中函数的头文件。 - 编写
main(int argc,char* argv[])函数。其中,参数argc是命令行总参数的个数,参数argv[]是argc个参数,其中第 0 个参数是程序的全名,其他的参数是命令行后面跟的用户输入的参数。 - 在Makefile中加入$U/_sleep
参考答案:
Makefile://引入type定义和系统调用文件 #include "kernel/types.h" #include "user/user.h" //编写main函数 //argc 是shell接受的参数个数,argv指向对应的参数 //argv[0] 始终指向函数的全名 int main(int argc, char **argv) { //shell 中应该输入 sleep +参数,所以只接受一个参数, argc 应为 2 if(argc != 2) { //write(int fd ,char *buf, int n) // fd是文件描述符 0 是标准输入,1标准输出,2是标准错误 //buf 存放要写入写出的字符数组 // n 是要传输的字节数 write(2,"Usage: sleep time\n", strlen("Usage: sleep time\n")); //exit(status) 0 标示正常退出,非0藐视错误退出 exit(1); } //使用atoi来转为int型 sleep(atoi(argv[1])); exit(0); }
单元测试:UPROGS=\ $U/_cat\ $U/_echo\ $U/_forktest\ $U/_grep\ $U/_init\ $U/_kill\ $U/_ln\ $U/_ls\ $U/_mkdir\ $U/_rm\ $U/_sh\ $U/_stressfs\ $U/_usertests\ $U/_grind\ $U/_wc\ $U/_zombie\ $U/_sleep\ # 这是我们要写的 - make qemu 之后在shell中 sleep 100 看看是否停顿, 如果make qemu 报错,可能是没有 自动编译,建议重新启动
- 不启动xv6,在xv6-labs-2021 路径下使用: ./grade-lab-util sleep —-sleep可替换为其他待测的,也可以不加,直接把全部实验代码都进行测,权限不够自己sudo, 报错了可能没安装python3
pingpong (Easy)
编写一个使用UNIX系统调用的程序来在两个进程之间“ping-pong”一个字节,请使用两个管道,每个方向一个。父进程应该向子进程发送一个字节;子进程应该打印“
<pid>: received ping”,其中<pid>是进程ID,并在管道中写入字节发送给父进程,然后退出;父级应该从读取从子进程而来的字节,打印“<pid>: received pong”,然后退出。您的解决方案应该在文件_user/pingpong.c_中。
思路:
- 使用pipe来建立管道
- fork来建立子进程并用来区分父进程和子进程
- getpid来获取进程pid
- read 和 write来进行读写
- Makefile
// pingpong.c #include "kernel/types.h" #include "user/user.h" #include "stddef.h" // int main(int argc, char **argv) { // argc是输入的参数个数,argv指向对应的参数 //定义两个pipe int pp2c[2],pc2p[2]; // p parent to child //p[0] 是文件描述符0, 0 是输入端,1是输出端 pipe(pp2c); //父进程 -> 子进程 pipe(pc2p); //使用fork来判断子进程和父进程 if(fork() != 0 ) { //父进程 //write(文件描述符,指针,字节数) write(pp2c[1],"!",1); //父进程向子进程发出一个字节 char buf ; //待读入缓冲区,用于存储 read(pc2p[0],&buf,1); printf("%d: received pong\n",getpid()); wait(0); } else { char buf; //从父进程读入 read(pp2c[0],&buf,1); printf("%d: received ping\n",getpid()); //子进程重新发送给父进程 write(pc2p[1],&buf,1); } exit(0); }
prime
思路:使用筛法,每次输出一个素数之后,把这个素数的倍数删除,之后再重新写入pipe中供下一个子进程使用即可。注意回收文件描述符即可
注意: 一定要使用子进程 ,不使用子进程会导致阻塞致死
#include "kernel/types.h"
#include "user/user.h"
#include "stddef.h" // 为了得到NULL
//将描述符重新定向
void mapping(int n , int pd[]) {
close(n);
//dup会返回一个最小的未使用的文件描述符,然后我们close
//了n,也就是会返回n,之后会将这个描述符指向pd[n]所指向的文件
dup(pd[n]);
//再关闭pd 就实现了将pd[n] 重定向到n的操作
close(pd[0]);
close(pd[1]);
}
void primes() {
//开始读入数据
int current,next; //current来保存现在的数
int fd[2];
// 从0中读取数据,并写入current,读取字节长度为sizeof(int)
if(read(0,¤t,sizeof(int))) {
printf("prime %d\n",current);
pipe(fd);
//开始筛选,每经历一个子进程就drop一些数据
if(fork() == 0) {
mapping(1,fd);//定向到写入端
//重复从1中读入,判断是否是current的倍数
while(read(0,&next,sizeof(int))) {
if(next % current != 0) {
write(1,&next,sizeof(int));
}
}
} else {
wait(NULL); //等待子进程结束
//反复调用即可
mapping(0,fd);
primes();
}
}
}
//0用来读取, 1用来写入
int main(int argc, char **argv) {
int fd[2]; //文件描述符
//fd是共用的
pipe(fd); //fd[0]是读入端,也就是从pipe中读取字节,fd[1]是写入端,可以向pipe中写入
if(fork() == 0) {
//子进程写入 2 - 35
mapping(1,fd);//将标准输出指向fd的写入端,也就是将输指向写入端
for(int i = 2; i <= 35; i ++) {
//write 是向标准输出写入东西,标准输出已经指向fd[1]了,也就是向fd写入数据
write(1,&i,sizeof(int));
}
} else {
wait(NULL);//等待子进程写完
/**
* 当调用 wait(NULL) 时,父进程会被阻塞,直到任意一个子进程终止。一旦子进程终止,wait(NULL) 函数会返回被终止的子进程的进程 ID(PID),并且如果提供了 status 参数,
* 子进程的退出状态会存储在 status 中。
*/
mapping(0,fd);//将标准输入指向fd来进行读入
primes();
}
exit(0);
}
os
OS面试常问
编码问题
ASCII码规定了128个字符的编码
Unicode 是⼀个很⼤的集合,将世界上所有的符号都纳⼊其中,每⼀个符号都给予⼀个独⼀⽆⼆的编
码。可以容纳100多万个符号;但是存储⽅式不确定,还可能浪费字节空间
Unicode 是⼀个很⼤的集合,将世界上所有的符号都纳⼊其中,每⼀个符号都给予⼀个独⼀⽆⼆的编
码。可以容纳100多万个符号;但是存储⽅式不确定,还可能浪费字节空间
utf-8中中文占几个字节
- 对于单字节,字节的第一位设为0,后面7位位Unicode码,英语字母,UTF-8与ASCII是一样的
- 对于n字节的符号,第一个字节前n位全是1,第n+1位为0,后面字节的前两位为10,剩下的为Unicode码。中文占用三个字节的存储空间。
进程与线程
不同进程的线程间要进行通信需要使用消息通信的方法来实现同步。
线程同步机制
- 互斥锁Mutex:保证同意时间只能有一个线程可以访问共享资源。
- 信号量Semaphore:一种计数器,控制同时访问某个共享资源的线程数量。
- 条件变量Confition Variable:一个线程可以等待某个条件的发生,另一个进程可以在满足条件时,通知等待的线程继续执行。
- 读写Read-Write Lock:允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。
- 原子操作:
- 屏障Barrier:让一组下称在某个点上等待,直到所有进程都到达这个点之后再继续执行。
死锁
四个条件:互斥、请求和保持、不剥夺、环路等待
死锁预防:破坏任一条件
死锁避免:银行家算法、一次封锁法、顺序封锁法
一次封锁法是一种简单的锁定策略,事务在开始时一次性获取所有需要的锁,并在事务结束时一次性释放所有锁。这种方法可以避免死锁,但可能会导致锁的持有时间过长,从而降低系统的并发性能。
顺序封锁法是一种更复杂但更有效的锁定策略,分为两个阶段:扩展阶段和收缩阶段。
- 扩展阶段(Growing Phase):事务可以获取锁,但不能释放锁。
- 收缩阶段(Shrinking Phase):事务可以释放锁,但不能获取新的锁。
这种方法可以确保事务的可串行化,从而保证数据的一致性。
原子操作
如何实现
基于缓存加锁和总线加锁。
总线锁是使用处理器提供的一个lock#信号,当一个处理器在总线上输出这个信号,其他处理器的请求被阻塞。总线吧cpu贺内存之间的通信锁住了,其他处理器不能操作其他内存地址的数据,所以开销很大
缓存锁:频繁使用的内存会在L1、L2、L3高速缓存中,所以原子操作只需要对内部缓存中进行,允许使用MESI缓存一致性机制来保证原子性。
但是以下情况不能使用缓存锁:
- 操作的数据不能被缓存在处理器内部或者操作的数据跨多个缓存行
- 有些处理器不支持缓存锁定
锁的区别和使用场景
互斥锁mutex
特点是任何时刻都只有一个线程可以访问某个资源或者临界区
使用场景:共享资源不能被多个线程同时修改,更新全局变量、修改数据库记录
信号量 Semaphore
控制特定资源的访问线程数
场景:限制链接池大小,控制同时访问文件的线程数
临界区 Critical Section
代码中访问共享资源的部分,保证同时只有一个线程可以执行这段代码
场景:执行多步骤的事务
循环锁 Spinlock
一种忙等待锁,反复检查锁的状态,不会让出CPU资源
场景:时间很短,持有锁时间很短。
读写锁
- 读者优先:读线程可以一直,所有的读线程都释放锁后,写线程才能获得写锁。
- 写着优先:第一个读线程获得锁之后,当写线程到达会被阻塞,但是阻塞过程中新的读线程要排在写线程之后。
- 公平策略:使用队列,读写按照先进先出原则加锁。
内存管理
- 栈:由操作系统自动分配释放,存放函数的参数值,局部变量等
- 堆:一般由程序员分配释放,程序员不释放,程序结束时可能由OS回收,分配方式类似链表
虚拟内存 Virt
抽象层,允许操作系统将硬件内存抽象化,使得每个程序都认为自己有一个连续的、私有的内存区域。内存满了也可以通过swap文件或者分页将部分数据暂存到硬盘上,从而使得程序可以运行在超过物理内存大小的内存空间中。大小 = 程序正在使用的物理内存 + 交换空间 + 未使用但已预留的内存。
常驻内存RES
实际被加载到物理内存中的部分
共享内存 SHR
多个进程共同使用的内存部分,允许不同进程访问同一块物理地址,从而节省内存小号并提高数据交换效率。共享内存常用于进程间通信IPC
Free 内存
系统中完全未使用的内存数量,是系统中真正可用的,没有被其他进程使用的内存。
Available内存
系统中立刻可以分配给进程的内存数量,包括free内存和一部分被缓存的内存。available = free + buff/chche
Buffer
缓冲区适用于存储文件系统元数据的内存。读取/写入文件时,数据首先暂存在Buffers中,来提高读取和写入的效率。
Cached
缓存:用于存储已经从磁盘读取的文件的副本,这些文件可能是系统频繁使用的文件。由Linux内核自动管理,用于提高系统性能。系统有足够的空闲内存时,会将一些文件的副本保留在Cached中。
内存回收
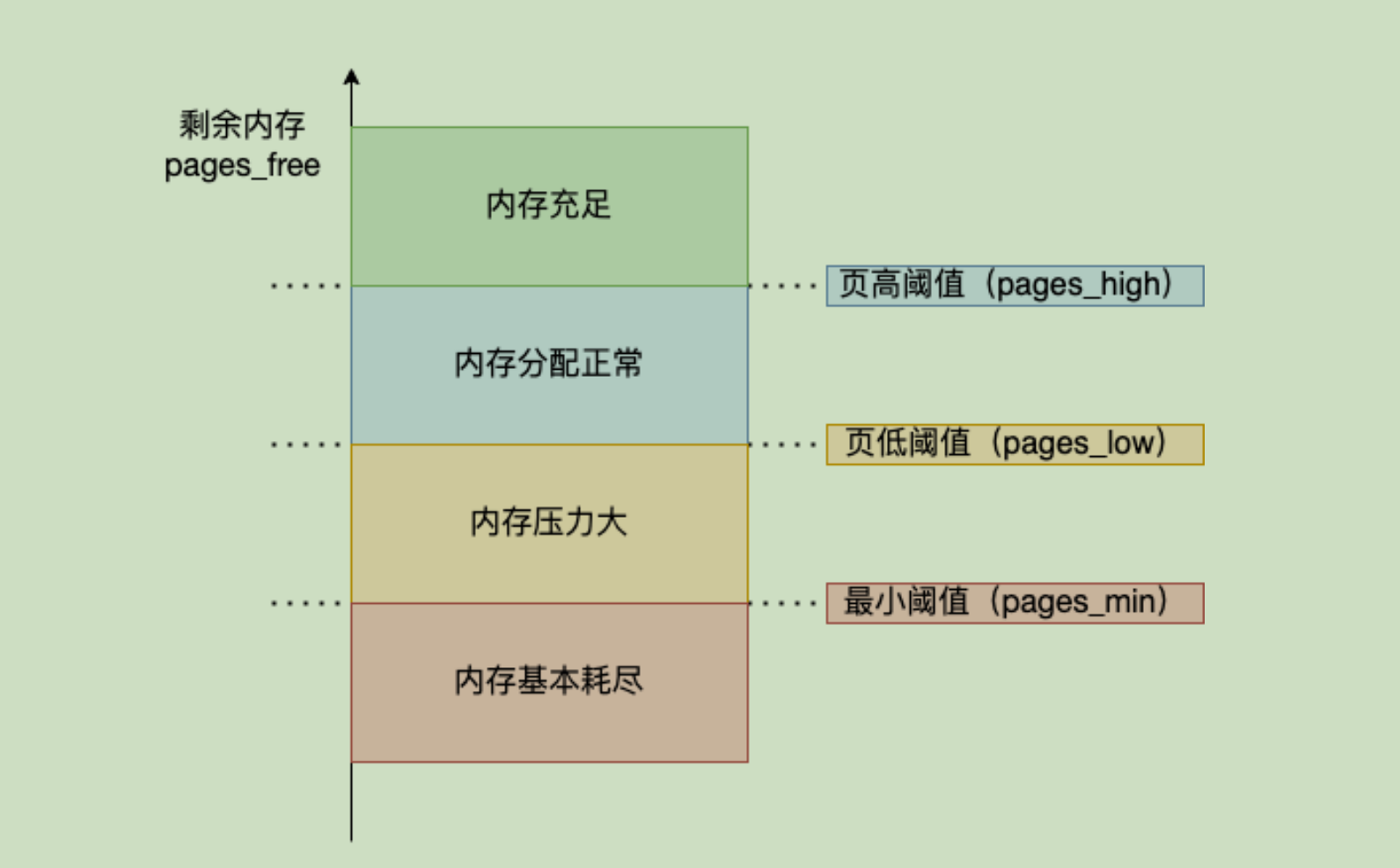
当内存大于pages_high是,系统内存充足不会进行内存回收
当内存小于pages_low时,标识内存存在压力,会触发kswapd0,进行后台内存回收。直到pages_high位置
当内存⼩于 pages_min 时,表⽰此时⽤⼾内存耗尽,会触发直接内存回收,进程被阻塞
OOM⸺Out of Memory 如果直接内存回收之后,系统的剩余空闲内存还不⾜以进⾏内存分配,则会
进⼀步触发OOM机制。 OOM Killer 机制会根据算法选择并kill掉⼀个占⽤物理内存较⾼的进程,以便
释放内存资源,如果物理内存依然不⾜,OOM Killer 会继续杀死占⽤物理内存较⾼的进程,直到释放
⾜够的内存位置。
MMU和TLB
MMU (Memory Management Unit,内存管理单元)
用于在CPU和内存之间实现虚拟内存管理。将虚拟地址转换为物理地址,同时提供访问权限的控制和缓存管理等功能。
TLB 是高所缓存,哟关于缓存页表转换的结果。存在TLB时,虚拟地址到物理地址的转换过程发生了变化,虚拟地址首先发往TLB确认是否命中Cache
Drop Cache
“Drop Cache” 是一种清理系统缓存的方法。系统缓存包括页面缓存、目录项缓存(dentry cache)和inode缓存。
• dirty pages不能回收;
• 共享内存和tmpfs(临时⽂件系统,指位于内存和/或交换分区中的⽂件系统)不能回收(注意观察
free命令显⽰的shared值);
Buddy分配器 & Slab分配器
Buddy系统是⼀种⾼效的内存分配技术,因为它避免了内存空间的碎⽚。伙伴系统确保所有分配的块
具有相同的⼤⼩,以便它们可以轻松地与其伙伴块合并在⼀起。伙伴系统的另⼀个主要优点是它允许
快速分配和释放内存块,这是实时系统中提供增强性能的重要要求。Linux内核中使⽤伙伴系统
(buddy system)算法以⻚为单位管理内存,进⾏内存分配。旨在减少外部碎⽚
Slab 系统 是另⼀种⽤于分配内核内存的技术。 slab内存分配系统的主要优点是它消除了由于内存分配
和释放⽽产⽣的碎⽚。换句话说,slab分配系统是操作系统中⽤来管理内核内存的⼀种内存分配策
略。基本原理是从伙伴系统中申请⼀整⻚内存,然后划分成多个⼤⼩相等的⼩块内存被 slab 所管理。
旨在减少内部碎⽚
内存碎⽚ & 内存整理
内存碎⽚(Memory Fragmentation)是指内存的使⽤效率降低的现象,它分为两种形式:内部碎⽚
(Internal Fragmentation)和外部碎⽚(External Fragmentation)。内部碎⽚发⽣在内存块被分配
出去后,剩余的未使⽤空间⽆法被其他请求利⽤。外部碎⽚则是指多次内存分配和释放后,内存中留
下许多⼩的、不连续的空闲区域,这些区域太⼩,⽆法满⾜新的内存请求,尽管总的空闲内存量可能
⾜够。
Linux内存对碎⽚化的整理算法主要应⽤了内核的⻚⾯迁移机制,是⼀种将可移动⻚⾯进⾏迁移后腾出
连续物理内存的⽅法。在内存碎⽚整理开始前,会在内存区的头和尾各设置⼀个指针,头指针从头向
尾扫描可移动的⻚,⽽尾指针从尾向头扫描空闲的⻚,当他们相遇时终⽌整理。
核心概念
OOM OOM Killer 机制会根据算法选择一个占用物理内存较高的进程,然后将其杀死,以便释放内存资源,如果物理内存依然不足,OOM Killer 会继续杀死占用物理内存较高的进程,直到释放足够的内存位置。
带宽:又叫频宽,是指在固定的的时间可传输的资料数量,亦即在传输管道中可以传递数据的能力。
内存管理单元(MMU)
位宽 :位宽就是内存或显存一次能传输的数据量。简单地讲就是一次能传递的数据宽度,就像公路的车道宽度,双向四车道、双向六车道,当然车道越多一次能通过的汽车就越大,所以位宽越大,一次性能舆的数据就越多,对显卡来说对性能的提高很明显。
PSW:**包含中断是否开放,处理机执行态等状态的寄存器,叫做处理机状态字 PSW**
PCB: 进程控制块
TCB: 线程控制模块
寄存器分类:CS 代码段寄存器, IP 指令指针寄存器,
PC 程序计数器寄存器, PS描述CPU执行状态,主要包含理机当前运行态,处理及优先级,屏蔽外中断等状态
shell不是操作系统的一部分,而是终端与操作系统的接口
硬件驱动:是一个软件,用于驱动硬件
磁道:每个磁头可以读取一段唤醒区域,就是磁道
柱面: 所有的磁道合并就是一个柱面
上下文切换:由一个程序切换到另一个程序
I/O设备:包括设备控制器和设备本身,
文件:抽象磁盘空间
文件描述符:如果访问文件权限许可,则返回一个小整数,若禁止访问,系统将返回一个错误码
管道:一种需文件,可以链接两个进程,进程A要给进程B 发送数据时,要先把它写在管道上,相当于一个输出文件,之后进程B从上面读入并处理
PID 进程识别符
线程切换要切换栈,否则会弹栈错误
切换栈实质就是切换寄存器
基本输入输出系统 BIOS(Basic Input Output System)
每台计算机上有一块双亲板,上面有一个叫做 基本输入输出系统 BIOS(Basic Input Output System),在BIOS里面有底层I/O软件
设备启动,BIOS启动,检测RAM 的数量和基本硬件的是否已经安装并且响应,
之后通过储存在CMOS存储器中的设备清单决定启动设备
之后操作系统来询问BIOS ,以获得配置信息
多路复用:实现时间和空间的复用
面试
什么是操作系统
操作系统是一种系统软件,是软、硬件资源的控制中心,
操作系统提供一个资源集的抽象,并管理这些硬件资源
主要任务是隐藏硬件,呈现给程序的抽象
记录哪个程序在使用什么资源,对资源请求进行评估代价,并且为不同的程序和用户调解互相冲突的资源冲突
功能 :
- 进程和线程的创建以及管理:创建,撤销,阻塞,唤醒,通信
- 存储管理:内存和外存的分配管理
- 文件管理:读写,创建删除
- 设备管理:完成设备请求和释放,还有启动
- 网络管理:
- 安全管理:用户认证,控制访问,文件加密等
。。
线程:
jvm中线程崩溃不会导致进程崩溃,原因是什么
因为JVM自定义了自己的信号处理函数,拦截了SIGSEGV信号
- 用户态和内核态的转换:
- 系统调用
- 中断
- 异常
- 死锁的解除:
- 立刻结束所有进程
- 结束涉及死锁的所有进程
- 逐个撤销涉及死锁的进程
- 抢占资源
- 内存管理:
- 分配回收
- 地址转换
- 扩充
- 映射
- 优化
- 安全
- inode:索引节点,用于存储文件的元信息,包括文件被分为几块,权限,所有者等,每个文件拥有唯一的inode。inode的数量是固定的
- PCB通过列表的方式组织,相同状态的进程链接在一起
- 进程和线程的对比:
- 进程时资源分配的单位和CPU调度的单位
- 线程只享有部分资源,如寄存器和栈
- 线程可以享受进程的公共资源
- 线程切换开销少:
- 线程不涉及资源管理信息
- 线程释放的资源比进程少
- 同一个进程中的线程切换比进程快,因为线程共享想用的地址空间,在一个进程中的所以后线程都构想一个页表。切换时不需要切换表。
- TCP线程控制块
- 线程分类:
- 用户线程:在用户空间实现的线程,由用户态的线程库来管理
- 内核线程:在内核中实现的线程,由内核管理
- 轻量级线程:在内核中来支持用户线程
- 进程调度:
- 调度时机: 就绪态->运行态,运行态->阻塞态,运行态->结束态
- 调度算法:
- 非抢占式调度算法 : 进程阻塞或者结束时才会调用另一个进程
- 抢占式调度算法:对于一个进程,给予一段时间去运行,时间结束后仍然在运行时,将其挂起,会发生时钟中断
- FCFS 先来先服务
- SJF 最短作业优先
- 高响应比优先调度算法
- 时间片轮转
- 进程之间的通信方式:
- pipe linux中 | 会创建两个子进程共同使用一个pipe
- 消息队列:进程发送消息后就可以继续做工作,另一个进程读取到消息进行处理,消息队列是保存在内核中的消息链表,缺点是:通信不及时,附件大小有限制
- 共享内存:拿出一块虚拟地址空间,将其映射到相同的物理内存中,即可做到消除拷贝过程、
- 缺点:多个进程共同修改共享地址会出现冲突
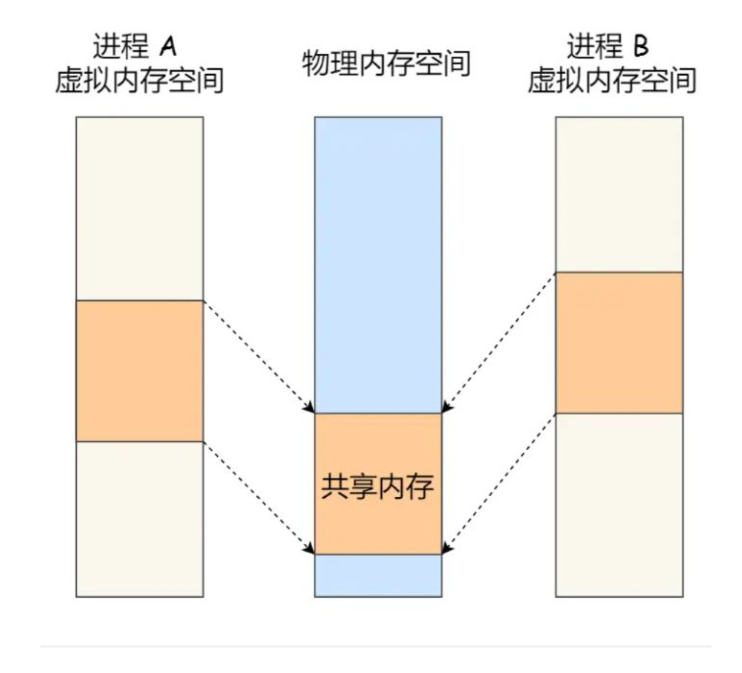
- 信号量:P V 操作 初始量为1时,是互斥操作, 为0时是同步操作
- 信号: 信号 ≠ 信号量,用于处理异常状态下的工作状态
- 锁:
- 忙等待锁(自旋锁):当获取不到锁时,线程会一直等待,不做别的事情,直至得到锁。
- 互斥锁:加锁失败后会释放cpud
DMA
- 用户进程调用 read 方法,向操作系统发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态;
- 操作系统收到请求后,进一步将 I/O 请求发送 DMA,然后让 CPU 执行其他任务;
- DMA 进一步将 I/O 请求发送给磁盘;
- 磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满;
- DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 可以执行其他任务;
- 当 DMA 读取了足够多的数据,就会发送中断信号给 CPU;
- CPU 收到 DMA 的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回;
- 一致哈希算法也用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算,是一个固定的值。
我们可以把一致哈希算法是对 2^32 进行取模运算的结果值组织成一个圆环,就像钟表一样,钟表的圆可以理解成由 60 个点组成的圆,而此处我们把这个圆想象成由 2^32 个点组成的圆,这个圆环被称为哈希环,如下图:

内核
现代操作系统,内核一般会提供 4 个基本能力:
- 管理进程、线程,决定哪个进程、线程使用 CPU,也就是进程调度的能力;
- 管理内存,决定内存的分配和回收,也就是内存管理的能力;
- 管理硬件设备,为进程与硬件设备之间提供通信能力,也就是硬件通信能力;
- 提供系统调用,如果应用程序要运行更高权限运行的服务,那么就需要有系统调用,它是用户程序与操作系统之间的接口。
宏内核 : 内核的所有模块都在内核态
微内核:内核只保留基本能力,进程调度,中断等,剩下的放在用户空间
混合内核,是宏内核和微内核的结合体,内核中抽象出了微内核的概念,也就是内核中会有一个小型的内核,其他模块就在这个基础上搭建,整个内核是个完整的程序;
CPU
寄存器:
- 通用寄存器:存放要运算的数据
- 程序寄存器: 来存储下一条要执行的指令所在的内存第
- 指令寄存器:存放指令本身
总线:
- 地址总线: 指定CPU要操作的内存地址
- 数据总线:读写内存的数据
- 控制总线 : 发送和接受信号,中断,设备复位等,CPU响应也需要控制总线
调度
存储
- 寄存器;
- CPU Cache:使用SRAM 静态存储器,断电丢失数据
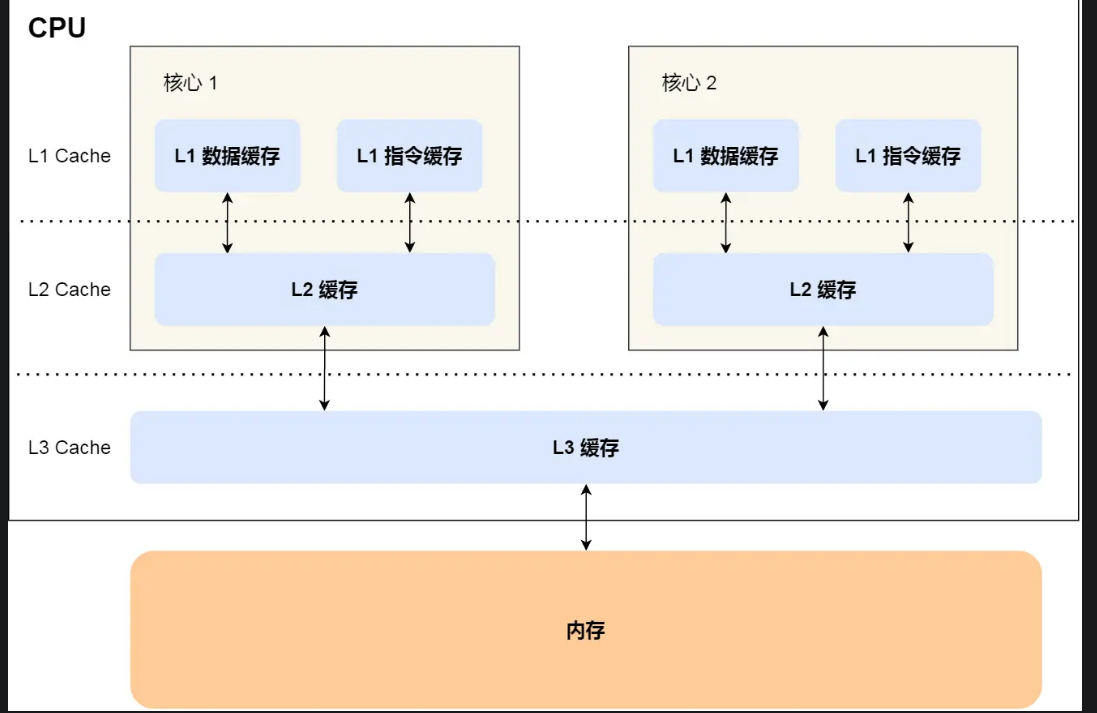
- L1-Cache; L1 高速缓存通常分成指令缓存和数据缓存。速度几乎和寄存器一样快。每个核心都拥有一个
- L2-Cache;比L2离CPU远,大小更大,每一个核心都有
- L3-Cahce;多核心公用
- 写入策略:
- 写直达(_Write Through_)
- 写回(_Write Back_)只有当Cache 中的数据被替换时,写入内存
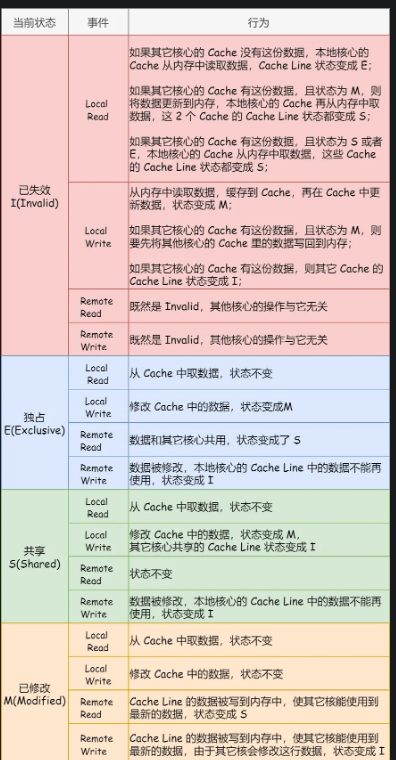
Cache一致性-
- 第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为写传播(_Write Propagation_);使用锁
- 第二点,某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为事务的串行化(_Transaction Serialization_)。
- 使用基于总线嗅探的MESI模型
-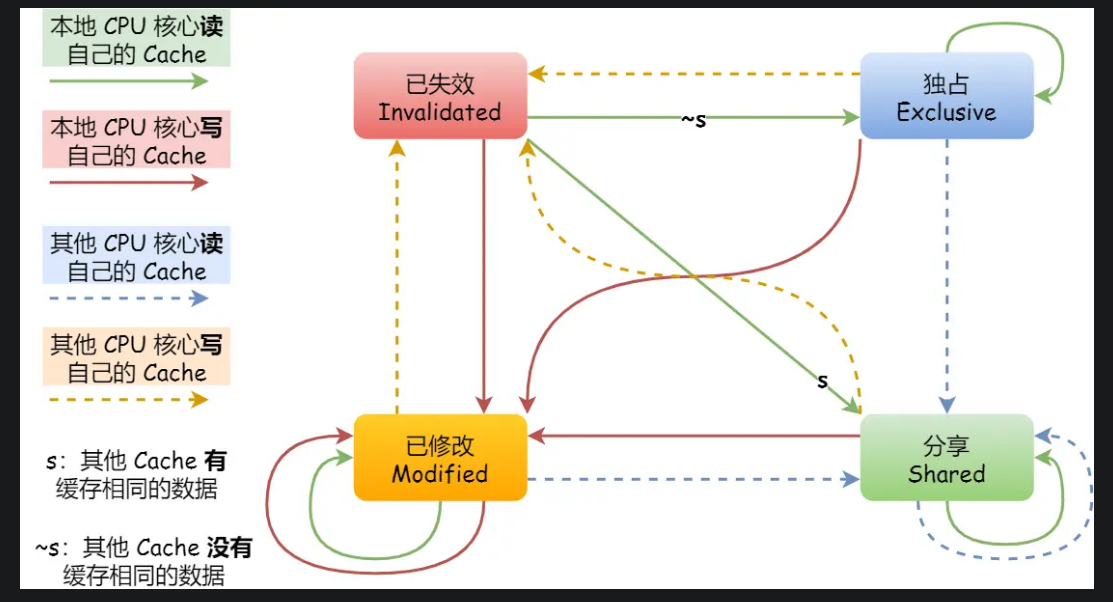
-
- 伪共享: 多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象称为伪共享(_False Sharing_)
- 解决:尽量避免这些数据刚好在同一个Cache Line,将他们变成对齐的情况。
- 应用层面解决: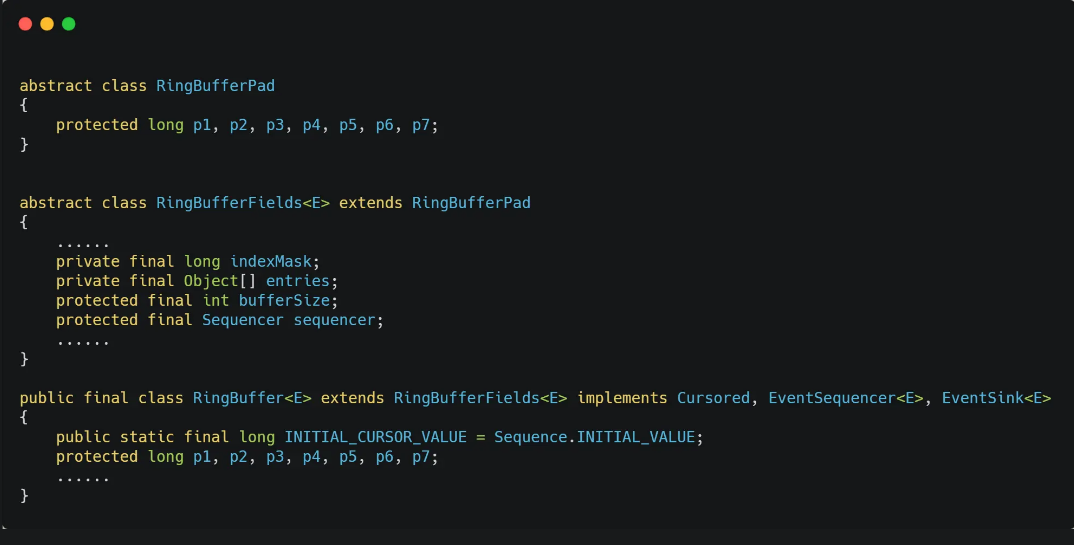
- 内存;DRAM 不断刷新,数据才能被存储起来。
- SSD/HDD 硬盘: SSD:固态硬盘,HDD机械硬盘
伙伴系统:
当可分配内存比所需要内存的二倍还大,那么就将其划分为两个大小为一半一半的空闲分区,重复划分,直到比二倍小就分配给他
分页,分段
分段(Segmentation): 不连续,不等长,相当于是一小段逻辑的程序
- 分段将内存划分为若干段(segments),每个段具有不同的大小和含义。
- 每个段都有自己的基地址和长度。段可以包含代码、数据、堆栈等不同类型的信息。
- 分段允许程序员以逻辑上独立的方式编写程序,并且使得程序的结构更清晰。
- 分段的缺点是会导致内存碎片化,难以管理。
分页(Paging): 连续等长
- 分页将内存划分为固定大小的页面(pages),通常为4KB或者更大。
- 操作系统将进程的虚拟地址空间划分为与页面大小相同的块,称为虚拟页面(virtual pages)。
- 虚拟页面和物理页面(physical pages)之间建立映射关系,操作系统负责管理这些映射。
- 分页的优点是可以更有效地利用内存空间,减少内存碎片化,并且实现了更好的内存保护和共享。
- 解决了外部碎片,但是仍然存在内部碎片
- 页帧:把**物理地址间_**划分为大小相同的基本分配单元
- 页面:把逻辑地址空间也划分为相同大小,基本分配单元
- 页面置换算法:
- 最佳页面置换算法(OPT,Optimal):优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
- 先进先出页面置换算法(FIFO,First In First Out) : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可需求。不过,它的性能并不是很好。
- 最近最久未使用页面置换算法(LRU ,Least Recently Used):LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
LRU算法的弊端:
使用链表:最近使用的数据如果存在,就将其放在头部,如果不存在,就读取数据并放入头部,并删除尾部数据。
预读机制:读入数据时,会把相邻的数据一起读入(空间局限性)
- 缓存失效:被预读的数据没有访问,而且把尾部的数据删除,降低了命中率。 解决:实现两个链表,分别存储热数据和冷数据,分别进行LRU算法。预读部分放入冷数据链表,当真正访问时,放入热数据链表
- 缓存污染:当批量读取数据时,大量数据被放入热数据LRU链表,会导致之前的热点数据失效。解决:提高进入活跃LRU链表的门槛
最少使用页面置换算法(LFU,Least Frequently Used) : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页。
时钟页面置换算法(Clock):可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
局部性原理是指在程序执行过程中,数据和指令的访问存在一定的空间和时间上的局部性特点。其中,时间局部性是指一个数据项或指令在一段时间内被反复使用的特点,空间局部性是指一个数据项或指令在一段时间内与其相邻的数据项或指令被反复使用的特点。
虚拟内存的作用
- 使得进程对云翔内存超过物理内存大小,可以把不经常使用的内存换到物理内存之外
- 每一个进程有自己的页表,所以每个进程的虚拟内存空间时相互独立 的,解决了多进程之间的地址冲突
- 页表中还存在着一些标记属性的bit,如控制一个页的读写权限,为操作系统提供更好的安全性
如果没有空闲的物理内存,那么内核就会开始进行回收内存的工作,回收的方式主要是两种:直接内存回收和后台内存回收。
- 后台内存回收(kswapd):在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
- 直接内存回收(direct reclaim):如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
- OOM 选择一个占用物理内存高的进程,将其杀死,如果不够,重复杀死
- 文件页:脏页将其写回磁盘中,再释放, 干净页直接回收内存
- 匿名页:没有实际载体的文件,将其不常访问写回磁盘
进程
进程控制块 PCB Process Control Block
描述了进程的标识,空间运行状态,资源使用等信息
PCB是进程存在的唯一标志
每个进程都在操作系统中有一个对应的PCB
操作系统建立一个表格用于描述该进程的存在和状态,这个表格就叫做进程控制块
- PCB 使用链表和索引表
- 同一个状态的进程进入一个链表
- 索引表指向PCB
PCB的使用
进程创建:生成该进程的PCB
进程终止:回收它的PCB
进程的状态:
创建状态、运行态、就绪态、阻塞态、结束状态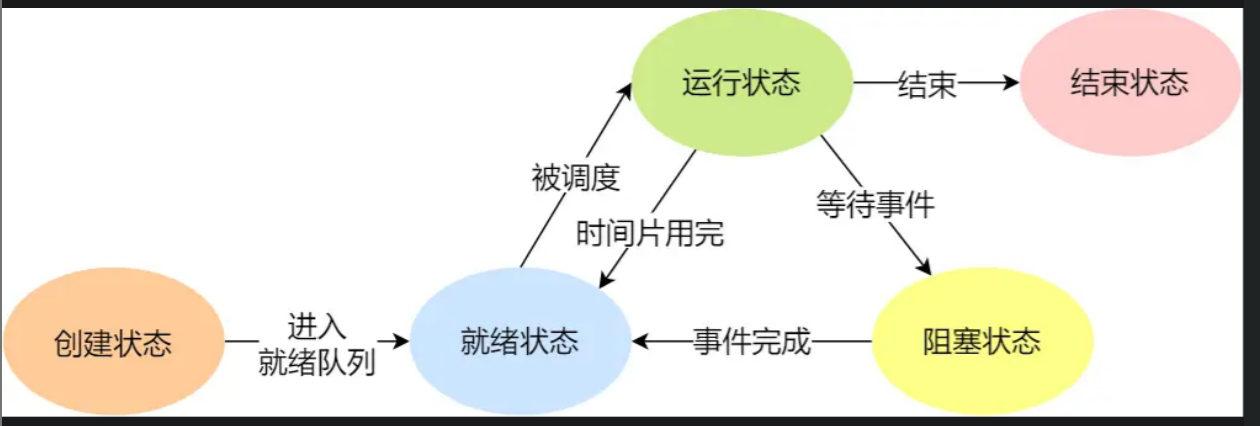
需要一个新的状态,来描述进程没有占用实际的物理内存空间的情况,这个状态就是挂起状态。
- 阻塞挂起状态:进程在外存(硬盘)并等待某个事件的出现;
- 就绪挂起状态:进程在外存(硬盘),但只要进入内存,即刻立刻运行;
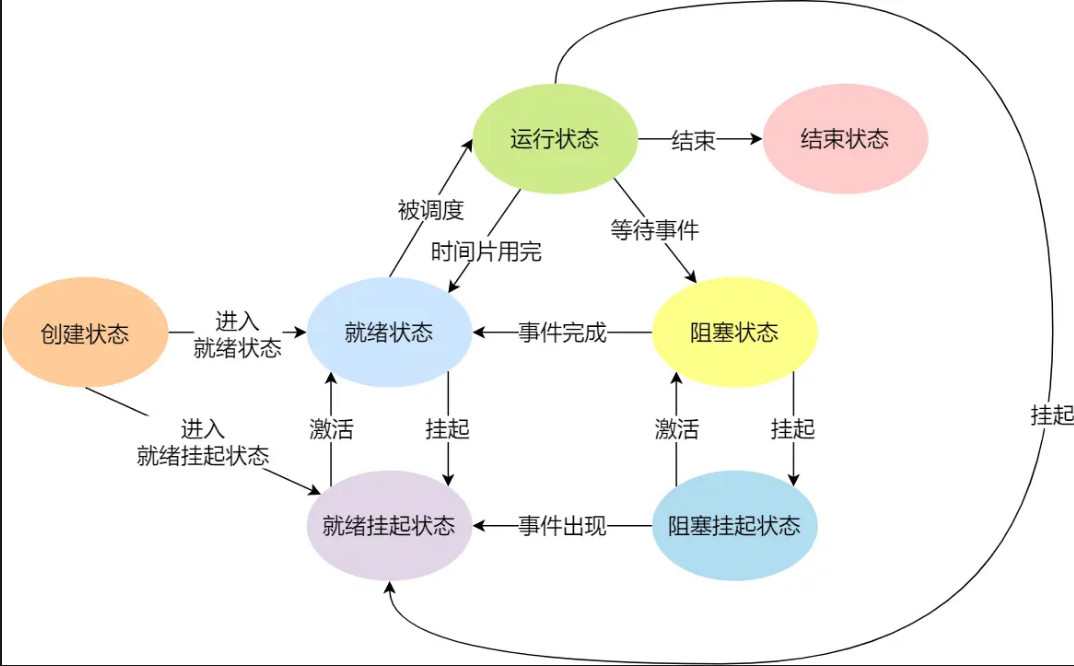
进程创建
主要的事件:系统初始化,正在运行的程序执行了创建进程的系统调用,用户请求创建一个进程,一个批处理作业的初始化
进程执行
进程等待
进程抢占
进程唤醒
进程结束
核心状态:运行状态,就绪状态,等待状态,创建状态,结束状态
进程挂起:
处于挂起状态的进程映射在磁盘上,目的是减少进程占用内存
等待挂起状态等待挂起状态
就绪挂起状态 进程在外存,但只要进入内存即可运行
线程
概念:线程是进程的一部分,描述指令流执行状态。是进程中指令执行流的最小单元,是CPU 调度的基本单位
线程 = 进程 - 共享资源
进程 = 资源+多组线程
- 优点: 1. 一个进程可以有多个线程2.各个线程之间 2.线程之间可以并发。3. 线程之间可以共享地址和文件资源
- 缺点:一个线程崩溃 会导致所属的进程的所有线程崩溃
中断
为了避免由于中断处理程序执行时间过长,而影响正常进程的调度,Linux 将中断处理程序分为上半部和下半部:
- 上半部,对应硬中断,由硬件触发中断,用来快速处理中断;
- 下半部,对应软中断,由内核触发中断,用来异步处理上半部未完成的工作;
优点:
- 提高CPU效率
- 实时处理
- 故障处理
- 实现分时擦欧总
中断的来源是外设,异常是应用程序请求的,属于系统调用
系统调用
每一个系统调用都需要切换堆栈,系统调用是操作系统提供给用户态程序的接口,用于调用内核。
自陷指令: 能够产生异常的指令
并发与并行:
并行:两个进程一起进行,单核处理器中不能够并行,多核才可以
并发:单核处理器合理的处理任务的操作,也就是多线程,并不能同时进行多个任务
进程之间的关系:相互独立和相互制约
制约: 同步和互斥
微服务
Quarkus
- GreetingResourceTest是在jvm中测试
面试常问
CAP理论:任何一个分布式系统都无法做到一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)全部满足。
- C数据一致
- A读写操作必须都能成功
- P分区容错,当分布式系统节点之间出现网络故障导致节点之间无法通信,导致出现了分区 必须要满足的
BASE理论:

- 基于BASE理论的柔性事务,不同于ACID的刚性事务,通过一些新的方案,只要保证最终一致性即可
AP:无需锁定数据,实现最终一致即可
CP:各个子事务执行后不要提交,锁定资源,不允许其他人访问。
SpringCloud
分布式事务:
- 接口幂等性:接口的幂等性是指一次和多次请求某一个资源应该具有同样的副作用。
- XA/两阶段提交:
- 第一阶段:存在一个负责协调各个本地资源管理的事务管理器,事务管理器在第一阶段询问各个资源管理器是否就绪,如果收到的没辙资源的回复都是yes,在在第二阶段提交事务时,任意一个回复no就回滚事务
- 第二阶段:事务管理器根据所有本地资源管理器的返回,通知所有本地资源管理器,步调一致的在所有分支上提交或者回滚事务
- 缺点:
- 同步阻塞:当参与事务者存在占用公共资源的情况,齐总一个占用了资源,其他参与者只能等待资源释放,处于阻塞装填。
- 单点故障:一旦事务管理器故障,整个系统都不可用了
- 数据不一致:在阶段二如果事务管理器只发送了部分commit消息,如果出现网络异常,那么只有部分参与者会提交事务
- 不确定性:当协事务管理器发送 commit 之后,并且此时只有一个参与者收到了 commit,那么当该参与者与事务管理器同时宕机之后,重新选举的事务管理器无法确定该条消息是否提交成功。
- TCC Try-Confirm-Cancel

- Try 阶段:尝试执行,完成所有业务检查(一致性), 预留必须业务资源(准隔离性)
- Confirm 阶段:确认执行真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作满足幂等性。要求具备幂等设计,Confirm 失败后需要进行重试。
- Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源 Cancel 操作满足幂等性 Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致。
- 本地消息表:依靠MQ实现


路由:
- gateway
- 配置
id:路由的唯一标示predicates:路由断言,其实就是匹配条件filters:路由过滤条件,后面讲uri:路由目标地址,lb://代表负载均衡,从注册中心获取目标微服务的实例列表,并且负载均衡选择一个访问。
- 配置
- gateway
Nacos:
- namespace:用于环境隔离

- 分级模型:


- namespace 命名空间
- group分组
- 服务service
- 集群cluster 对应不同的机房/ip
- 实例instance:
- 集群cluster 对应不同的机房/ip
- 服务service
- group分组
- namespace 命名空间
- Nacos挂了能不能正常访问:答案是能,Nacos会把注册的服务的地址推送给他们,他们各自维护一个列表,所以Nacos挂了也不影响调用
- nacos和eureka的区别:
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被删除,非临时实例不会呗删除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos默认使用AP方式,
- nacos读取配置的流程

- 配置热更新:
- namespace:用于环境隔离
OpenFeign:
- 执行过程:

- 获取请求中的serviceId
- 根据serviceId负载均衡,找到一个可用的服务实例
- 利用服务实例ip和port信息重构url
- 向真正的url发起请求
- 执行过程:
负载均衡:
- 使用LoadBalancer实现负载均衡
- 使用Ribbon组件实现:发起远程调用时,ribbon先从注册中心拉取服务地址列表,然后按照一定的路由策略选择一个发起远程调用,
- Ribbon发负载均衡策略: 已经被集成到Eureka-client和Nacos-Discovery中,后来被废弃,使用LoadBalancer了,OpenFeign也整合了LoadBalancer
- 轮询,根据权重选择,随机选择一个可用的,
- 区域敏感策略,以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询(默认)
服务保护
- Sentinel:
- 线程隔离:
- 线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身进行隔离
- 支持主动超时,支持异步调用
- 缺点是线程的额外开销较大
- 使用场景低扇出
- 信号量隔离:不创建线程池而是使用计数器模式,记录业务使用的线程数量,打到信号量上限时,禁止新的请求
- 优点:轻量级,无额外开销
- 缺点:不支持主动超时,不支持异步调用
- 适合高频调用高扇出(一个服务需要调用其他许多服务,那么我们就可以说这个服务有高扇出)
- 线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身进行隔离
- 限流:
- 滑动窗口算法:
- 令牌桶算法:
- 固定速率生成令牌,桶满了就舍弃,每个请求必须向桶中获取令牌才能被处理,没有获得令牌的请求等待或者丢弃
- 一般情况下每秒产生的令牌数量就是QPS上限,但是当前这一秒没有请求进入,下一半秒涌入了超过2N个请求,然后这一秒生成了N个令牌,所以放行了2N个请求,超过了阈值,所以要预留一定的波动空间
- 漏桶算法:请求放入队列中,以固定的速率去取出并处理请求。
- 线程隔离:
- 限流:
- 使用nginx基于漏桶实现限流
- 使用gateway 的令牌桶算法,根据ip或者路径进行限流
- Feign整合sentinel,在配置文件中开启即可
- 熔断:对于超过QPS上限的请求或者延迟较高的请求,对其进行熔断,同时设置一个降级处理逻辑。

- closed关闭装填,放行所有请求,并开始统计异常比例、满请求比例,超过阈值切换到open
- open服务调用被熔断,访问这个被熔断的请求会被拒绝,快速失败,走降级逻辑。持续一段时间之后转到half-open
- half-open 半开模式,放行一次请求,根据执行结果来判断接下来的操作
- 请求成功:切换到closed状态
- 请求失败:切换到open状态
- Sentinel:
分布式事务:
- 使用seata解决分布式事务:
- seata有三个重要角色:

- TC 事务协调者:维护全局和分支失物的状态,协调全局事务的
- TM 事务管理器:定义全局事务的范围,开始全局事务,提交或回滚全局事务
- RM 资源管理器:管理分支事务,与TC交谈以注册分之十五和报告分支事务的状态,并驱动分支事务的提交和回滚
- xa模式:
- RM一阶段工作:
- 注册分支事务到TC
- 执行分支事务sql但不提交
- 报告执行状态到TC
- TC二阶段工作:
- TC检测各分支事务执行状态
- 如果都成功则通知所有RM提交事务
- 如果都失败则通知所有RM回滚事务
- TC检测各分支事务执行状态
- RM二阶段工作:
- 接收TC指令,提交或回滚事务
- 优点:强一致性,没有代码侵入
- 缺点:一阶段需要锁定数据库资源,等待二阶段结束才释放,性能差
- 依赖关系型数据库实现事务
- RM一阶段工作:
- at模式:
- 阶段一RM:

- 注册分支事务,
- 记录undo-log 快照数据
- 执行业务sql并提交
- 报告事务状态
- 二阶段

- 阶段而提交时RM工作:删除undo-log
- 回滚时,RM工作:根据undo-log恢复数据到更新前
- 阶段一RM:
- 两者区别:
- XA一阶段不提交事务,锁定资源,AT一阶段提交事务,不锁定资源
- XA模式伊利数据库实现回滚,AT模式利用数据快照实现数据回滚
- XA模式强一致性,AT模式最终一致
- TCC模式:TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复。需要实现三个方法:

try:资源的检测和预留;confirm:完成资源操作业务;要求try成功confirm一定要能成功。cancel:预留资源释放,可以理解为try的反向操作。- 优点:一阶段完成直接提交事务,释放资源,无需快照,无需依赖数据库事务,可用于关系型数据库
- 缺点:代码侵入严重,软状态,事务最终一致
- seata有三个重要角色:
- 使用seata解决分布式事务:
接口幂等性:
- 使用token+redis实现接口幂等性,第二次请求之后每次请求都会携带之前的token,后台先对redis进行验证,如果存在token则执行业务,同时删除token,如果不存再则直接返回,保证了幂等性,保证了同一个token只处理一次业务
MQ:
- 组成
- producer消息的生产者
- broker 消息的保存
- consumer 消息的消费者
- 选择:
Kafka面试题
- 如何保证消息不丢失:
- producer时,可以使用异步回调发送,如果消息发送失败,我们可以通过回调获取失败后的消息信息,可以重试或者记录日志,也可以后续进行不成
- broker中消息丢失,通过kafka的复制机制来保证消息不丢失,在生产者发送消息的时候,可以设置一个acks的参数位all,这样就会在broker的leader和foller分区都保存确认,只有所有的副本都确认之后才算是成功过发送了消息
- consumer时使用pull,还是push:
- Kafka使用了pull模式,consumer可以自主决定是否批量从broker拉取数据。push为了避免consumer崩溃而采用较低的推送速率,到一次只推送较少的消息造成浪费,pull模式下,consumer可以根据自己的消费能力而去决定如何拉取消息
- 缺点:如果broker没有提供可消费的消息,将导致consumer不断循环中轮询,直到最新消息到达。
- Kafka可以有个参数可以让consumer阻塞知道新消息的到达,或者阻塞直到消息的数量到达某个特定的量就可以批量发送。
- Kafka将Topic分成了若干分区,每个分区同一时间只能被有一个consumer消费,意味着每个分区被消费的消息在日志中的位置仅仅是有一个简单的整数:offset ,consumer可以把offset调成一个较老的值,从而重新消费老消息
- 主从复制:一个topic可以有多个副本
- 主节点将消息写入本地日志,从节点从主节点拉取信息,写入本地日志,之后向主节点发送确认消息,如果主节点收到所有从节点的确认消息,该消息就会被认为是已提交的,主节点会更新自己的高水位,消费者只能消费已提交的消息
- 优点:保证了主节点崩溃消息也不会丢失
- 脑裂问题:
- 只有领导者负责处理生产者和消费者的读写请求,追随者只能从领导者那里复制数据
- Kafka的选举是由ZooKeeper协调的,ZooKeeper可以保证在任何时候只有一个领导者被选举出来
- Zookeeper是如何做到的?
- 当Zookeeper启动或者领导者崩溃时,所有的Zookeeper节点都会进入选举状态
- 投票阶段:每个节点会将自己作为领导者后端,然后发送投票信息给其他节点,当一个节点收到其他节点的投票信息是,如果ZXID更大,也就是收到的消息更,会更新自己的投票信息,并将新的投票信息发送给其他节点
- 确定阶段:当一个节点收到超过半数节点的相同投票信息中,他就认为选举结束,选举出的领导者就是投票信息中的候选节点,然后将结果发送给其他节点。
- 消息重复消费如何解决
- kafka都是按照offset进行标记消费的,消费者默认是自动按期提交已经消费的偏移量,如果出现重复消费的问题,我们需要禁用自动提交offset,改为手动提交,消费成功后报告给broker,为了维护消息的幂等性,我们可以设置唯一主键进行区分,或者是枷锁,数据库的锁或者是Redis的分布式锁都能解决幂等问题。
- 如何保证消息的顺序性:
- 将消息都存储在同一个分区下
- 发送消息时按照相同的业务设置相同的key,默认的分区是通过key的hashcode值来选择分区的,如果hash值一样,分区也是一样的。
- 高可用:
- 集群:多个broker,即使一台宕机,其他可以继续服务
- broker如何实现消息同步?
- 主从同步,Leader Broker接受消息后,将消息写入本地日志,Follower拉取消息,写入本地日志,当所欲的ISR(同步复制保存的follower)都完成,Leader就会向生产者发送确认消息。
- 通过过程中Leader宕机了,该怎么办?
- Kafka回从ISR列表中选择一个新的Leader,ISR列表中的都是已经同步最新数据的副本,当Follower同步完成后,会重新加入到ISR列表中。
- broker如何实现消息同步?
- 数据清洗:
- 日志清洗:
- 根据消息保留时间,超过指定时间触发清洗,默认是168小时
- 根据topic存储的数据大小,大于一定法制,开始删除最久的消息,默认关闭。
- 日志清洗:
- 高性能设计:
- 消息分区:不受单台服务器限制,处理更多数据
- 顺序读写:顺序读写,提高读写效率
- 页缓存:磁盘中的数据缓存到内存,把磁盘的访问变为对内存的访问
- 零拷贝:减少上下文切换及数据拷贝
- 消息压缩:减少磁盘IO和网络IO
- 分批发送:分批发送,将消息打包批量发送,减少网络开销
- 集群:多个broker,即使一台宕机,其他可以继续服务
SpringCloud
注册中心
- 方便更改微服务的ip和 端口号
- 如果存在多个服务,可以配置负载均衡
- 方便维护
服务注册中心:实现微服务之间的动态注册与发现
consul
功能:
- 服务发现 支持 http和dns
- 健康监测
- KV存储 配置
- 多数据中心
- 可视化Web界面
在main方法上使用 @EnableDiscoveryClient
controller 层上public static final String PaymentSrv_URL = "http://cloud-payment-service";//服务注册中心上的微服务名称consul agent -dev 进入开发者模式 localhost:8500<!--SpringCloud consul discovery --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-consul-discovery</artifactId> </dependency>
RestTemplate提供了多种便捷访问远程Http服务的方法,####Spring Cloud Consul for Service Discovery spring: cloud: # 服务注册 consul: # consul注册中心 host: localhost # consul地址 port: 8500 # consul端口 discovery: # 服务发现 service-name: ${spring.application.name} # 服务名称
是一种简单便捷的访问restful服务模板类,是Spring提供的用于访问Rest服务的客户端模板工具集
applicaiton.yml是用户级的资源配置项
bootstrap.yml是系统级的,优先级更加高
Spring Cloud会创建一个“Bootstrap Context”,作为Spring应用的Application Context的父上下文。初始化的时候,Bootstrap Context负责从外部源加载配置属性并解析配置。这两个上下文共享一个从外部获取的Environment。
Bootstrap属性有高优先级,默认情况下,它们不会被本地配置覆盖。 Bootstrap context和Application Context有着不同的约定,所以新增了一个bootstrap.yml文件,保证Bootstrap Context和Application Context配置的分离。
spring:
application:
name: cloud-payment-service
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
service-name: ${spring.application.name}
config:
profile-separator: '-' # default value is ",",we update '-'
format: YAML
# config/cloud-payment-service/data
# /cloud-payment-service-dev/data
# /cloud-payment-service-prod/data application.yml文件改为bootstrap.yml,这是很关键的或者两者共存
因为bootstrap.yml是比application.yml先加载的。bootstrap.yml优先级高于application.yml
- consul kv写法
- config/配置文件/data 里面写配置
- 动态刷新:在main上写 : @RefreshScope
问题: 重启consul之后,配置丢失,如何持久化配置?
负载均衡
- 客户端负载和服务器负载
loadbalancer本地负载均衡客户端 VS Nginx服务端负载均衡区别
Nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由nginx实现转发请求,即负载均衡是由服务端实现的。
loadbalancer本地负载均衡,在调用微服务接口时候,会在注册中心上获取注册信息服务列表之后缓存到JVM本地,从而在本地实现RPC远程服务调用技术。
- LoadBalancer 在工作时分成两步:
第一步,先选择ConsulServer从服务端查询并拉取服务列表,知道了它有多个服务(上图3个服务),这3个实现是完全一样的,
默认轮询调用谁都可以正常执行。类似生活中求医挂号,某个科室今日出诊的全部医生,客户端你自己选一个。
第二步,按照指定的负载均衡策略从server取到的服务注册列表中由客户端自己选择一个地址,所以LoadBalancer是一个客户端的负载均衡器。
<!--loadbalancer-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>访问时即可在多个服务器中切换
均衡算法默认为轮询:
可以切换为随机算法:
修改RestTemplateConfig:
@Configuration
@LoadBalancerClient(
//下面的value值大小写一定要和consul里面的名字一样,必须一样
value = "cloud-payment-service",configuration = RestTemplateConfig.class)
public class RestTemplateConfig
{
@Bean
@LoadBalanced //使用@LoadBalanced注解赋予RestTemplate负载均衡的能力
public RestTemplate restTemplate(){
return new RestTemplate();
}
@Bean
ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);
}
}OpenFeign
Feign是一个声明性web服务客户端。它使编写web服务客户端变得更容易。使用Feign创建一个接口并对其进行注释。它具有可插入的注释支持,包括Feign注释和JAX-RS注释。Feign还支持可插拔编码器和解码器。Spring Cloud添加了对Spring MVC注释的支持,以及对使用Spring Web中默认使用的HttpMessageConverter的支持。Spring Cloud集成了Eureka、Spring Cloud CircuitBreaker以及Spring Cloud LoadBalancer,以便在使用Feign时提供负载平衡的http客户端。
OpenFeign能干什么
前面在使用SpringCloud LoadBalancer+RestTemplate时,利用RestTemplate对http请求的封装处理形成了一套模版化的调用方法。**但是在实际开发中,**
由于对服务依赖的调用可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行封装一些客户端类来包装这些依赖服务的调用。所以,OpenFeign在此基础上做了进一步封装,由他来帮助我们定义和实现依赖服务接口的定义。在OpenFeign的实现下,我们只需创建一个接口并使用注解的方式来配置它(在一个微服务接口上面标注一个**_@FeignClient_**注解即可),即可完成对服务提供方的接口绑定,统一对外暴露可以被调用的接口方法,大大简化和降低了调用客户端的开发量,也即由服务提供者给出调用接口清单,消费者直接通过OpenFeign调用即可,O(∩_∩)O。
OpenFeign同时还集成SpringCloud LoadBalancer
可以在使用OpenFeign时提供Http客户端的负载均衡,也可以集成阿里巴巴Sentinel来提供熔断、降级等功能。而与SpringCloud LoadBalancer不同的是,通过OpenFeign只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用。
- 引入依赖:
<!--openfeign--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency> - 配置文件
main函数上使用server: port: 80 spring: application: name: cloud-consumer-openfeign-order ####Spring Cloud Consul for Service Discovery cloud: consul: host: localhost port: 8500 discovery: prefer-ip-address: true #优先使用服务ip进行注册 service-name: ${spring.application.name}
api接口上使用:@EnableDiscoveryClient //该注解用于向使用consul为注册中心时注册服务 @EnableFeignClients//启用feign客户端,定义服务+绑定接口,以声明式的方法优雅而简单的实现服务调用
@FeignClient(value = “xxx”) - 超时控制
sspring: cloud: openfeign: client: config: # default 设置的全局超时时间,指定服务名称可以设置单个服务的超时时间 default: #连接超时时间 connectTimeout: 4000 #读取超时时间 readTimeout: 4000 # 为serviceC这个服务单独配置超时时间,单个配置的超时时间将会覆盖全局配置 serviceC: #连接超时时间 connectTimeout: 2000 #读取超时时间 readTimeout: 2000
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”.
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
所以,
通常当你发现一个模块下的某个实例失败后,这时候这个模块依然还会接收流量,然后这个有问题的模块还调用了其他的模块,这样就会发生级联故障,或者叫雪崩。
CircuitBreaker 断路器
配置参考
断路器的状态:
- CLOSED
- OPEN
- HALF_OPEN 半开

pox<!--resilience4j-circuitbreaker--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId> </dependency> <!-- 由于断路保护等需要AOP实现,所以必须导入AOP包 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency>
分布式链路追踪
原因:
ZipKin概述
Zipkin是一种分布式链路跟踪系统图形化的工具,Zipkin 是 Twitter 开源的分布式跟踪系统,能够收集微服务运行过程中的实时调用链路信息,并能够将这些调用链路信息展示到Web图形化界面上供开发人员分析,开发人员能够从ZipKin中分析出调用链路中的性能瓶颈,识别出存在问题的应用程序,进而定位问题和解决问题
运行: java -jar zipkin-server-3.0.0-rc0-exec.jar
网关

执行流程:
- 路由判断:用户端的请求到达网关之后,根据Gateway Handler Mapping 处理,会进行断言判断
- 路由过滤:很多Handler 组成的Fileter Chain
- 服务处理:后端服务会对请求进行处理
- 响应过滤:返回给-Gateway的过滤器会再次进行处理,逻辑上可以乘坐Post-Filters
- 响应返回:响应经过过处理之后,返回给客户端
- 作用
- 反向代理
- 鉴权
- 流量控制
- 熔断
- 日志监控
Spring Cloud Gateway如何实现动态路由
可以使用Nacos作为注册中心去动态更改
配置的路由断言类型
Gateway过滤器的类型
- Pre类型:在请求被转发到微服务之前及逆行拦截和修改
- Post : 微服务处理请求之后,返回响应给网关,网关可以再次进行处理,例如修改相应内容或者响应头,日志输出,流量监控
或者 - GatewayFilter:局部过滤器,应用在单个路由或者一组路由上的过滤器
- GlobalFilter:全局过滤器
pom
yml<!--gateway--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency>server: port: 9527 spring: application: name: cloud-gateway #以微服务注册进consul或nacos服务列表内 cloud: consul: #配置consul地址 host: localhost port: 8500 discovery: prefer-ip-address: true service-name: ${spring.application.name} gateway: routes: - id: pay_routh1 #pay_routh1 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名 uri: http://localhost:8001 #匹配后提供服务的路由地址 predicates: - Path=/pay/gateway/get/** # 断言,路径相匹配的进行路由id: pay_routh2 #pay_routh2 #路由的ID(类似mysql主键ID),没有固定规则但要求唯一,建议配合服务名 uri: http://localhost:8001 #匹配后提供服务的路由地址 predicates: - Path=/pay/gateway/info/** # 断言,路径相匹配的进行路由
SpringCloud

- 功能

- 组件

服务注册 Nacos == consul
注意是根据ID来区分的不是根据名字来区分命名空间的,所以ID要填自己想填的

命令行
startup.cmd -m standalone服务提供者
pom:<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>yml
server: port: 9001 spring: application: name: nacos-payment-provider cloud: nacos: discovery: server-addr: localhost:8848 #配置Nacos地址main函数上使用@EnableDiscoveryClient
业务类示范
消费者
pom<!--nacos-discovery--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!--loadbalancer--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency>xml
server: port: 83 spring: application: name: nacos-order-consumer cloud: nacos: discovery: server-addr: localhost:8848 #消费者将要去访问的微服务名称(nacos微服务提供者叫什么你写什么) service-url: nacos-user-service: http://nacos-payment-providermain上也使用@EnableDiscoveryClient
restTemplate配置
ackage com.atguigu.cloud.config;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
/**
* @auther zzyy
* @create 2023-11-23 17:20
*/
@Configuration
public class RestTemplateConfig
{
@Bean
@LoadBalanced //赋予RestTemplate负载均衡的能力
public RestTemplate restTemplate()
{
return new RestTemplate();
}
}- Nacos作为配置中心,进行动态配置
导入pom
为什么进行两个配置? bootstrap和application?<!--bootstrap--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency> <!--nacos-config--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency>
Nacos同Consul一样,在项目初始化时,要保证先从配置中心进行配置拉取,
拉取配置之后,才能保证项目的正常启动,为了满足动态刷新和全局广播通知
springboot中配置文件的加载是存在优先级顺序的,bootstrap优先级高于application
bootstrap
application# nacos配置 spring: application: name: nacos-config-client cloud: nacos: discovery: server-addr: localhost:8848 #Nacos服务注册中心地址 config: server-addr: localhost:8848 #Nacos作为配置中心地址 file-extension: yaml #指定yaml格式的配置 # nacos端配置文件DataId的命名规则是: # ${spring.application.name}-${spring.profile.active}.${spring.cloud.nacos.config.file-extension} # 本案例的DataID是:nacos-config-client-dev.yaml
controller层上使用@RefreshScope //在控制器类加入@RefreshScope注解使当前类下的配置支持Nacos的动态刷新功能。server: port: 3377 spring: profiles: active: dev # 表示开发环境 #active: prod # 表示生产环境 #active: test # 表示测试环境
问题1:
实际开发中,通常一个系统会准备
dev开发环境
test测试环境
prod生产环境。
如何保证指定环境启动时服务能正确读取到Nacos上相应环境的配置文件呢?
问题2:
一个大型分布式微服务系统会有很多微服务子项目,
每个微服务项目又都会有相应的开发环境、测试环境、预发环境、正式环境……
那怎么对这些微服务配置进行分组和命名空间管理呢?

Sentinel 等价于 Circuit Breaker 自己去官网看






pom
<!--SpringCloud alibaba sentinel -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>yml
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: localhost:8848 #Nacos服务注册中心地址
sentinel:
transport:
dashboard: localhost:8080 #配置Sentinel dashboard控制台服务地址
port: 8719 #默认8719端口,假如被占用会自动从8719开始依次+1扫描,直至找到未被占用的端口
- 流控规则

- 熔断降级
Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,
让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。、
如何处理分布式 事务
Seata

去官网看
面试题:



分布式详细
[分布式ID](### 分布式ID https://javaguide.cn/distributed-system/distributed-id-design.html)
需求:
- 全局唯一
- 高可用
- 高性能
- 安全
- 方便易用
解决方式:
推荐使用雪花算法
分布式锁
Redis实现
setnx
Redisson
可重入锁
一个线程中可以多次获取同一把锁,例如,方法又调用了另一个需要相同锁的方法。
可以使用红锁
ZooKeeper
https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.html
Redis的性能更好,但是Zookeeper的可靠性更高。
推荐使用 Curator 来实现 ZooKeeper 分布式锁。
python and web or ai
基础语法
web
pip install beautifulsoup4 Scrapy框架
项目结构:
scrapy.cfg 配置文件
setting.py 定义爬虫的相关配置信息
items.py 定义待爬页面数据的结构
pipelines.py 定义存储爬到的数据的方式
middlewares.py 定义随机切换ip等逻辑
Spiders 在目录里,存放爬虫代码scrapy startproject projectName 新建一个项目
1.在items模块中定义待爬取内容的数据结构
2.在spiders文件中
scrapy genspider name xxx.com 新建一个爬虫文件
3.pipelines中定义存储方式
4.settings中加入
ITEM_PIPELINES = {
"cnblogPrj.pipelines.CnblogprjPipeline": 300,
}
# 禁用cookies
COOKIES_ENABLED = Falsex = float(input() )
y = float(input())
print("{:.3f} + {:.3f} = {:.3f}".format(x, y, x + y))
print("{:.3f} - {:.3f} = {:.3f}" .format (x, y, x - y))
print("{:.3f} * {:.3f} = {:.3f}" .format (x, y, x * y))
print("{:.3f} / {:.3f} = {:.3f}" .format (x, y, x / y))